micahlerner.com
Scaling Memcache at Facebook
Published May 31, 2021
Found something wrong? Submit a pull request!
Discussion on Hacker News
These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
Scaling Memcache at Facebook Nishtala, et al. NSDI 2013
After reading about Noria, I decided to read Facebook’s implementation of a caching system at scale. This paper was enjoyable to read for a few reasons - it not only points out the tradeoffs made in designing such a system, but also the learnings associated with operating it.
What are the paper’s contributions?
The paper discusses how Facebook built a distributed key value A distributed key value store often allows for gettting, setting, and deleting values from a datastore with multiple copies (although specifics of how many and when data is copied are use-case specific, as the paper talks about!). store on top of memcachedIn the process of writing this, I learned that memcached was originally written in Perl! in order to cache a wide variety of data, including database query results and data for backend services.
On its own, memcached is a basic key value store, yet Facebook viewed memcached’s simplicity as a positive rather than a negative. The system’s simplicity meant that Facebook was able to easily tailor the application to its use case of serving millions of user requests every second, as well as adding more advanced functionality as needed.
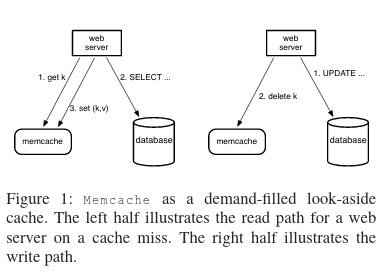
Of this paper’s contributions, the “how?” of scaling such a system is significant - their distributed key-value store needed to be scaled from a single cluster (in one data center), to many clusters in a single region, and finally to many regions with many clusters each. The paper also includes rationales for design decisions, along with acknowledgements of potential edge cases (and often times reasoning for why an unresolved edge case does not have an impact on the running system).
So, how did Facebook approach scaling memcache?
In order to understand how Facebook scaled memcache, it is helpful to frame the scaling in three areas: within a cluster, within a region (a region may have many clusters), and between many regions (where each region has many clusters).
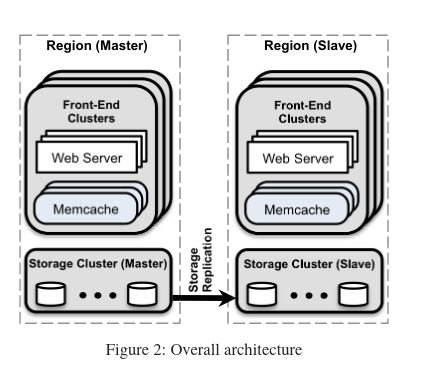
Scaling within a cluster
The primary concern for scaling memcache within a cluster was reducing latency and loadLatency meaning response time to user request and load meaning the computational load placed on the backing datastore . Additionally, there is some discussion of increasing the reliability of the system through automatic failure recovery.
Reducing Latency
To reduce latency, Facebook engineers implemented three main features: request parallelization, the mcrouter, and congestion control measures.
First, they noticed that memcache requests were being performed serially, so they modified their web server code to increase request parallelization. This improvement meant that unrelated data could be fetched in parallel.The paper does not go into great depth into how the client determines which memcache requests can be parallelized, only adding that a DAG of request dependencies is used. .
An additional measure to reduce latency was the addition of a proxy (mcrouter) in between the web servers and the actual backing memcache servers in order to distribute load and route requests. This mcrouter exposes the same interface as the memcache server and maintains TCP connections with threads on the web server. The web server sends memcache requests that mutate state (set, delete) to the mcrouter over TCP (given the built-in reliability of TCP), but sends all other memcache requests (like get requests) directly to the backing memcache servers over UDP. This decision to use TCP versus UDP is based on the fact that maintaining TCP connections from all web server threads to all memcached servers (of which there are many) would incur significant cost. For a quick refresher on this, Computer Networking: A Top-Down Approach is very good.
To limit congestion on the network (more congestion = more latency), memcache clients are prohibited from issuing unbounded requests. Instead, a sliding window was added to memcache clients that prohibits more than n requests to be in-flight at once (where n is a configurable setting). If the in-flight request limit is reached by a memcache client, they are put into a request queue. Based on the data in the paper, it turned out that this idea is great for reducing contention, and didn’t impact clients that are operating normally. This insight is a great instance of using behavior in production to guide implementation!
Reducing Load
To reduce load on the backing data store, three features were added: leases, memcache pools, and replication within pools.
Leases were implemented to address two main problems, stale sets and thundering herdsA stale set is when a client sets a value with an old value, and a thundering herd is when a specific key undergoes heavy read or write volume. , and are values given out to clients for a specific key. To solve stale sets, the backend server checks what is the most recent lease given out for a specific key, and will block writes from an old copy of the key. To solve thundering herds (for example, many clients trying to fetch data for the same key, but the key is not in the cache), leases are given out at a constant rate. If a client requests data for a key, but a lease for the key has already been given out, the lease request will fail and the client will need to retry. Meanwhile, the owner of the lease will cause the key to be filled from cache, and the client will succeed on retry. Crisis avoided.
