micahlerner.com
Defcon: Preventing Overload with Graceful Feature Degradation
Published July 23, 2023
Found something wrong? Submit a pull request!
Defcon: Preventing Overload with Graceful Feature Degradation
This is one in a series of papers I’m reading from OSDI and Usenix ATC. These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
What is the research?
Severe outages can occur due to system overloadDiscussion of managing load from the SRE book here. , impacting users who rely on a product, and potentially damaging underlying hardwareDamage to hardware can show up as fail-slow situations, where performance degrades overtime. This is also discussed in a previous paper review on Perseus: A Fail-Slow Detection Framework for Cloud Storage Systems . It can also be difficult to recover from outages involving overloaded system due to additional problems this type of outages cause - in particular, cascading failures. There are many potential root-causes to a system entering an overloaded state, including seasonal traffic spikes, performance regressions consuming excess capacityThis situation can lead to metastable failures, as discussed in a previous paper review. , or subtle software bugs. As such, limiting the damage caused by overload conditions is a complicated problem.
To prevent overload from impacting its products, Meta developed a system called Defcon. Defcon provides a set of abstractions that allows incident responders to increase available capacity by turning off features, an idea called graceful feature degradation. By dividing product features into different levels of business criticality, Defcon also allows oncallers to take a variety actions depending on the severity of an ongoing incident.
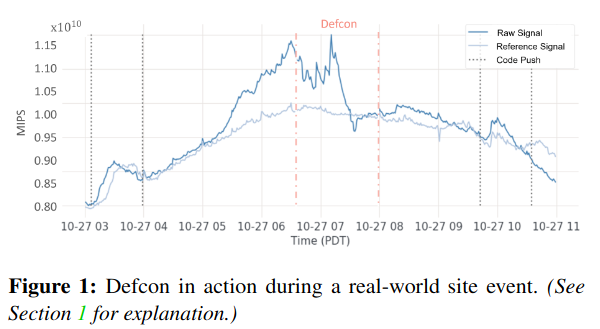
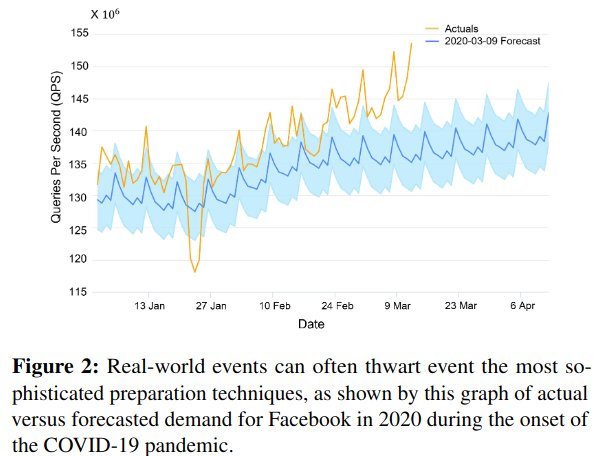
The Defcon paper describes Meta’s design, implementation, and experience deploying this system at scale across many products (including Facebook, Messenger, Instagram, and Whatsapp) along with lessons from usage during production incidents.
Background and Motivation
The authors of Defcon describe several alternatives they considered when deciding how to mitigate the risk of system overload. Each of the options is evaluated on the amount of additional resources that the approach would consume during an incident, the amount of engineering effort required to implement, and the potential impact to users.

Given that serious overload events happen on a recurring basis (at least once a year), the authors decided to invest engineering resources in an engineering-intensive effort capable of limiting user impact.
How does the system work?
The core abstraction in Defcon is the knob, which represents for each feature: a unique name, whether a feature is turned on or not, the oncall rotation responsible, and a “level” corresponding to business-criticality.


After a feature is defined using this configuration, servers or applications (for example, in Web or iOS devices) import the knob into code and implement code paths that handle cases when the knob is turned off - for example, short-circuiting expensive logic.

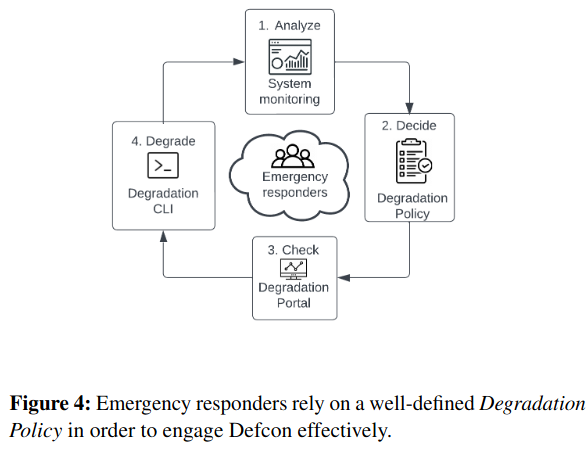
During testing and incident response, operators change a knob’s state via a command-line or user interface, and Defcon handles replicating this state to impacted consumers (like servers and mobile applications). Knob state is also stored in a database.
