micahlerner.com
Shard Manager: A Generic Shard Management Framework for Geo-distributed Applications
Published January 08, 2022
Found something wrong? Submit a pull request!
Discussion on Hacker News
This is one of the last papers I’m writing about from SOSP - I am trying out something new and publishing the queue of papers I plan on reading here. These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
Shard Manager: A Generic Shard Management Framework for Geo-distributed Applications
This week’s paper is Shard Manager: A Generic Shard Management Framework for Geo-distributed Applications. The research describes a framework developed by Facebook for running sharded applications at scale.
Application shardingIn the context of Shard Manager. assigns subsets of requests to instances of an application, allowing tasks to specialize - a group of tasks specialized for a subset of requests is called a shard.
This approach is particularly useful when tasks fetch state or other metadata. As an example, a speech recognition application may load machine learning models to process languages. Assigning requests for different languages to different shards means that an application’s tasks don’t need to download every model (which would be time and bandwidth-intensive).
The Shard Manager paper not only discusses the technical aspects of running a sharding system at scale, but also includes data on usage and adoption inside Facebook. The paper’s information about which features were critical for users inside Facebook could help future efforts prioritize@rakyll has a great article about a potential implementation. .
What are the paper’s contributions?
The Shard Manager paper makes five main contributions: analysis of sharding usage at Facebook, design and implementation of the sharding system, a domain-specific language for defining sharding constraints, a constraint solver to place shards inside Facebook’s data centers, analysis of sharding usage at Facebook, and an evaluation of the system in production.
Motivation
The paper notes three main motivations for implementing Shard Manager: increasing availability, supporting geo-distributed applications, and improved load balancing.
To increase availability, Shard Manager aims to smoothly handle planned data center maintenanceFacebook recently published a paper on their cluster manager, Twine - if a container stops while processing user requests, those requests will fail, impacting the availability of the application. For the vast majority of containers, Facebook’s infrastructure knows in advance that the container is shutting down. Shard Manager aims to smoothly handle these shutdown events by coordinating with the container infrastructure, ensuring that to-be-shutdown containers stop receiving requests, and that requests that do make it to a shutting down container are forwarded to another active instance.
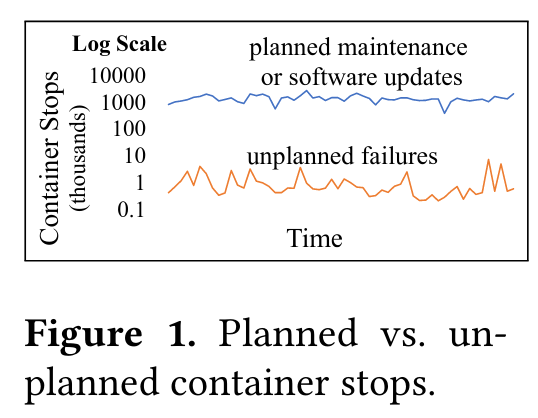
The second major motivator for Shard Manager is enabling geo-distributed applications (an approach to independently deploying and scaling application shards). Before Shard Manager, services were primarily configured with regional deployments - to operate at Facebook scale, applications need to run in groups of datacenters called regions, with similar configurations in each region. For a sharded application, this meant reserving enough resources to serve every shard in every region, even if the shards weren’t needed - this constraint led to wasted data center resources. Furthermore, regional deployments were unwieldy in the event of data center or region maintenance, as other regions might not have the spare capacity to store additional copies of every shard.

Improved load balancing is the third main motivation for Shard Manager. Geo-distributed applications can flexibly add and shift shards independently, simplifying the process of shifting load - rather than needing to make a copy of every shard, the system can add or move specific shards. At the same time, deciding when and how to place shards is a difficult optimization problem that Shard Manager needed to address.
Design
The Sharding Abstraction
A critical piece of a sharding framework is assigning requests to shards. Shard Manager uses client-provided keys, called app-keys, to perform this mapping - continuing with the language server example, requests for English are sent to X shard, while requests for German and Mandarin might be sent to Y and Z shards.
