micahlerner.com
Kangaroo: Caching Billions of Tiny Objects on Flash
Published December 11, 2021
Found something wrong? Submit a pull request!
The papers over the next few weeks will be from SOSP. As always, feel free to reach out on Twitter with feedback or suggestions about papers to read! These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed.
Kangaroo: Caching Billions of Tiny Objects on Flash
This week’s paper is Kangaroo: Caching Billions of Tiny Objects on Flash, which won a best paper award at SOSP - the implementation also builds on the CacheLib open source project. Kangaroo describes a two-level caching system that uses both flash and memory to cheaply and efficiently cache data at scale. Previous academic and industry researchSee the Flashield paper. demonstrates significant cost savings (around a factor of 10!) from hybrid memory/flash caches, but doesn’t solve the unique issues faced by small object caches that store information like tweets, social graphs, or data from Internet of Things devicesOne example of tiny objects caching is covered by my previous paper review on TAO: Facebook’s Distributed Data Store for the Social Graph ). Another unique property of Kangaroo is that it explicitly aims for different goals than those of persistent key-value stores (like Memcache, Redis, or RocksDB) - the system does not aim to be a persistent “source of truth” database, meaning that it has different constraints on how much data it stores and what is evicted from cache.
A key tradeoff faced by hybrid flash and memory caches is between cost and speed. This tradeoff manifests in whether caching systems store data in memory (DRAM) or on flash Solid State Drives. Storing cached data (and potentially the metadata about the cached data) in memory is expensive and fast. In contrast, flash storage is cheaper, but slower.
While some applications can tolerate increased latency from reading or writing to flashOne example of this is from Netflix’s caching system, Moneta. , the decision to use flash (instead of DRAM) is complicated by the limited number of writes that flash devices can tolerate before they wear outFlashield: a Hybrid Key-value Cache that Controls Flash Write Amplification also provides more context on the dollar and cents of a hybrid flash/memory cache. . This limit means that write-heavy workloads wear out flash storage faster, consuming more devices and reducing potential cost savings (as the additional flash devices aren’t free). To drive home the point about how important addressing this use case is, previous researchPrevious research has noted limits to write heavy workloads targeted at key-value stores like LevelDB and RocksDB. Additionally, A large scale analysis of hundreds of in-memory cache clusters at Twitter notes that 30% of Twitters caches are write-heavy yet existing research has predominantly focused on read-heavy workloads. to characterize cache clusters at Twitter noted that around 30% are write heavy!
Kangaroo seeks to address the aforementioned tradeoff by synthesizing previously distinct design ideas for cache systems, along with several techniques for increasing cache hit rate. When tested in a production-like environment relative to an existing caching system at Facebook, Kangaroo reduces flash writes by ~40%.
What are the paper’s contributions?
The paper makes three main contributions: characterization of the unique issues faced by small-object caches, a design and implementation of a cache that addresses these issues, and an evaluation of the system (one component of which involves production traces from Twitter and Facebook).
Challenges
Kangaroo aims to make optimal use of limited memory, while at the same time limiting writes to flash - the paper notes prior “flash-cache designs either use too much DRAM or write flash too much.”
Importantly, the paper differentiates how it is addressing a different, but related, problem from other key value systems like Redis, Memcache, or RocksDB. In particular, Kangaroo makes different assumptions - “key-value stores generally assume that deletion is rare and that stored values must be kept until told otherwise. In contrast, caches delete items frequently and at their own discretion (i.e., every time an item is evicted)”. In other words, the design for Kangaroo is not intended to be a database-like key-value store that stores data persistently.
Differences from key-value systems
The paper cites two problems that traditional key-value systems don’t handle well when the cache has frequent churn: write amplification and lower effective capacity.
Write amplification is the phenomenon “where the actual amount of information physically written to the storage media is a multiple of the logical amount intended to be written”Helpful article on the topic here. .
The paper notes two types of write amplification:
- Device-level write amplification (DLWA) is caused by differences between what applications instruct the storage device to write and what the device actually writesThe Flashield paper writes that “Device-level write amplification (DLWA) is write amplification that is caused by the internal reorganization of the SSD. The main source of DLWA comes from the size of the unit of flash reuse. Flash is read and written in small ( ̃8 KB) pages. However, pages cannot be rewritten without first being erased. Erasure happens at a granularity of groups of several pages called blocks ( ̃256 KB). The mismatch between the page size (or object sizes) and the erase unit size induces write amplification when the device is at high utilization.” .
- Application-level write amplification (ALWA) happens when an application intends to update a small amount of data in flash, but writes a larger amount of data to do so. This effect happens because flash drives are organized into blocks that must be updated as a whole. As an example, if a block of flash storage contains five items, and the application only wants to update one of them, the application must perform a read of all five items in the block, replace the old copy of an item with the updated version, then write back the updated set of all five items.
