micahlerner.com
Perseus: A Fail-Slow Detection Framework for Cloud Storage Systems
Published April 16, 2023
Found something wrong? Submit a pull request!
Discussion on Hacker News
The Perseus paper won a best paper award at FAST (File and Storage Technologies) and is one in a series I will be writing about from that conference. These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
Perseus: A Fail-Slow Detection Framework for Cloud Storage Systems
What is the research?
This paper describes a system for detecting fail-slow instances in Alibaba storage clusters - fail-slow Fail-slow is documented by previous research, including Fail-Slow at Scale: Evidence of Hardware Performance Faults in Large Production Systems (which has a great paper review from Adrian Colyer’s blog here). is failure mode in which hardware fails non-obviously, potentially by consistently degrading performance over time. While hardware deployed in data centers at scale fails for a variety of reasons (including environmental conditions, and hardware defects), automated detection normally finds these problems, allowing quick remediation by oncall engineers at the datacenter. Unfortunately, not all hardware misbehavior follows this path, as noted by previous research into fail-slow.
The Perseus paper focuses specifically on detecting fail-slow in storage devices, although the category of problem impacts a wide variety of hardware. If left unresolved, fail-slow instances can dramatically impact performance and tail latencySee the The Tail at Scale, and the associated paper review from The Morning Paper. . For example, if a drive fails, database writes reaching that drive may automatically fail or take a significant period of time to complete. The degradation can be particularly acute for distributed systems requiring multiple acknowledgements of a write before returning success to a clientFor example, Cassandra accomplishes this using different consistency levels. . Continuing speedups of hardware further exacerbates the problemSee Attack of the Killer Microseconds. .
The fail-slow phenomenon is difficult to detect for a variety of reasons. Typical SLO-based approaches monitoring a fixed performance threshold are insufficiently sensitive - varying load can cause periodic performance regressions, even if a drive is healthySLOs are described in more detail in the SRE book. . Othere orevious workThe IASO model is one example - it relies on timeouts recorded by systems like Cassandra to identify problematic machines. to identify fail-slow cases relies on deep integration with an application, which isn’t possible for cloud providers (who oftentimes have limited visibility into user workloads). The Perseus paper is novel in several respects, including not relying on deep knowledge of the workloads it is monitoring for detection.
What are the paper’s contributions?
The paper makes four main contributions:
- A framework for detecting instances of fail-slow at scale, including takeaways about what did not work.
- The design and implementation of Perseus, a system for detecting fail-slow instances in storage clusters.
- An evaluation of the technique against a ground truth dataset from Alibaba.
- Root-cause analysis of detected failures.
How does the system work?
In instrumenting their approach, the authors set out with several main design goals:
- Non-intrusive: Alibaba runs cloud workloads, and doesn’t necessarily need (or want) to rely on deeper integration with customer applications.
- Fine-grained: failures identified by the system should be specific about what hardware is failing and why.
- Accurate: the system should correctly identify failures, limiting wasted time by oncall engineers.
- General: the solution should be able to identify problems across different types of hardware within the same category (for example both SSDs and HDDs).
The team built up a dataset of drive performance using daemons deployed in the Alibaba cloud, recording time series of average latency, average throughput keyed by machine and drive (as a machine can have many drives).
Initial Attempts
With these goals in mind, the authors evaluated three different techniques for detecting fail-slow instances: threshold filtering, peer evaluation, and an approach based on previous research named IASOIASO: A Fail-Slow Detection and Mitigation Framework for Distributed Storage Services was previously published at Usenix ATC 2019. . Each of these techniques had their shortcomings with respect to the design goals.
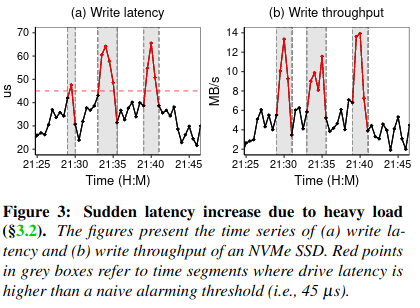
Threshold filtering relied on identifying problematic drives by recording whether write latency increased over a fixed threshold. This approach didn’t work because disk latency would spike periodically when under heavy load, with little correlation to drive failure.