The paper also discusses another approach, called UUID-keys, that map requests to shards based on hashes of keys provided by clients.
There are pros and cons to using app-keys versus UUID-keys, mostly based around data-locality - in the context of shard manager, data-locality means that similar data, potentially from related users or regions of the world, is placed on the same or nearby shards. The paper argues that app-keys provide data-locality, while UUID-keys do not.
Data locality would enable features like sequentially scanning multiple shards when performing a query. At the same-time, data locality could increase the potential for hot-spots, where reads of similar data all go to the same shard. Previous approaches to sharding frameworks, like SlicerSee the paper on Slicer here. , mention adding support for an app-key like approach to preserve data locality, but mention that, “many Google applications are already structured around single-key operations rather than scans, encouraged by the behavior of existing storage systems.”
Architecture
There are three main components of the Shard Manager architecture: application clients/servers, a control planeControl plane is used because it is the layer that performs management and metadata storage operations. , and the Cluster Manager.
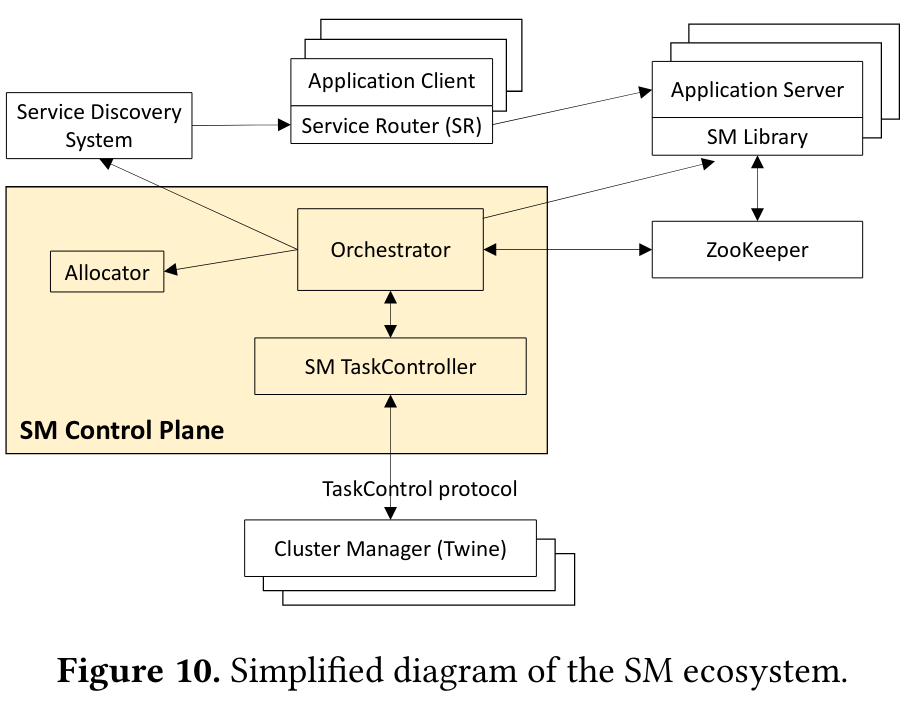
Application servers are the actual binaries that operate shards and receive requests from clients. Each server has a library that allows it to manage shard state (like reporting server health), register/deregister the shard from receiving requests, and hook into shard management events. When a shard performs management operations, it writes state to ZookeeperIt would be interesting to hear if Shard Manager considered adopting Delos, a system for storing control plane data discussed in a previous paper review. , a persistent data store.
To call an application server, an application client uses a library (called a Service Router). The client’s Service Router routes requests based on an app-key (which defines the mapping from request to shard), selecting an available shard based on state the library consumes from a service discoverySee this article on service discovery for more background. system. The Service Router periodically polls in the background to receive updates as shards are added, removed, and scaled.
The control plane of Shard Manager has three components:
- Orchestrator: an intermediary component that receives health and load information from application servers. It shares this data with other members of the control plane (like the components that schedule and scale shards), and propagates it to the Service Discovery System so that application clients have an updated view of the system.
- Allocator: which decides where to put shards and how many to run.