The other problem that key-value stores encounter under write-heavy workloads is lower effective capacity. Specifically, this impacts key-value stores that store data in flash. RocksDB is one example - it keeps track of key-value data using a logThe log contains files called LSM Trees, and there are great articles about how they work here and here. that is periodically cleaned up through a process called compaction. If RocksDB receives many writes, a fixed size disk will use more of its space to track changes to keys, instead of using space to track a larger set of keysThe lower effective capacity problem impacted Netflix’s implementation of a key-value datastore called EVCache, which stores data on flash using RocksDB. RocksDB stores data in files that represent a log of the changes made to the system. Eventually older sections of the log are removed from storage, using a process called compaction. Many writes to the system create more computational work for the compaction cleanup process. In Netflix’s case, they had to change their compaction process. .
Existing designs
There are two cache designs that the system aims to build on: log structured caches and set-associative caches.
Log structured caches store cached entries in a logMany also use a circular buffer. . Production usage of the approach includes CDNs and Facebook’s image caching serviceSee RIPQ: Advanced Photo Caching on Flash for Facebook . To allow fast lookups into the cache (and prevent sequential scans of the cached data), many implementations create in memory indexes tracking the location of entries. These memory indexes poses a challengeSee the Size Variability section of the CacheLib paper. when storing many small items, as:
The per-object overhead differs across existing systems between 8B and 100B. For a system with a median object size of 100B … this means that 80GB - 1TB of DRAM is needed to index objects on a 1TB flash drive.
Set associative caches, in contrast to log structured caches, do not have analagousIt is technically possible for set-associative caches to have them, but in memory indexes are not required as, “an objects possible locations are implied by its key.” in-memory indexes. Instead, the key associated with an object is used during lookup to find a set of items on flash storage. Unfortunately, set associative caches don’t perform well for writes, as changing the set associated with a key involves reading the whole set, updating the set, then writing the whole set back to flash (incurring application level write amplification, as mentioned earlier).
Design
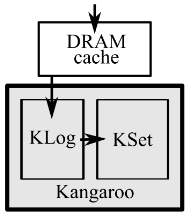
The Kangaroo system has three main components:
- A small DRAM Cache, which stores a subset of recently written keys.
- KLog which has 1) a buffer of cached data on flash and 2) an in-memory index into the buffer for fast lookups, similar to log structured cache systems.
- KSet which stores a set of objects in pages on flash, as well as a Bloom filterHere is a neat interactive tutorial on Bloom filters. used to track how set membership, similar to set-associative caches.
System Operations
Kangaroo uses the three components to implement two high-level operations: lookup and insert.
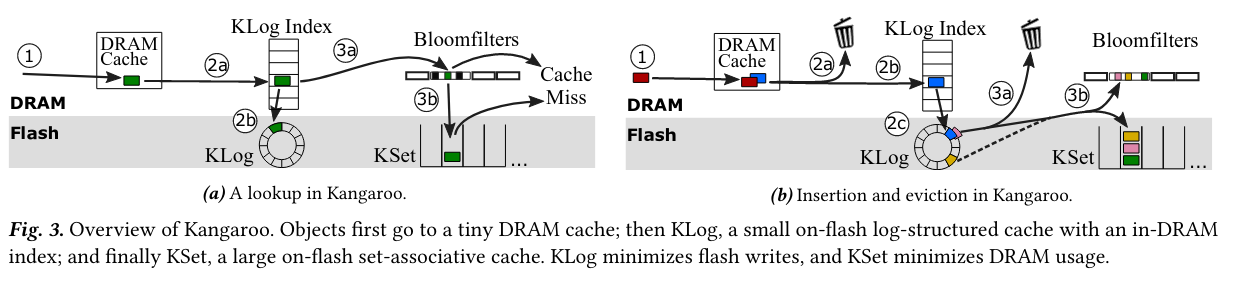
Lookups
Lookups get the value of a key if it is stored in the cache. This process occur in three main steps (corresponding to the three main components of the design).
First, check the DRAM cache. On a cache hit, return the value and on a cache miss, continue on to check the KLog.
If the key is not in the DRAM Cache, check the KLog in-memory index for the key to see whether the key is in flash, reading the value from flash on cache hit or continuing to check KSet on cache miss.
On KLog miss, hash the key used in the lookup to determine the associated KSet for the key. Then, read the per-set in-memory Bloom filter for the associated KSet to determine whether data for the key is likely‘Likely’ inserted here because Bloom filters are probabilistic. to exist on flash - if the item is on flash, read the associated set, scan for the item until it is found, and return the data.
