micahlerner.com
Ambry: LinkedIn’s Scalable Geo-Distributed Object Store
Published March 28, 2023
Found something wrong? Submit a pull request!
Discussion on Hacker News
These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
Ambry: LinkedIn’s Scalable Geo-Distributed Object Store
What is the research?
Blob stores are used by companies across industry (including Meta’s f4, Twitter, and Amazon) to store large objects, like photos and videos. This paper focuses on Ambry from LinkedIn which, unlike other implementations, is open source.
Ambry aims to provide low latency blob store operations, with high throughput, using globally distributed storage and compute resources. At the time of the paper’s publication in 2016, LinkedIn had hundreds of millions of users, and served more than 120 TB every daySharing the required I only want to serve 5TBs reference. . To reach this scale, the team had to solve several challenges including wide variance in object sizes, rapid growth, and unpredictable read workloads.
How does the system work?
Blobs and Partitions
Ambry’s core abstraction is the blob, an immutable structure for storing data. Each blob is assigned to a partition on disk and is referenced via a blob ID. Users of the system interact with blobs by performing put, get, and delete operations. Ambry represents put and delete operations to blobs as entries in an append-only log for their assigned partition.
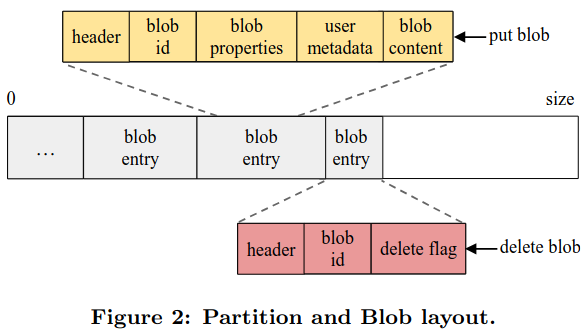
Partitioning data allows Ambry to scale - as users add more data to the system, it can add more partitions. By default, a new partition is read-write (meaning that it accepts both put, get, and delete traffic). As a partition nears capacity, it transitions into read, meaning that it no longer supports storing new blobs via put operations. Traffic to the system tends to be targeted at more recent content, placing higher load on read-write partitions.
Architecture
To provide scalable read and write access to blobs, Ambry uses three high-level components: Cluster Managers, the Frontend Layer, and Datanodes.
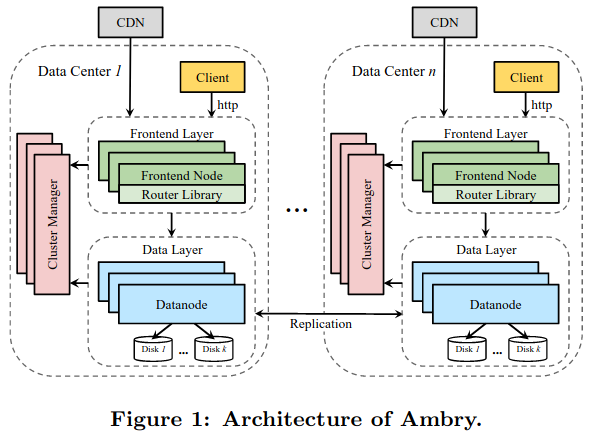
Cluster Managers
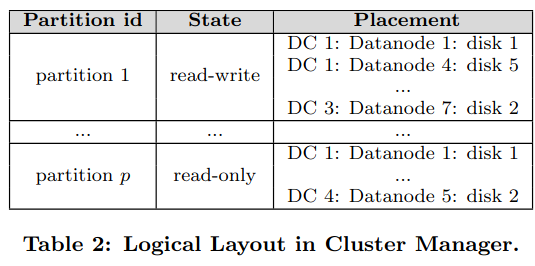
Cluster managers make decisions about how data is stored in the system across geo-distributed data centers, as well as storing the state of the clusterThe paper mentions that state is mostly stored in Zookeeper. . For example, they store the logical layout of an Ambry deployment, covering whether a partition is read-write or read-only, as well as the partition placement on disks in data centers.
The Frontend Layer
The Frontend Layer is made up of stateless servers, each pulling configuration from Cluster Managers. These servers primarily respond to user requests, and their stateless nature simplifies scaling - arbitrary numbers of new servers can be added to the frontend layer in response to increasing load. Beyond handling requests, the Frontend Layer also performs security checks and logs data to LinkedIn’s change-data capture systemChange data capture or event sourcing is a way of logging state changes for consumption/replay by downstream services for arbitrary purposes, like replicating to a secondary data source. .
The Frontend Layer routes requests to Datanodes by combining the state supplied by Cluster Managers with a routing library that handles advanced features like:
- Fetching large “chunked” files from multiple partitions and combining the results (each chunk is assigned an ID, and mapped to a uniquely identified blob stored in a partition).
- Detecting failures when fetching certain partitions from datanodes.
- Following a retry policy to fetch data on failure.

Datanodes
Datanodes enable low-latency access to content stored in memory (or on disk) by using several performance enhancements. To enable fast access to blobs, datanodes store an index mapping blob IDs to their offset in the storage medium. As new operations update the state of a blob (potentially deleting it), datanodes update this index. When responding to incoming queries, the datanode references the index to find the state of a blob.