- TaskController: commmunicates with the Cluster Manager to request more resources (when scaling shards up) or to receive system events, like pending maintenance (which the Task Controller uses to shutdown shards gracefully). The TaskController propagates this information to the Orchestrator so that it can fulfill the job of shutting down application servers and shards gracefully.
Lower in the infrastructure stack is the Cluster ManagerFor more information on the Cluster Manager, see the Twine paper. , which communicates with the TaskController above to ensure that planned events, like “upcoming hardware maintenance events, kernel updates, and container starts/stops/moves” are handled gracefully, increasing application availability.
Implementation
The paper discusses how Shard Manager features aim to increase application availability and supporting geo-distributed applications, while scaling the system.
Maximize Application Availability
Shard Manager implements two main techniquesThe paper also mentions shard distribution across fault domains (like multiple regions and data centers) as increasing availability, but I defer discussion of shard distribution to placement and load balancing. to increase application availability: coordinating container shutdown with the Cluster Manager, and migrating shard traffic.
Coordinating container shutdown is critical to increasing availability because it ensures requests are not sent to a container that might shutdown while responding. Shard Manager must also ensure that planned maintenance events don’t take too much capacity offline at once (which would leave the application in a state where it is unable to respond to all incoming requests). To prevent both of these situations, Shard Manager’s TaskController communicates with the Cluster Manager, removing imminently decommissioning shards from service discovery and launching new shards as others prepare to go offline. If it is not possible to shift shards in anticipation of maintenance, the the Task Controller can warn the Cluster Manager that the proposed operations would put an application in an unsafe state.
Shard Manager also supports migrating shard traffic by implementing a graceful handover procedure. This process forwards in-progress requests from the old to new shard, ensuring that as few as possible are dropped on the floor. The system’s traffic migration also aims to handoff any new requests from application clients, who may continue to send requests to the old shard - the service discovery system is eventually consistentSee this blog post from Amazon’s Werner Vogels on eventual consistency. , so clients may temporarily use out-of-date routing state.
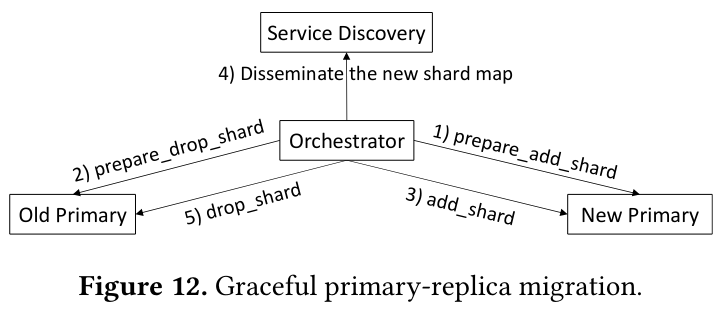
Shard Placement and Load Balancing
Geo-distributed applications allow shards to be deployed independently to Facebook’s infrastructure around the world. While the technique provides several benefits, like independent scaling of individual shards, it also poses its own challenges - choosing how to place shards and when to move them is a difficult optimization problem. To solve the optimization problems associated with placement and load balancing, Shard Manager uses a constraint solver, configurable with a dedicated language for expressing constraints.
Shard Manager originally used a heuristic-based implementation to make load balancing decisions, which proved both complicated and difficult to scale. As a result, the system migrated to a constraint solverThe paper mentions a number of optimization techniques, including mixed integer programming (MIP), genetic algorithms, and simulated annealing. I’m far from an expert in this type of research, so this could be a potential topic for a future paper review. .
The inputs to the solver are constraints and goals - example constraints are system stability or server capacity, while example goals are load balancing across regions (to increase resource utilization) or spreading replicas across multiple data centers (to increase availability in the event of a problem with a specific data center).

An application configures its placement and load balancing using a domain-specific languageThere is some very interesting and related research from VMWare on programmatically configuring cluster managers Building Scalable and Flexible Cluster Managers Using Declarative Programming. that translates into a form that a constraint solver can use. Even though Facebook has a high-powered constraint solver for data center problemsThe paper links to another Facebook paper from SOSP on RAS: Continuously Optimized Region-Wide Datacenter Resource Allocation. , Shard Manager made further optimizationsThe paper mentions Local Search, which “has grown from a simple heuristic idea into a mature field of research in combinatorial optimization that is attracting ever-increasing attention.” to scale for its the high request rate.