Inserts
Inserts add a new value to the cache (again in three steps that correspond to the three components of the system).
First, write new items to the DRAM cache. If the DRAM Cache is at capacity, some items will be evicted and potentially pushed to the KLog. Kangaroo doesn’t add all items evicted from the DRAM Cache to the KLog, as making this shift can incur writes to flash (part of what the system wants to prevent). The algorithm for deciding what is shifted is covered in the next section.
If Kangaroo chooses to admit the items evicted from the DRAM Cache to the KLog, the system updates the KLog in-memory index and writes the entry to flashThe paper notes that writes to flash are actually buffered in memory - in a write-heavy system it is possible that the entries that make it to the KLog are quickly evicted.
Writing an item to KLog has the potential to cause evictions from the KLog itself. Items evicted from the KLog are potentially inserted into an associated KSet, although this action depends on an algorithm similar to the one earlier (which decides whether to admit items evicted from the DRAM Cache to the KLog). If items evicted from the KLog are chosen to be inserted into a associated KSet, all items both currently in the KLog and associated with the to-be-written KSet are shifted to the KSet - “doing this amortizes flash writes in KSet, significantly reducing Kangaroo’s [application-level write amplification]”.
Implementation
The implementation of Kangaroo couples a DRAM Cache, KLog, and KSet with three key ideas: admission policies, partitioning of the KLog, and usage-based eviction.
As mentioned earlier, items from the DRAM Cache and KLog are not guaranteed to be inserted into the next component in the system. The decision whether to propagate an item is decided by a tunable admission policy that targets a certain level of writes to flash. The admission policy for DRAM Cache to KLog transitions is probabilistic (some percent of objects are rejected), while the policy controlling the KLog to KSet transition is based on the number of items currently in the KLog mapping to the candidate KSetUpdating a KSet requires writing many (or all) of the objects in a set, so only making a few updates may not be not worth it. .
Next, partitioning the KLog reduces “reduces the per-object metadata from 190 b to 48 b per object, a 3.96× savings vs. the naïve design.” This savings comes from changes to the pointers used in traversing the index. One example is an offset field that maps an object to the page of flash it is stored in:
The flash offset must be large enough to identify which page in the flash log contains the object, which requires log2(𝐿𝑜𝑔𝑆𝑖𝑧𝑒/4 KB) bits. By splitting the log into 64 partitions, KLog reduces 𝐿𝑜𝑔𝑆𝑖𝑧𝑒 by 64× and saves 6 b in the pointer.
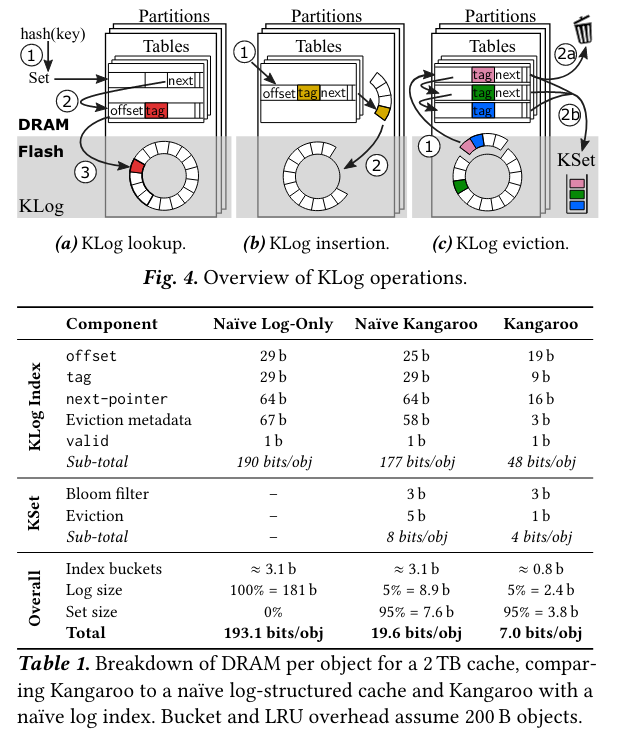
Lastly, usage-based eviction ensures infrequently-used items are evicted from the cache and is normally based on usage metadata - given fixed resources, these types of policies can increase cache hit ratio by ensuring that frequently accessed items stay in cache longer. To implement the idea while using minimal memory, Kangaroo adapts a technique from processor caches called Re-Reference Interval Prediction (RRIP), (calling its adaptation RRIParoo):
RRIP is essentially a multi-bit clock algorithm: RRIP associates a small number of bits with each object (3 bits in Kangaroo), which represent reuse predictions from near reuse (000) to far reuse (111). Objects are evicted only once they reach far. If there are no far objects when something must be evicted, all objects’ predictions are incremented until at least one is at far.
