micahlerner.com
Metastable Failures in the Wild
Published July 11, 2022
Found something wrong? Submit a pull request!
Discussion on Hacker News
After this paper, I’ll be reading a few others from this year’s OSDI conference. These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
Metastable Failures in the Wild
What is the research?
Metastable failuresThe authors first discussed the subject in Metastable Failures in Distributed Systems. One of authors (Alexey Charapko) wrote an overview of the paper here. are a class of outage that, “feed and strengthen their own failed condition. The main characteristic of a metastable failure is a positive feedback loop that keeps the system in a degraded/failed state”Aleksey Charapko, one of the authors of the paper, provided this characterization in their discussion of the research here. Aleksey also runs a great reading group that I highly recommend for distributed systems topics! . While some failures that match this characterization are well known (like overload, cascading failures, and retry storms), the authors argue that categorizing them under a single class will facilitate work by industry practitioners and academia to address themThe authors note that this type of categorization for other types of distributed systems failures (like fail-stop, fail-slow, and scalability failures) had a similar affect. Of those, I’m particularly interested in fail-slow (which are hardware failures that stop short of total failure, often occurring in systems at scale) and hope to cover them in a future paper review. .
While there are well-known mitigationsLike introducing jitter, backoff behavior, or other techniques for lightening load (some of these are described in the SRE book). to reducing types of metastable failures, these approaches don’t stop the class of failure from continuously plaguing systems and operations teams - a fact highlighted by the paper’s dataset on severe, user-facing outages from a wide variety of cloud providers and businesses. Given the serious and complex outages that the failure class could lead to, research into systematically finding and eliminating the possibility of metastable failures before they happen could have an impact across industry.
Background
Metastable failures happen in distributed systems, which run in one of several states: stable, vulnerable, or metastable.
To understand the transitions between different system states, we can consider service behavior in the presence of growing numbers of request retries - if a system can both serve all requests successfully and scale to handle additional load, it is in a stable state.
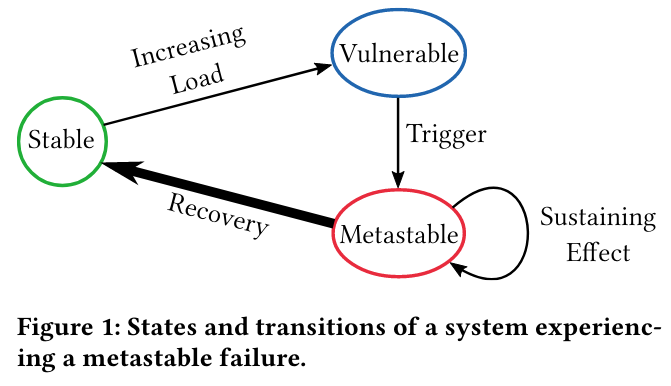
A system in a stable state can transition into a vulnerable state for a wide variety of factors. One example is if a system’s organic traffic grows over time, but its reserve capacity does not - in this situation, the service transitions to a vulnerable state because it can’t scale up if it becomes overloaded.
Once in a vulnerable state, the system can transition to metastable failure due to a trigger. One example trigger is slowdown in the system’s dependenciesLike increased database latency. - dependency slowdown impacts the ability of the service to respond in a timely manner to clients, as it must wait longer to receive required responses.
If a trigger’s magnitude or duration is strong enough, a system might enter a metastable state and begin failing in a manner that compounds the original problem. For example, if the server takes long enough to respond (due to the previously mentioned dependency slowdown), a client might give up on the request and re-try. As more clients retry, more load is added to the system, meaning that existing requests keep getting slower (and in turn causing more client retries). This type of vicious cycle is called a sustaining effect because it keeps the system in a failing state, even after the original trigger (dependency slowdown) is removed.
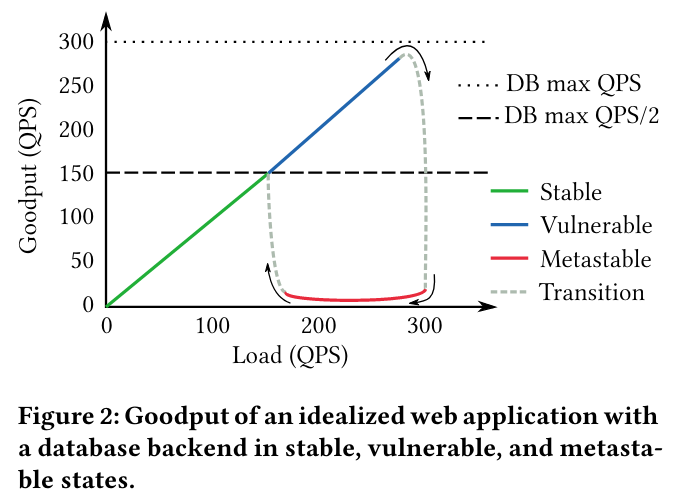
Oftentimes transitioning out of metastable failure and into a stable safe state requires action like dropping retries, or adding emergency capacity.