Scaling Shard Manager
To scale Shard Manager, the system introduced two new concepts:
- Partitions: Each application is divided into many partitions, “where each partition typically comprises thousands of servers and hundreds of thousands of shard replicas.”
- mini-Shard Managers (mini-SM), which are essentially copies of an individual shard manager control plane (mentioned in a previous section). Each mini-SM handles a subset of servers and shards.
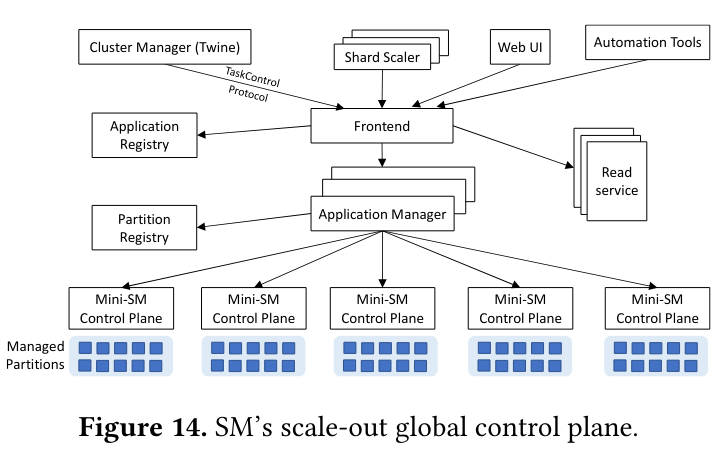
The scale-out“Scale-out” in this context means adding more mini-Shard Managers to cover more machines, as trying to make a single Shard Manager cover many machines would be difficult version of Shard Manager also adds several new components including a frontend that serves as a balancer for communication with external systems (like the Cluster Manager and tooling), Application Managers that handle coordination of an application’s partitions over multiple mini-SMs, and a partition registry that Application Managers communicate with to get assignments of application partitions to mini-SMs.
Analysis of Sharded Applications
Shard Manager aims to provide support for as many sharded applications inside Facebook as possible, and provides data points what was critical to driving adoption. The paper argues for the importance of features in two areas that align with project’s motivation: increasing availability and geo-distributed deployments.
Many applications that migrated to Shard Manager take advantage of its availability features, in particular around handling planned events - “70% of SM applications choose to gracefully drain shards before a container restart.”

The paper also notes similarly high-adoption of geo-distributed applications - 67% of sharded applications using Shard Manager use geo-distributed deployments.
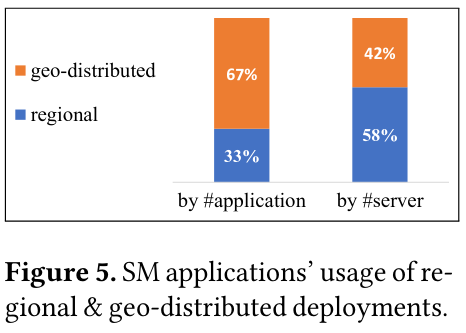
Evaluation
The paper evaluates Shard Manager using three criteria: whether the system succeeds at scale, whether it is able to achieve the original goals of increasing application availability and supporting geo-distributed applications, and whether Shard Manager can adequately solving the optimization problems to load-balance.