RRIParoo tracks how long ago an item was read as well as whether it was read. For items in KLog, information about how long ago an item was read is stored using three bits in the in-memory index.
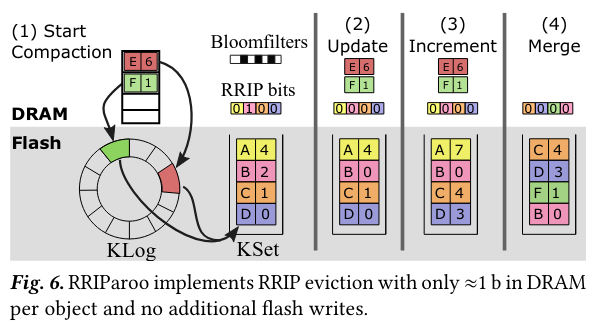
In contrast, usage data for items in KSet is stored in flash (as KSet doesn’t have an in-memory index). Each KSet also has a bitset with one bit for every item in the KSet that tracks tracks whether an item was accessed - this set of single-bit usage data can be used to “reset” the timer for an item.
Evaluation
To evaluate Kangaroo, the paper compares the system’s cache miss ratio rate against other cache systems and deploys it with a dark launch to production.
Kangaroo is compared to a CacheLib deployment designed for small objects, and to a log-structured cache with a DRAM index. All three systems run on the same resources, but Kangaroo achieves the lowest cache miss ratio - this, “is because Kangaroo makes effective use of both limited DRAM and flash writes, whereas prior designs are hampered by one or the other.”
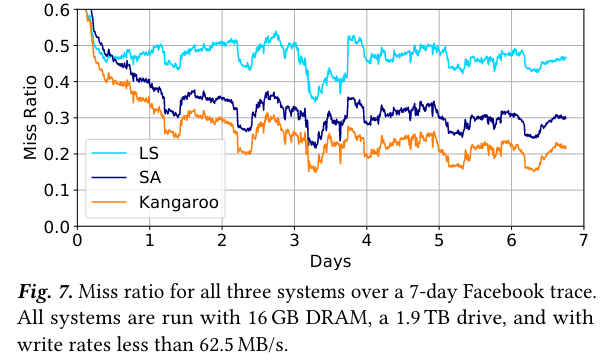
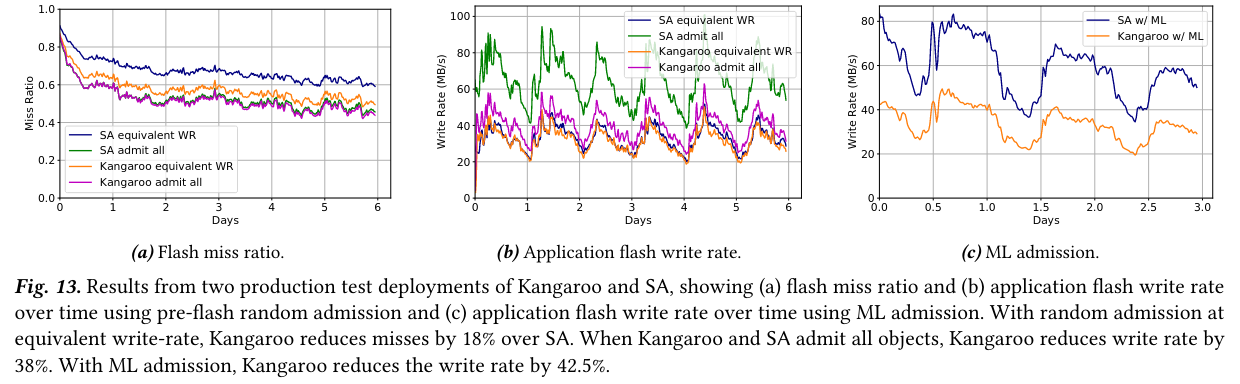
Kangaroo was dark launched to production inside of Facebook and compared with an existing small object cache - Kangaroo reduces flash writes and reduces cache misses. Notably, the Kangaroo configuration that allows all writes performs the best of the set, demonstrating the potential for operators to make the tradeoff between flash writes and cache miss ratio (more flash writes would be costlier, but seem to reduce the cache miss ratio).
Conclusion
The Kangaroo paper demonstrates a unique synthesis of several threads of research, and the tradeoffs caching systems at scale make between cost and speed were interesting to read. As storage continues to improve (both in cost and performance), I’m sure we will see more research into caching systems at scale!
As always, feel free to reach out on Twitter with feedback. Until next time.