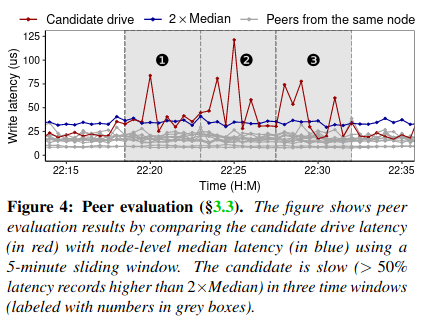
Peer evaluation compared the performance of drives on the same machine against one another - theoretically drives attached to the same machine should receive somewhat similar workloads if used by the same customer, so repeated deviations of a drive’s performance from its neighbors would flag the drive for further inspection. The main downside to this approach was a reliance on fine-tuning for proper detection - the duration and frequency of deviations differed by clusters and workloads, requiring significant engineering work for accurate detection of fail slow events.
The last attempted approach described by the authors was one based on previous research from IASO: A Fail-Slow Detection and Mitigation Framework for Distributed Storage Services. This IASO-based model relies on timeouts - for example, counting the number of timeouts Cassandra has to a specific node, then using this as a proxy for a problematic set of devices. The IASO based approach was not suitable for a number of reasons, including that it targets nodes (rather than specific devices), and relies on knowledge of the workload (which isn’t true of Alibaba’s cloud). The authors still attempted to adapt it to their needs by reusing the output of the peer evaluation approach described aboveThe details of this implementation weren’t clear to me from the paper, but I reached out to one of the authors, Giorgio Xu for clarification. :) .
Perseus
The final approach that the authors implemented was given the code-name Perseus. It relies on analysis of the distribution of latency vs throughputThe paper also considered the relationship between latency and IOPS (operations per second), but found it didn’t have as strong of a correlation. for a node - using metrics gathered by Alibaba daemons, the authors determined that latency vs throughput could vary within a cluster and within DB nodes (depending on the specific workload). However, within a specific node there was a closer relationship between latency and throughput, allowing analysis of whether the performance of a specific drive attached to a node deviates from its neighbors.
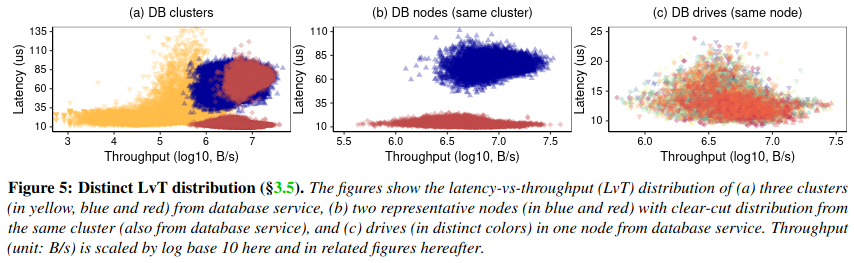
Using the data on latency vs throughput for a node, Perseus follows a four step process: performing outlier detection on the raw data, building a regression model, identifying fail slow events, and evaluating the risk of any detected events.
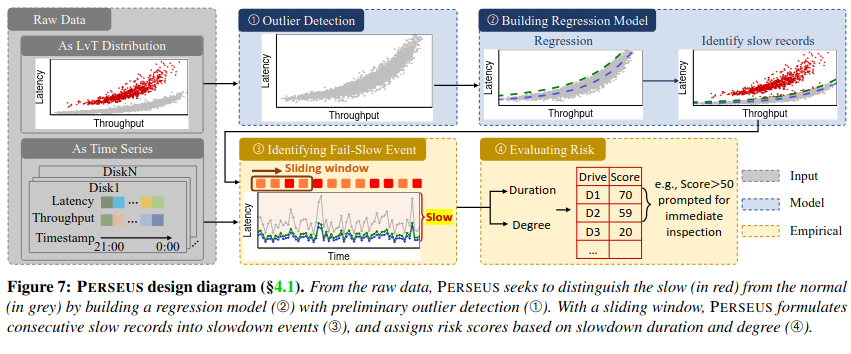
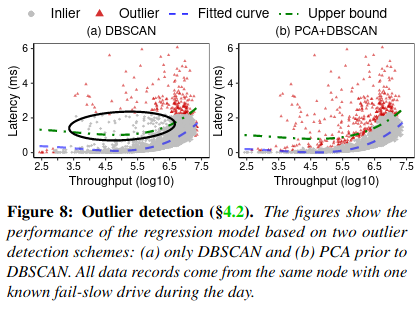
In the first step, Perseus makes use of two algorithms (DBScan and Principal Component AnalysisBoth are fairly standard algorithms for analyzing complex datasets - see an in-depth explanations of DBScan here and Principal Component Analysis here. ) for identifying outlier data points.
Next, the system excludes outliers and builds a regression model, producing a curve that fits remaining data points.
