micahlerner.com
Breakfast of Champions: Towards Zero-Copy Serialization with NIC Scatter-Gather
Published July 07, 2021
Found something wrong? Submit a pull request!
This week’s paper is from HotOS 2021. Many of the HotOS papers (like this one) propose future directions for Operating Systems research, in addition to including prototypes (in contrast with other papers that focus on a single system’s implementation). The full proceedings of the conference are here - as always, if there are any papers that stick out to you, feel free to reach out on Twitter.
Breakfast of Champions: Towards Zero-Copy Serialization with NIC Scatter-Gather Deepti Raghavan, Philip Levis, Matei Zaharia, Irene Zhang.
This paper (written by authors from Stanford and Microsoft Research) focuses on how to speed up data serialization associated with Remote Procedure Call (RPC)Martin Kleppman, the author of the amazing ‘Designing Data-Intensive Applications’ has a useful lecture on RPC here. systems in the datacenter. Normally, RPC systems are not focused on as a performance bottleneck, but the authors argue that as we enter the “microsecond era”The microsecond era refers to a time when ‘low-latency I/IO devices, ranging from faster datacenter networking to emerging non-volatile memories and accelerators’ are used more widely in industry. A shorter intro is here , the performance of previously overlooked systems will standout - CPU will become a scarce resource as data center networks become even faster.
RPC systems (like gRPC and Apache Thrift) are very popular, but use CPU cycles to move memory in the process of reading data from or writing data to the network. This overhead comes from “coalescing or flattening in-memory data structures” - taking application objects that may contain pointers to separate areas of memory and moving the associated data into a contiguous area of memory (so that the combined object can be sent over the network).
To limit (and possibly eliminate) this overhead, the authors suggest leveraging functions of commodity Network Interface Cards (NICs) with built in support for high performance computing primitivesThe paper includes benchmarks from using a Mellanox NIC - see here for a discussion of how Mellanox can accelerate MPI operations. . The primitive focused on in the paper is scatter-gatherSpecializing the network for scatter-gather workloads describes a number of use cases for scatter-gather, for example: “Web services such as search engines often involve a user-facing server receiving a user request, and in turn, contact hundreds to thousands of back-end servers, e.g.,for queries across a distributed search index”. , which bears a strong resemblance to the function that the authors are trying to optimize (gathering disparate memory to a single location or taking a contiguous piece of memory and distributing it):
Scatter-gather was designed for high-performance computing, where applications frequently move large, statically-sized chunks of memory between servers.
Even though some NICs support scatter-gather, an extra step (called kernel bypass) can be taken to ensure that there are no (or at least limited) memory copies made in the serialization/deserialization process. Kernel-bypass is used to build high-speed networking stacks, for example at Cloudflare. The technique can make IO devices (like a NIC) available to user-space, ensuring that no unncessary memory movement in or out of the kernel occursThis video contains an in-depth explanation of kernel-bypass for high-speed networking. One of the authors of the paper (Irene Zhang), also has an interesting paper on a system that provides abstractions for kernel-bypass: I’m Not Dead Yet! The Role of the Operating System in a Kernel-Bypass Era. .
What are the paper’s contributions?
The paper makes three main contributions: it explores the sources of RPC serialization (and deserialization) overhead, proposes a solution to limiting that overhead, and outlines potential areas of research in the future to expand on the proposed approach.
The Limits of Software Serialization
To explore performance issues with software serialization (software serialization because no extra hardware, like an accelerator, is used), the paper includes two experimental results that highlight the reasons that CPU-based serialization is inefficient - flattening, moving, and copying data when performing RPC operations incurs CPU cycles.
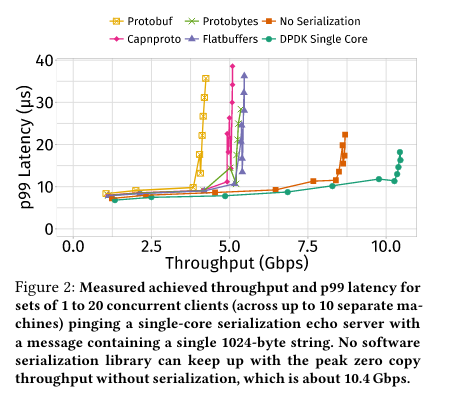
The first experiment shows the limits of different RPC serialization/deserialization implementations for a server that is deserializing and serializing a 1024 byte string messageA simple string message was chosen because it is a can represent “the minimal overhead for serialization today.” (where the limit is the latency associated with a given throughput). Predominantly all of the implementations are grouped together on the performance graph, with three important gaps.