Another optimization occurred when Facebook realized that different datasets stored in memcached have different churn rates - for example, some keys in the cache change frequently, while others remain the same for the long time. If a long-lived key is in a cache with items that change frequently, based on an LRU caching policy long-lived the key is likely to be evicted. To fix this, keys with different churn rates can be separated (and the infrastructure for the different key sets can be sized appropriately).
For small datasets (the dataset can fit in one or two memcache servers) that have high request rates, the data is replicated. Replicating the dataset across multiple servers means that the load can be spread out, limiting the chance of a bottleneck at any given server.
Automatic failure recovery
Facebook has large computing clusters and likely has many memcached servers failing every day because computers break in weird ways. To prevent these failures from cascading, Facebook built a system called Gutter. Gutter kicks in if a memcache client doesn’t get a response for a key. In this event, the data is fetched from the database and placed on the Gutter server, essentially diverting that key away from the main cluster. This approach is explicitly chosen over the alternative of redistributing keys from a failed machine across the remaining healthy machines (which the paper argues is a more dangerous alternative that could overload the healthy servers).
Scaling among clusters within a region
Within a region, the paper highlights that the biggest concern is data-replication between multiple copies of the cache. To solve this problem space, Facebook implemented three features: an invalidation daemon (a.k.a McSqueal) that replicates the cache invalidations across all cache copies in region, a regional pool of memcache servers that all clusters in a region share for certain types of data, and a mechanism for preparing clusters before they come online.
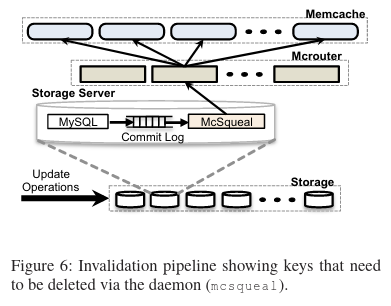
The invalidation daemon used to replicate cache-invalidations among clusters reads the MySQL commit log, transforming deletes into the impacted MySQL keys that need to be deleted from the cache, and eventually batching the deletes in a message to the mcrouter that sits in front of the memcache servers. Personal opinion: using the MySQL commit log as a stream that daemons operate on is a great design pattern (and was likely ahead of its time when the paper came out)!
The next section of the paper talks about regional pools, which are a strategy to maintain single copies of data in order to limit data usage and inter-cluster traffic from replication. Normally datasets with smaller values and lower traffic are placed here, although the paper waves the hands a little bit about a manual heuristic that figures out which keys would be good candidates for regional pools.
The last topic related to scaling among clusters within a region is the cluster warmup process. A cluster that just started up may have access to the database, but completely empty memcache servers. To limit the cache misses hitting the database, the cold cluster will forward requests to a cluster that already has a satisfactory memcache hit-rate.
Scaling among regions
Facebook uses many regions around the world to get computers closer to their customers (which in turn results in lower latency) and reduce the risk that abnormal events like a fire or power outage bring their whole site down. Making a cache among these many regions is certainly difficult, and the paper discusses how consistency is their primary concern at this level.
At the time of the paper’s publication, Facebook relied on MySQL’s replication to keep databases up to date between regions. One region would be the master, while the rest would be the slaves I use the terms master/slave from the literature, rather than choosing them myself. . Given the huge amount of data that Facebook has, they were willing to settle for eventual consistency (the system will tolerate out of sync data if the slave regions fall behind the master region).
Tolerating replication lag means that there are a few situations that need to be thought through.
What happens if a MySQL delete happens in a master region?
The MySQL commit log is consumed in the master region and produces a cache invalidation only in the master region. Because cache invalidations are produced from the MySQL commit log (versus cache invalidations and the commit log being replicated separately) the cache invalidation won’t even appear in a non-master region until the replication log is replicated there. Imagine all of the weird situations that could happen if the cache invalidations were replicated separately and a cache invalidation would show up before the database even knew about it (you could try to invalidate something that wasn’t in cache yet).
What happens if a stale read happens in a non-master region?
Because the system is eventually consistent, data in the slave regions will be out-of-date at some point. To limit the impact of clients reading out-of-date data, Facebook added a remote marker mechanism. When a web server wants to update a dataset and ensure that stale data is not read (or at least that there is a lower chance of stale reads), the server sets a marker for the key (where the marker’s value is a region may or not be the master region). Then, the server deletes the value from the region’s cache. Future reads will then be redirected to the region value set in the marker.
Takeaways
This paper contains an incredible amount of detail on how Facebook scaled their memcache infrastructure, although the paper was published in 2013 and 8 years is a long time. I would be willing to bet that their infrastructure has changed significantly since the paper was originally published.
Even with the knowledge that the underlying infrastructure has likely changed, this paper provides useful insights into how the engineering org made many tradeoffs in the design based on data from the production system (and with the ultimate goal of a maintaining as simple of a design as possible.
Since 2013, a number of other companies have built key value stores and published research on their architectures - in the future I hope to read those papers and contrast their approaches with Facebook’s!