To maximize the number of blobs stored in disk cache, Ambry also optimizes how the index itself is stored, paging out older entries in the index to diskThe paper also references SSTables, used by systems like Cassandra to store and compact indexes. . Datanodes also rely on other tricks, like zero copy operationsWhich limit unnecessary memory operations, as discussed in a previous paper review of Breakfast of Champions: Towards Zero-Copy Serialization with NIC Scatter-Gather. and batching writes to diskDiscussed in the paper review of Kangaroo: Caching Billions of Tiny Objects on Flash. .
Operations
When the Frontend Layer receives an operation from a client, the server’s routing library helps with contacting the correct partitions:
In the put operation, the partition is chosen randomly (for data balancing purposes), and in the get/delete operation the partition is extracted from the blob id.
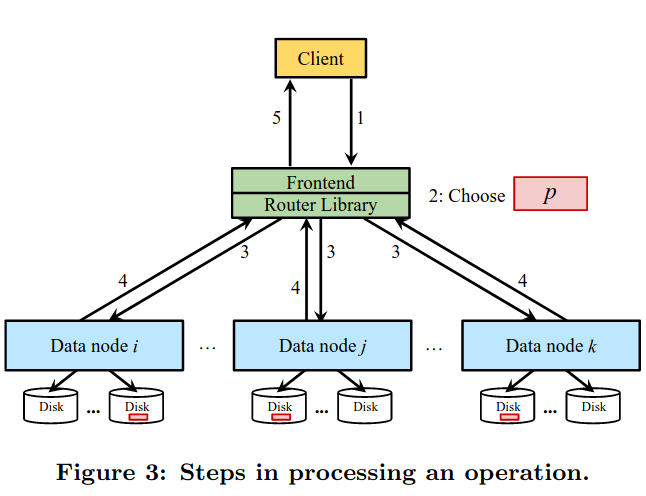
For put operations, Ambry can be configured to replicate synchronously (which makes sure that the blob appears on multiple datanodes before returning), or asynchronously - synchronous replication safeguards against data loss, but introduces higher latency on the write path.
If set up in an asynchronous configuration, replicas of a partition exchange journals storing blobs and their offsets in storage. After reconciling these journals, they transfer blobs between one another. As far as I understand, the implementation seems like a gossip protocolGossip protocols are discussed in more depth here. There is also an interesting paper from Werner Vogels (CTO of Amazon) on the topic here. .

How is the research evaluated?
The paper evaluates the research in two main areasThe paper also includes an evaluation of load-balancing not from production data, which I didn’t find to be particularly useful - it would be great if there was updated data on this topic from the project! : throughput and latency, and geo-distributed operations.