Perseus then runs this regression model over the time series for every drive in the node - for every drive, a given throughput should produce a given latency. Then the system measures the difference between the drive’s actual and expected latency for a given throughput using the slowdown ratio (upper bound of expected latency divided by actual drive latency).
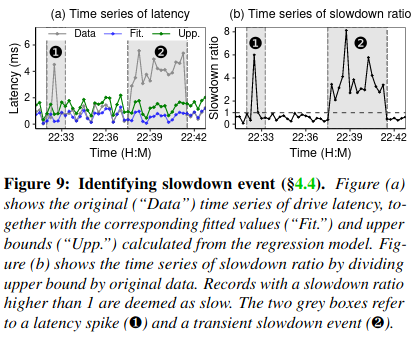
Lastly, the system scans the slowdown ratio timeseries for every drive, finding and categorizing slow down events based on their duration and severity (represented by a drive’s difference from expected performance). Drives with repeated, severe slowdowns are flagged for further investigation by engineers onsite.
How is the research evaluated?
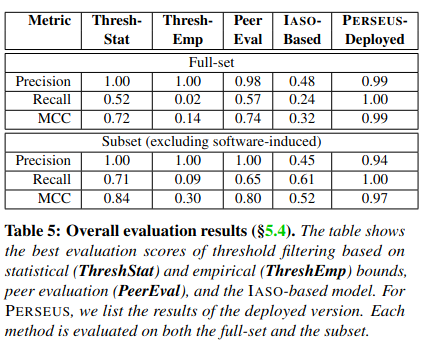
To evalute the research, the authors compare the precision, recall, and Matthews Correlation Coefficient (MCC)MCC is described in more depth here. of different approaches - “the precision indicates the percentage of drives identified by a method is indeed a fail-slow one. The recall is the percentage of real fail-slow drives identified by a method.” The authors use MCC because, “it evaluates binary classification models more fairly on imbalanced datasets.” Perseus outperforms each of the other approaches on these three metrics.
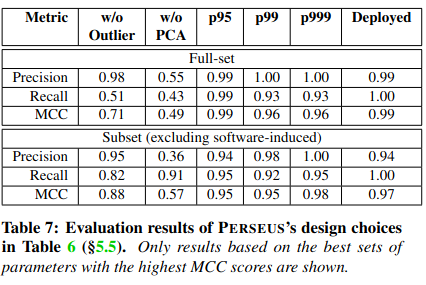
The paper also evaluates the different components of Perseus’ design. For example, measuring the impact of outlier removal, the combination of Principal Component Analysis with DBScan, and the thresholds used for what is considered as the upper bound of expected latency for a given throughput (a factor in computing the slowdown ratio). The data from the paper supports their decision making.
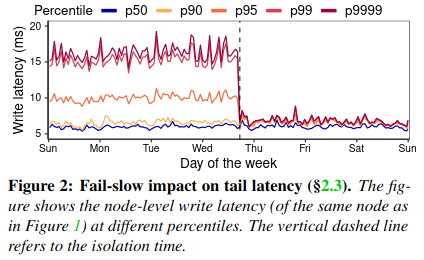
Lastly, the paper notes the removal of fail-slow drives is signfiicant on tail latency:
The most direct benefit of deploying PERSEUS is reducing tail latency. By isolating the fail-slow, node-level 95th, 99th and 99.99th write latencies are reduced by 30.67% (±10.96%), 46.39% (±14.84%), and 48.05% (±15.53%), respectively.
Root Cause Analysis
The paper wraps up by diving into several root-causes of fail slow instances in Alibaba production clusters. Software problems caused a majority of the failures.
One example root cause happened because an operating system bug introduced thread contentionSee this post on thread contention for a deeper dive. - each drive received a thread from the operating system to manage IO, but a software bug would cause multiple drives to share the same thread, impacting performance.
Conclusion
An interesting facet of the paper was quantifying the impact to tail latency from few fail-slow events in a single class of hardware (the paper uses a test dataset of 315 instances). I also appreciated the research identifying potential shortcomings of the approach. For example, Perseus makes the assumption that single (or few) drives on a node will fail-slow at the same time. If all drives attached to a machine fail-slow (which is possible), the system would likely not detect the problem.
For cloud providers with limited instrumentation of customer workloads, the approach seems quite promising, especially with a potential expansion to other fail-slow cases like memory and networking. At the same time, growing adoption of commoditized infrastructureFor example, Cassandra can be hosted by both AWS and GCP, meaning the provider could use a potentially-simpler IASO-based model. might mean that a Perseus-like approach is applied to only low-level infrastructure.