micahlerner.com
TAO: Facebook’s Distributed Data Store for the Social Graph
Published October 13, 2021
Found something wrong? Submit a pull request!
Discussion on Hacker News
The papers over the next few weeks will be from (or related to) research from VLDB 2021 - on the horizon is one of my favorite systems conferences SOSP. As always, feel free to reach out on Twitter with feedback or suggestions about papers to read! These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed.
TAO: Facebook’s Distributed Data Store for the Social Graph
This is the first in a two part series on TAOTAO stands for “The Associations and Objects” - associations are the edges in graph, and objects are the nodes. , Facebook’s read-optimized, eventually-consistent graph database. Unlike other graph databases, TAO focuses exclusively on serving and caching a constrained set of application requests at scale (in contrast to systems focused on data analysis). Furthermore, the system builds on expertise scaling MySQL and memcache as discussed in a previous paper review.
The first paper in the series focuses on the original TAO paper, describing the motivation for building the system, it’s architecture, and engineering lessons learned along the way. The second part focuses on TAO-related research published at this year’s VLDB - RAMP-TAO: Layering Atomic Transactions on Facebook’s Online TAO Data Store. This new paper describes the design and implementation of transactions on top of the existing large scale distributed system - a task made more difficult by the requirement that applications should gradually migrate to the new functionality and that the work to support transactions should have limited impact on the performance of existing applications.
What are the paper’s contributions?
The original TAO paper makes three contributions - characterizing and motivating a graph database implementation suited for Facebook’s read-heavy traffic, providing a data model and developer API for the aforementioned database, and describing the architecture that allowed the database to scale.
Motivation
The paper begins with a section describing the motivation for TAO’s initial development. When Facebook was originally developed, MySQL was used as the datastore for the graph. As the site scaled, a memcache layer was added in front of the MySQL databases, to lighten the load.
While inserting memcache into the stack worked for some period of time, the paper cites three main problems with the implementation: inefficient edge lists, distributed control logic, and expensive read-after-write consistency.
Inefficient edge lists
Application developers within Facebook used edge-lists to represent aggregations of the information in the graph - for example, a list of the friendships a user has (each friendship is an edge in the graph, and the users are the nodes). Unfortunately, maintaining these lists in memcache was inefficient - memcache is a simple key value store without support for lists, meaning that common list-related functionalityLike that supported in Redis. is inefficient. If a list needs to be updated (say for example, a friendship is deleted), the logic to update the list would be complicated - in particular, the part of the logic related to coordinating the update of the list across several copies of the same data in multiple data centers.
Distributed Control Logic
Control logic (in the context of Facebook’s graph store architecture) means the ability to manipulate how the system is accessed. Before TAO was implemented, the graph data store had distributed control logic - clients communciated directly with the memcache nodes, and there is not a single point of control to gate client access to the system. This property makes it difficult to guard against misbehaving clients and thundering herds.
Expensive read-after-write consistency
Read-after-write consistency means that if a client writes data, then performs a read of the data, the client should see the result of the write that it performed. If a system doesn’t have this property, users might be confused - “why did the like button they just pressed not register when they reloaded the page?”.
Ensuring read-after-write consistency was expensive and difficult for Facebook’s memcache-based system, which used MySQL databases with master/slave replication to propagate database writes between datacenters. While Facebook developed internal technologyAs described in my previous paper review, Scaling Memcache at Facebook. to stream changes between databases, existing systems that used the MySQL and memcache combo relied on complicated cache-invalidation logicFor example, followers would forward reads for cache keys invalidated by a write to the leader database, increasing load and incurring potentially slow inter-regional communication. that incurred networking overhead. The goal of this new system is to avoid this overhead (with an approach described later in the paper).
Data model and API
TAO is an eventually consistentFor a description of eventual consistency (and related topics!), I highly recommend this post from Werner Vogels. read-optimized data store for the Facebook graph.
It stores two entities - objects and associations (the relationships between objects). Now we get to learn why the graph datastore is called TAO - the name is an abbreviation that stands for “The Associations and Objects”.
As an example of how objects and associations are used to model data, consider two common social network functions:
- Friendships between users: users in the database are stored as objects, and the relationship between users are associations.
- Check-ins: the user and the location they check in to are objects. An association exists between them to represent that the given user has checked into a given location.
Objects and associations have different database representations:
- Each object in the database has an id and type.
- Each association contains the ids of the objects connected by the given edge, as well as the type of the association (check-in, friendship, etc). Additionally, each association has a timestamp that is used for querying (described later in the paper review).
Key-value metadata can be associated with both objects and associations, although the possible keys, and value type are constrained by the type of the object or association.