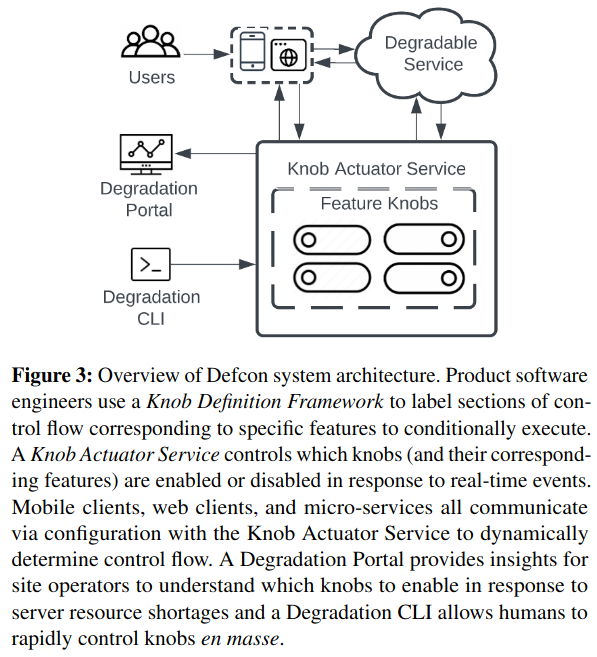
Defcon’s Knob Actuator Service propagates state changes for two types of knobs: server-side knobs and client-side knobs:
Server-side knobs are implemented in binaries running on the servers in data centers. The advantage of server-side knobs is that we can adjust the knobs’ state in seconds without any propagation delays.
Client-side knobs are implemented in client code running on phones, tablets, wearables, and so on. The advantage of client-side knobs is that they have the capability to reduce network load by stopping requests sent to the server along side reducing server load due to the request.
Client-side knobs (like those in an iOS application) are slightly more complex to update. Under normal conditions, they change via a push (called Silent Push Notification (SPN)) or routine pull (Mobile Configuration Pull) mechanism. To handle extenuating circumstances (like lower latency response to severe outages), Defcon can also instruct clients to pull a broader set of configuration stored in a specific server-location using a process called Emergency Mobile ConfigurationUnder normal operating conditions, a full reset isn’t used because it has the tradeoff of using more resources (in particular networking), which is unfriendly to user mobile plans and device batteries. .
Knobs are, “grouped into three categories: (1) By service name, (2) by product name, and (3) by feature name (such as “search,” “video,” “feed,” and so on)” to simplify testing during development and post-release. Testing occurs through small scale A/B tests (where one “experiment arm” of users experience feature degradation, and the “control” arm does not) and during larger exercises that ensure the Defcon system is working (described later in the paper). These tests also have the side effect of generating data on what capacity a feature or product is using, which serves as an input to capacity planning.
During incidents, oncallers can also use the output of these tests to understand what the potential implications are of turning off different knobs. The
How is the research evaluated?
The paper uses three main types of datasets to quantify Defcon’s changes:
- Real-time Monitoring System (RMS) and Resource Utilization Metric (RUM), which aim to measure utilization of Meta infrastructure. The specifics of which one to use depends on the experiment, as discussed below.
- Transitive Resource Utilization (TRU), which aims to measure the downstream utilization that a service has of shared Meta systems (like its graph infrastructure described in my previous paper review on TAO: Facebook’s Distributed Data Store for the Social Graph).
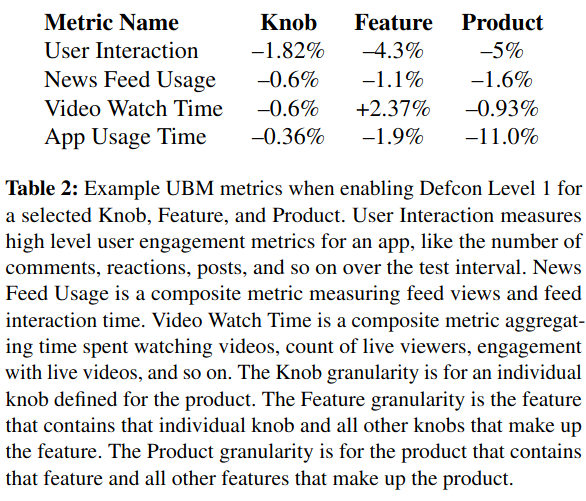
- User Behavior Measurement (UBM), which tracks how changing a knob’s state impacts business metrics like “Video Watch Time”.
The first evaluation of Defcon’s impact is at the Product-level. By turning off progressively more business-critical functionality, the system makes greater impact on Meta’s resource usageRepresented with mega-instructions per second (MIPS), a normalized resource representation corresponding to compute. . Entirely turning off critical features (aka “Defcon Level 1”), saves a large amount of capacity, but also significantly impacts critical business metrics.