What are the paper’s contributions?
The Metastable Failures in the Wild makes four main contributions:
- An analysis of metastable failures from a variety of cloud providers and businesses, compiled from publicly available incident data
- A model for representing the causes/effects of metastable failures.
- An industry perspective on metastable failure from Twitter
- Experimental testbed and results for several applications, including MongoDB replication, with induced metastable failures.
Metastable Failures in the Wild
To understand the occurrence of metastable failures, the paper first builds a dataset from publicly available data outage reporting tools and community datasets. In particular, the authors draw on public information from cloud providers (AWS, Azure, GCP), businesses (IBM, Spotify), and open source projects (Elasticsearch, Apache Cassandra)The paper cites a number of great resources that track public postmortems, including collections on Pinboard, postmortems.info, and SRE Weekly. .
The paper then evaluates this dataset for shared characteristics of the failure class, looking for:
tell-tale signs of metastability—temporary triggers, work amplification or sustaining effects, and certain specific mitigation practices. More specifically, we look for patterns when a trigger initiates some processes that amplify the initial trigger-induced problem and sustain the degraded performance state even after the trigger is removed.
After filtering the dataset, the authors annotate outages with information about triggers (what pushed the transition from vulnerable to metastable failure), sustaining effects (what kept the system in metastable failure after the initial trigger was removed), and mitigations. The paper also categorizes the impact of the incidents (measured by length of time and count of impacted services).
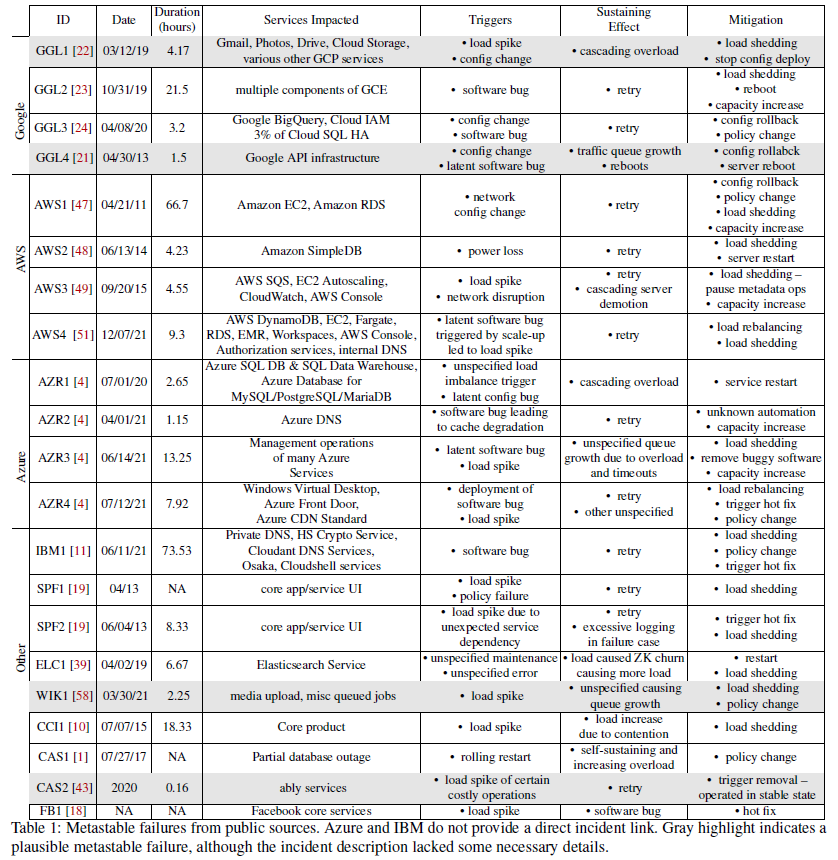
Many (45%) of the incidents have multiple triggers, while load spikes and engineer errors are involved in 35% and 45% of incidents respectively. Interestingly retry policy is one of the most common sustaining effects (50% of the incidents).
Pulling one example from the dataset, Amazon EC2 and RDS are the subjects of one of the most severe incidents in the paperThis incident has an amazing amount of detail on the system internals impacted during the incident, making this paper’s research possible! . A trigger for the incident was network overload that occurred while attempting to migrate traffic. When the network overload was resolved, nodes in the now restored part of the network sent a surge of requests, increasing latency in other parts of the system. To bring EBS back to a workable condition, the team had to add additional capacity, shed load, and manipulate traffic prioritization to ensure that the requests required to restore the system could complete.