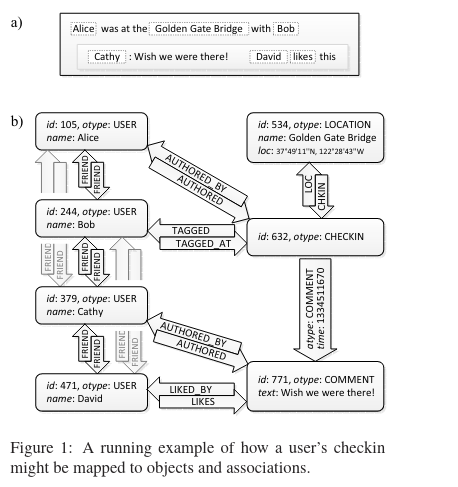
To provide access to this data, TAO provides three main APIs: the Object API, the Association API, and the Association Querying API.
Two of the three (the Object API and Association API) provide create, read, update, and delete operations for individual objects.
In contrast, the Association Querying API provides an interface for performing common queries on the graph. The query methods allow application developers to fetch associations for a given object and type (potentially constraining by time range or the set of objects that the the association points), calculating the count of associations for an object, and providing pagination-like functionality. The paper provides example query patterns like fetching the “50 most recent comments on Alice’s checkin” or “how many checkins at the GG Bridge?”. Queries in this API return multiple associations, and call this type of result an association list.
Architecture
The architecture of TAO contains two layers, the storage layer and the caching layer.
Storage Layer
The storage layer (as the name suggests) persists graph data in MySQLFacebook has invested a significant amount of resources in their MySQL deployments, as evidenced by their MyRocks storage engine and other posts on their tech blog. . There are two key technical points to the storage layer: shards and the tables used to store the graph data itself.
The graph data is divided into shards (represented as a MySQL database), and shards are mapped to one of many database servers. Objects and associations for each shard are stored in separate tables.
Cache Layer
The cache layer is optimized for read requests and stores query results in memory. There are three key ideas in the cache layer: cache servers, cache tiers, and leader/follower tiers.
Clients communicate read and write requests to cache servers. Each cache server services requests for a set of shards in the storage layer, and caches objects, associatons, and the size of association lists (via the query patterns mentioned in the API section above).
A cache tier is a collection of cache servers that can respond to requests for all shards - the number of cache servers in each tier is configurable, as is the mapping from request to cache server.
Cache tiers can be set up as leaders or followers. Whether a cache tier is a leader or a follower impacts its behavior:
- Follower tiers can serve read requests without communicating with the leader (although they forward read misses and write requests to the corresponding cache servers in the leader tier).
- Leader tiers communicate with the storage layer (by reading and writing to/from the database), as well as with follower cache tiers. In the background, the leader tier sends cache update messages to follower tiers (resulting in the eventual consistency mentioned earlier on in this paper review).
Scaling
To operate at large scale, TAO needed to extend beyond a single region. The system accomplishes this goal by using a master/slave configuration for each shard of the database.
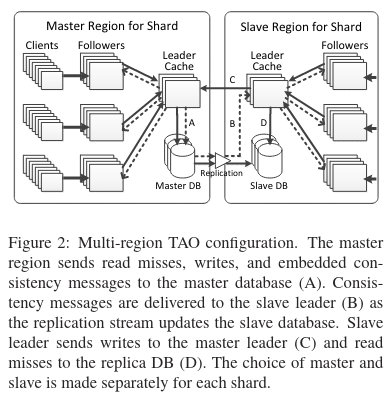
In the master/slave configuration, each shard has a single leader cache tier and many follower cache tiers. The data in the storage layer for each shard is replicated from the master region to slave regions asynchronously.
A primary difference between the single region configuration described above and the multi-region configuration is the behavior of the leader tier when it receives writes. In a single-region configuration, the leader tier always forwards writes to the storage layer. In contrast, the leader tier in a multi-region TAO configuration writes to the storage layer only if the leader tier is in the master region. If the leader tier is not in the master region (meaning it is in a slave region!), then the leader tier needs to forward the write to the master region. Once the master region acknowledges the write, the slave region updates its local cache with the result of the write.
Conclusion
TAO is a graph database operating at immense scale. The system was built on the emerging needs of Facebook, and had limited support for transactionsThe paper mentions limited transaction-like behavior but does not provide significant details . The next paper in the series discusses how transactions were added to the system, while maintaining performance for existing applications and providing an opt-in upgrade path for new applications.
As always, feel free to reach out on Twitter with any feedback or paper suggestions. Until next time