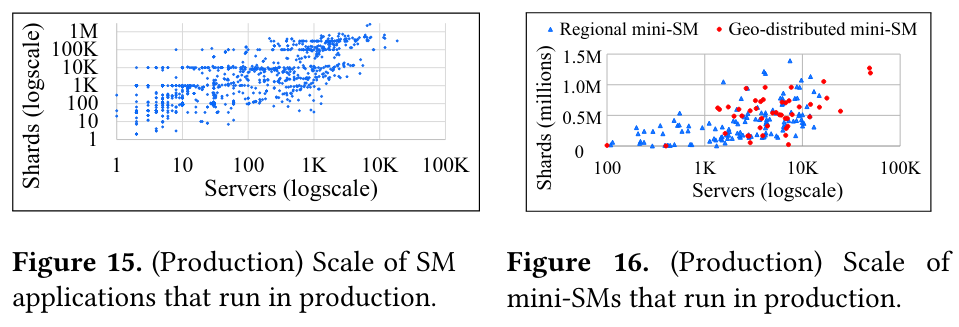
To evaluate scale, Shard Manager shows the number of applications, shards, and mini-SMs, demonstrating that the architecture is able to scale out as needed:
In total, SM manages hundreds of applications’ nearly 100M shards hosted on over one million servers, and those applications process billions of requests per second. SM gracefully handles millions of machine and network maintenance events per month.
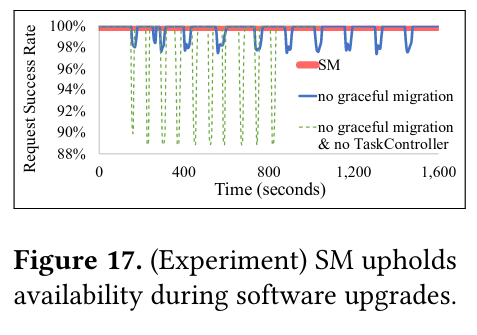
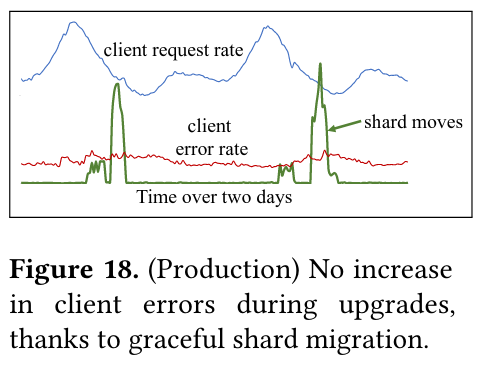
To evaluate availability, Shard Manager shows that applications using graceful migration show fewer spikes of failed requests relative to those that use no graceful migration strategy. The paper also shows how shard upgrades do not cause an increase in client error rate.
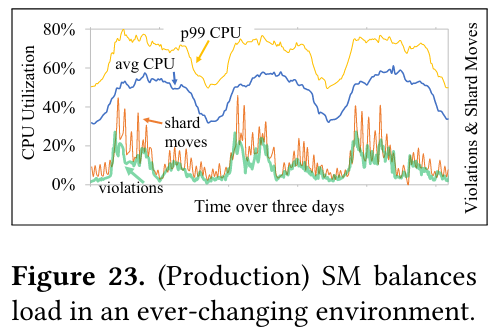
To evaluate load balancing, the paper shows migrating shards to reduce network latency and load balancing over a changing environment and request rate.
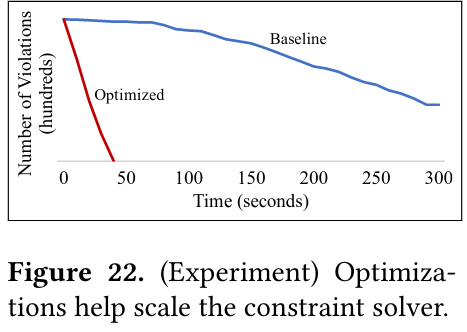
Lastly, the paper shows how the improved constraint solver is able to solve constraints at a much faster rate than the baseline solver - in fact, the original baseline solver isn’t able to complete.
Conclusion
The Shard Manager paper details an impressive at scale production system, while sharing data points that will be useful to future implementers of sharding frameworks. I particuarly enjoyed how the paper discussed adoption and internal usecases when prioritizing development - I’ve seen this theme in a number of Facebook research papers, including Delos (which I previously covered here) and RocksDB. I’m also looking forward to future work from folks interested in an open source sharding framework, like the one @rakyll outlined!
As always, I appreciated feedback and paper suggestions on Twitter. Until next time!