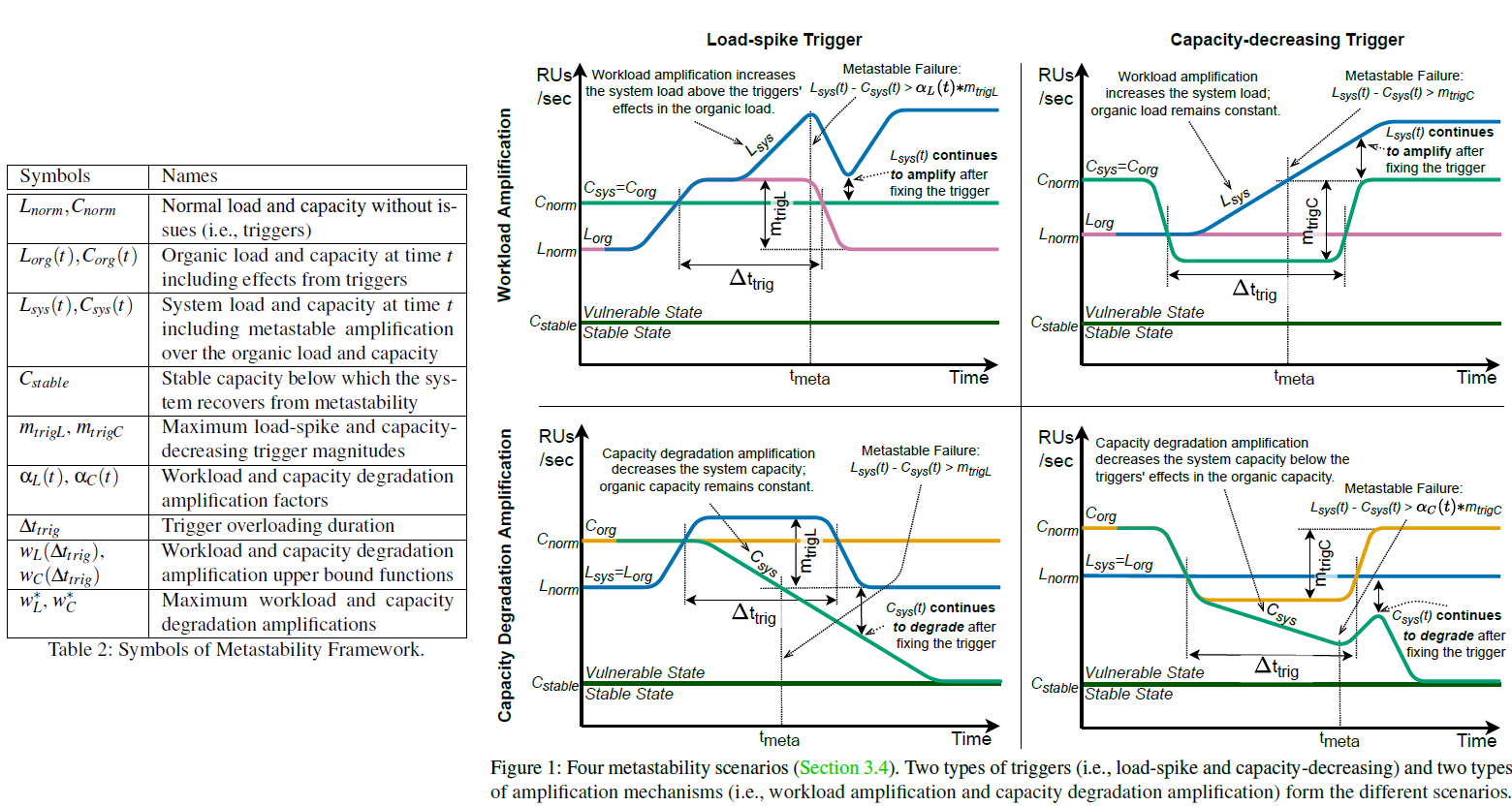
Metastable Model
To model how a system behaves with respect to metastability, the authors introduce a mathematical framework that models capacity, load, responses to triggers, and amplification (feedback loops that impact a system’s load by changing either capacity or load)I elide the mathematical notation in this post, but recommend referencing the paper if this topic sounds interesting! .
This framework is used to model two types of triggers:
- Load-spike triggers: events that increase the load on the system (potentially adding client retries on top of the base load the service receive).
- Capacity-decreasing triggers: events that reduce the system’s ability to serve traffic. For example, if a service relies on a cache whose hit rate drops.
The triggers are combined with two types of amplification:
- Workload amplification: a feedback loop that increases the system load (retries would be an example).
- Capacity degradation amplification: a feedback loop that decreases the system load. For example, a lookasideLu Pan has an article on the different types of caches, and this article from VMWare also contains help context. cache-based system not being able to refill a cache in an overload situation.