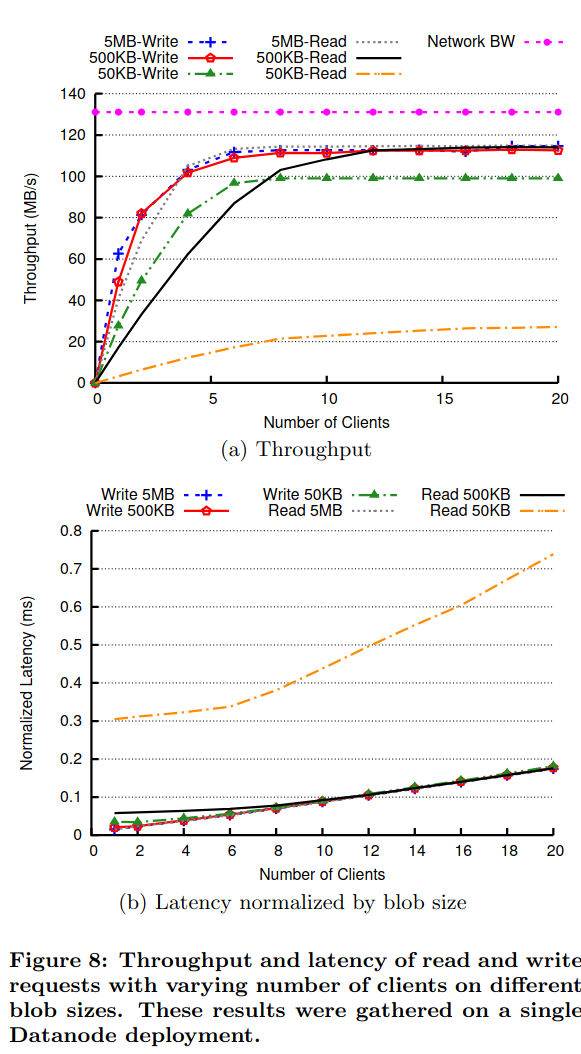
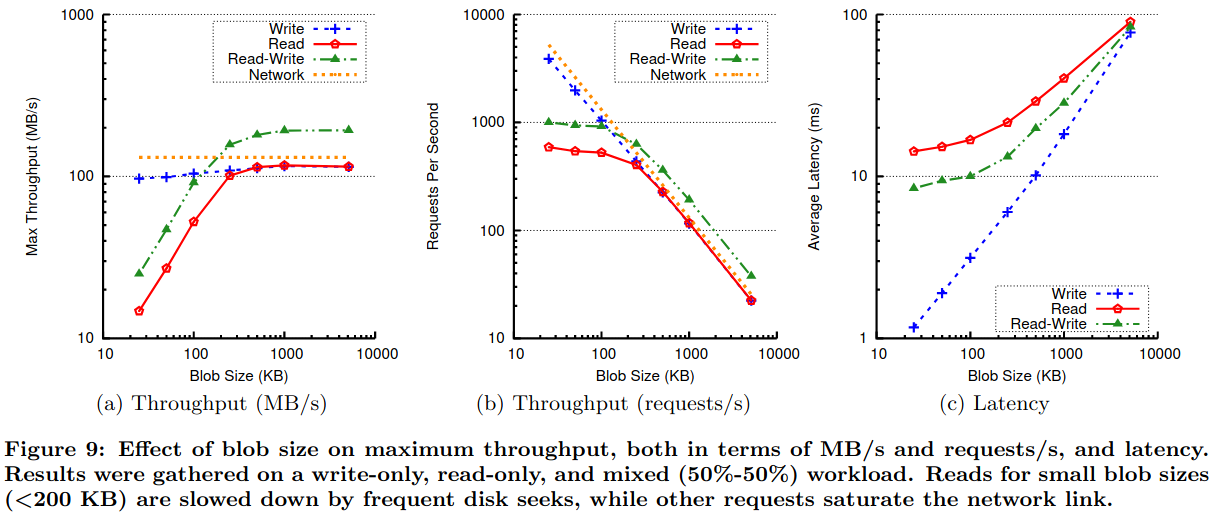
To test the system’s throughput and latency (critical to low-cost serving of user-facing traffic at scale), the authors send read and write traffic of differently sized objects to an Ambry deployment. The system is able to provide near-equivalent performance to reads/writes of larger objects, but tops out at a lower performance limit with many small reads/writes. The paper notes that this is likely due to large numbers of disk seeks (and a similarly shaped workload is unlikely to happen in a real deployment).
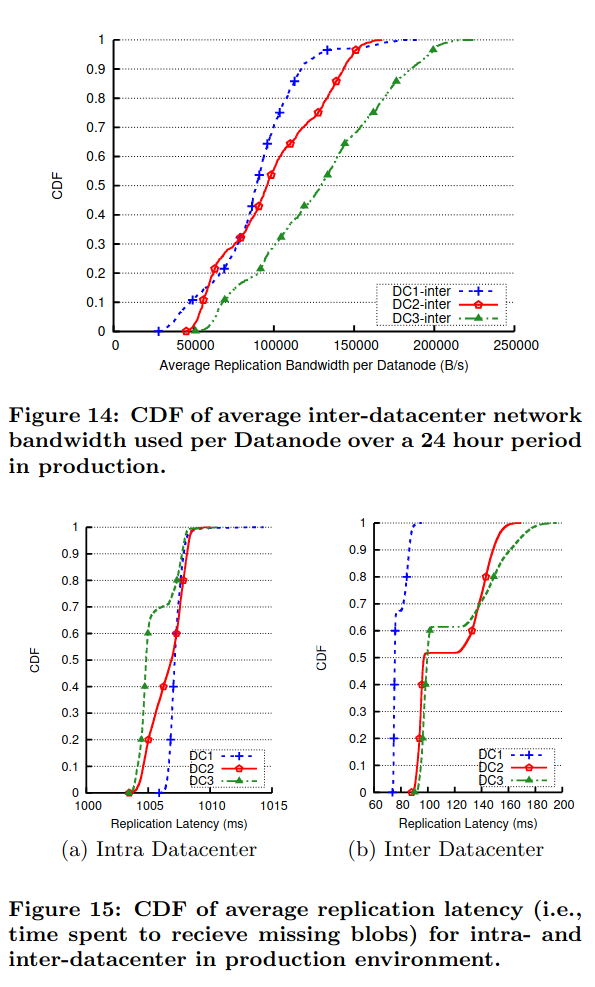
To evaluate geo-distributed operations and replication, the paper measures the bandwidth and time it requires, finding that both are near-negligble:
- In 85% of cases, replication lag was non-existent.
- Bandwidth for replicating blobs was small (10MB/s), but higher for inter-datacenter communication.
Conclusion
Unlike other blobstoresI haven’t written about the other blob storage systems from Meta and Twitter, but would like to soon! , Ambry is unique in existing as an open source implementation. The system also effectively makes tradeoffs at scale around replication using a gossip-like protocol. The paper also documents some of the challenges with load balancing its workload, a problem area that other teamsSee my previous paper review on Shard Manager. tackled since the original publish date of 2016. Lastly, it was useful to reflect on what Ambry doesn’t have - it’s key-value based approach to interacting with blobs doesn’t support file-system like capabilities, posing more of a burden on the user of the system (who must manage metadata and relationships between entities themselves).