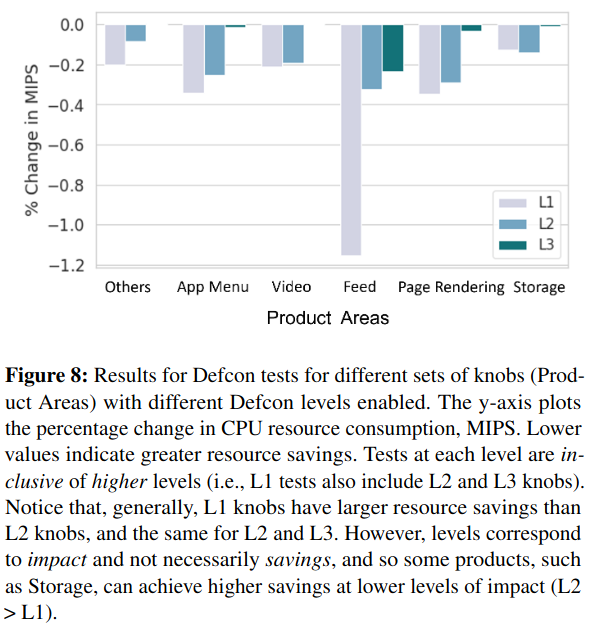
Defcon is next evaluated for its ability to temporarily decrease capacity required of shared infrastructure. As discussed in a previous paper review of Scaling Memcache at Facebook, Meta uses Memcache extensively. By turning off optional features, oncallers are able to decrease load on this type of core system.
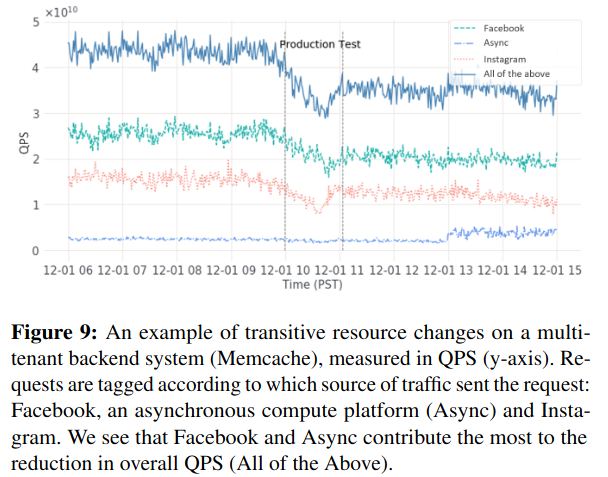
Next, the research describes how Meta can decrease capacity requirements by turning off knobs in upstream systems with dependencies on other Meta products. For example, turning off Instagram-level knobs decreases load on Facebook, which ultimately depends on TAO, Meta’s graph service. Testing knobs outside of incident response surfaces resource requirements from these interdependencies.
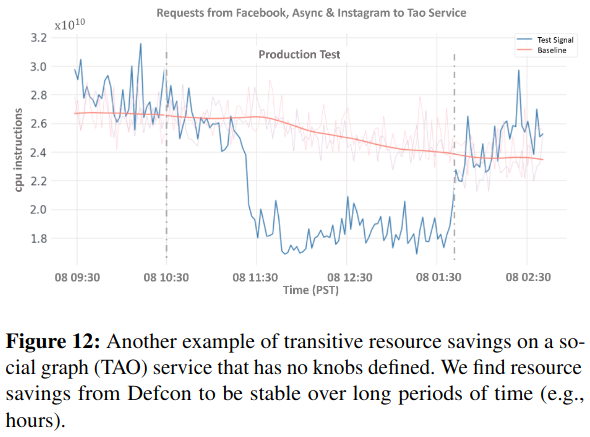
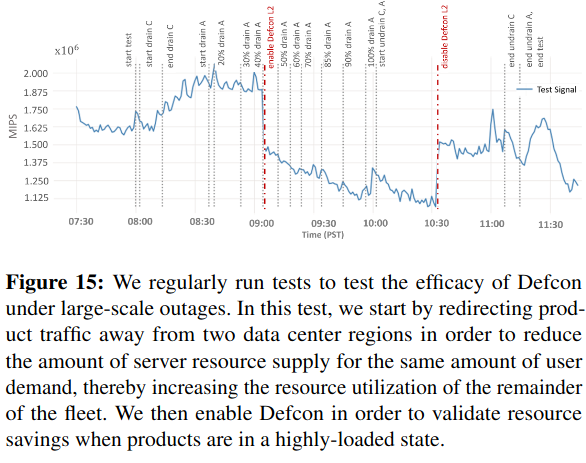
The Defcon paper describes a protocol for forcing Meta systems into overload conditions, and testing the impact of turning progressively more business-critical features off. By ramping user traffic to a datacenter, these experiments place increasing load on infrastructure - turning knobs off then alleviates load.
Conclusion
The Defcon paper describes a framework deployed at scale in Meta for disabling features in order to mitigate overload conditions. To reach this state, the authors needed to solve technical challenges of building the system and to collaborate with product teams to define feature criticality - in some ways, the latter seems even more difficult. The paper also mentions issues with maintainability of knobs. On this front, it seems like future work could automate the process of ensuring that knobs cover features inside of deployed code. Lastly, I’m looking forward to learning more about Defon’s integration with other recently published Meta research, like the company’s capacity management system.