The authors model combinations of these triggers and amplification mechanisms in order to represent how a system behaves in different situations.
Metastability at Twitter
The paper includes one example of metastability in a system at Twitter that relies on Garbage Collection (GC)Twitter has a large number of Scala services and has extensive information on how to use the language. .
In the case study, a load test of the system serves as a trigger, increasing one of the service’s internal queues. A larger queue increases memory pressure and GC, further increasing the queue length as requests start taking longer and longer - this feedback loop is an example of a sustaining effectThis is likely capacity degradation amplification because the paper notes that, “high queueing increases memory pressure and mark-and-sweep processing during GC, causing job slowdowns and thus higher queueing.” .
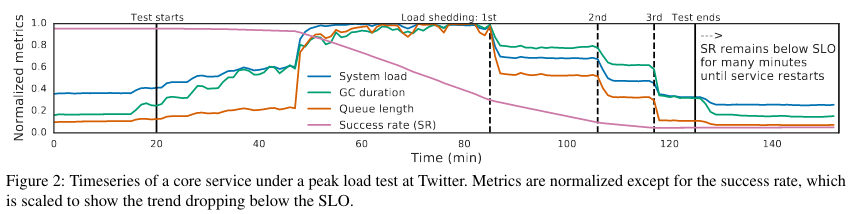
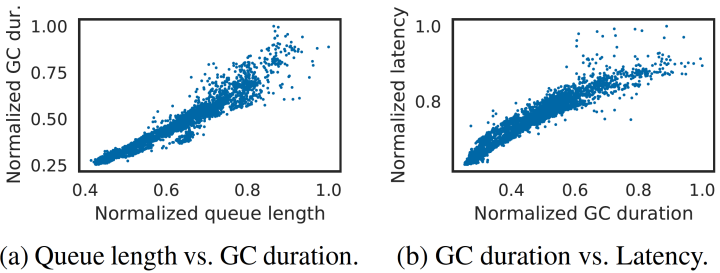
To solve the issue, oncallers can increase the capacity of the serving system, or change the service to provide enough overhead (such that additional load doesn’t interact with GC processes).
Experimental Testbed and Results
The paper includes a section with experimental results from triggering metastability in a selection of systems.
One of the experiments is related to state machine replication implemented in MongoDBThe original paper is here, although there is also a summary from Aleksey Charapko’s reading group here. . The primary goal of this experiment is to demonstrate that the duration/magnitude of a trigger (in this case, resource constriction that leads to retries) can cause a system to transition from vulnerable to metastable failure.
The experiment evaluates how temporarily restricting CPU resources for different periods introduces latency that leads to client timeouts and retry storms. In response to triggers of limited duration, the system doesn’t transition to a metastable state. This is not true for longer triggers with the same level of resource constriction, which cause client timeouts and subsequent retries (introducing a sustaining effect). This experiment demonstrates that the duration of a trigger impacts whether a system transitions into a metastable failure mode.
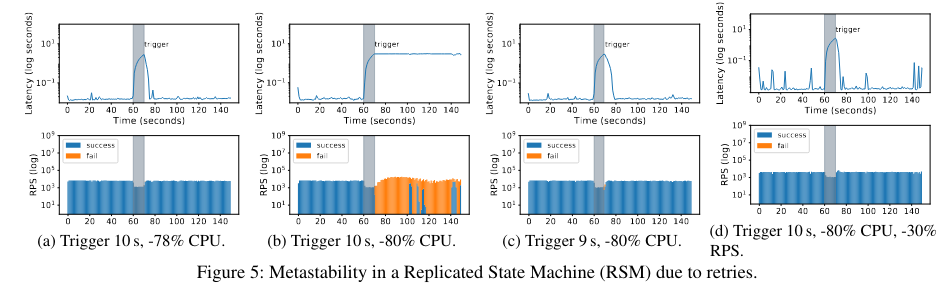
The paper also tests a look-aside cacheSee prior side note on lookaside caches above. implementation, where a drop in cache hit rate (the trigger) causes a significant increase in requests to the backend service. The backend service is not able to increase its capacity, and begins timing out requests. Timed-out requests do not refill the cache, meaning that the system can not recover its cache hit rate (serving as the sustaining effect).

Conclusion
There are several great things about this paper. First of all, the survey of publically available incident reporting, with annotations on the triggers, impact, mitigation, and sustaining effects is impressive - several studies of other failure classesFor example, What Bugs Live in the Cloud? A Study of 3000+ Issues in Cloud Systems. start with a more structured (or at least semi-labeled dataset).
I’m also interested in seeing how this research continues to progress - in particular, I’m looking forward to seeing how future research systematically predicts, then reduces (or eliminates) metastable failures - potentially the authors will use something along the lines of MIT’s STAMP methodology)!