First, Protobuf performs poorly relatively to the other RPC libraries (as it performs UTF-8 validation on the string message).
The next gap is between an implementation using DPDKDPDK stands for “Data Plane Development Kit”, and is a software library that allows for NICs to be programmed from user-space, facilitating high speed networking through bypassing the kernel. single core and the RPC libraries. The serialization libraries need to make copies when encoding to or decoding from a wire format (see graph below for a comparison between Protobuf and Cap’n Proto in this regard), and these extra copies mean lower peak throughput (because CPU cycles are spent on moving the memory). In contrast, the DPDK line indicates what would be possible performance wise if serialization libraries could manipulate shared memory with the networking stack, in turn limiting memory copies. This line sets the benchmark for what would be possible in a world where RPC libaries limited copies by integrating with a kernel-bypass library.
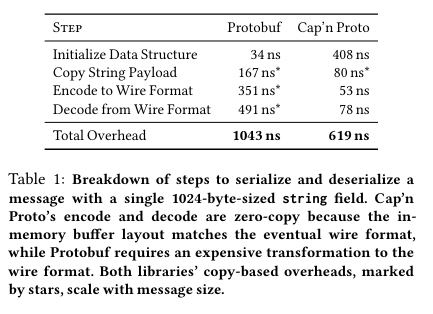
The second experiment is included above - it shows how both Protobuf and Cap’n Proto incur copies when performing serialization/deserialization (and the time for each grow with the size of the message).
Leveraging the NIC for Serialization
Before introducing the scatter-gather based implementation, the paper explores the performance of splitting up a payload into differently sized chunks. This experiment uses an echo server benchmark (where a client serializes a message and sends it to a server, which returns it to the client), with the results indicating that objects below a threshold size of 256 bytes do not benefit from a zero-copy scatter-gather approach. Dividing up a payload into smaller packets can hurt performance if the packets are too small relative to the overhead of the NIC building them (where the definition of “too small” varies with the model of NIC being used, a topic that will come up in the next sectionEach scatter/gather chunk of memory is an expensive NIC-to-PCIe round-trip. Different NICs will be able to parallelize fewer or more of these calls. ).

To use a NIC’s scatter-gather functionality to speed up serialization/deserialization, the paper implements a datastructure called a ScatterGatherArray that contains a count of the number of entries, a list of pointers, and the size of each entry - “when applications call serialize, the library produces a scatter-gather array that can be passed to the networking stack instead of a single contiguous buffer”. An associated header contains a bitmap of which fields in the ScatterGatherArray are filled and metadata about the type of the field. When serializing an object, the “resulting wireformat is similar to Cap’n Proto’s wireformat.”
The paper additionally includes details of deserializing an object. I won’t include full details on deserialization (as they are readily accessible in the paper), but there are several interesting features. For one, the paper discusses pros of a potentially different wire format where information on all fields is stored in the header (in contrast to the implementation which has a header that only includes metadata on a field if it is present) - if all fields are stored, the header would likely be larger, but deserialization could be constant time, rather than requiring a scan of all fields in the header.
Most importantly, the prototype using NIC scatter-gather, kernel-bypass, the ScatterGatherArray, and the wireformat almost reach DPDK single-core performance benchmark from the first experiment outlined in “The Limits of Software Serialization_ above:
The prototype implementation achieves about 9.15 Gbps (highest throughput measured under 15μs of tail latency). The prototype’s performance improves on all the serialization libraries and the 1-copy (”No Serialization”) baseline, but falls about 1.2 Gbps short of the optimal DPDK throughput.
Open Research Challenges
There are four main research challenges associated with combining NIC scatter-gather with serialization libraries:
- NIC support for scatter gather: the costs of sending payloads using NIC scatter-gather aren’t worth it if the payloads are below a threshold size. Can NICs be designed with this in mind?
- Using scatter-gather efficiently: Different application payloads may or may not work well with different NICs, as different NICs have different performance profiles with small or oddly sized payloads
- Accessing Application Memory for Zero-Copy I/O: Memory that is shared between the NIC and user-space must be pinned, meaning that large amounts of memory could be reserved for an application, but may never be used (or used rarely). Managing what memory is pinned, when it is pinned, and how it is allocated are all active areas of developement (with papers linked to by the authors), as a user of the approach wouldn’t want to incur enormous overhead.
- Providing Zero-Copy I/O with Memory Safety: If the NIC and CPU are both interacting with memory concurrently, they will need a way to do so safely. Other challenges include implementing a way for deserialized responses to be reclaimed once an application is done using them (otherwise the response will stay in memory, which will eventually run out).
Conclusion
Kernel-bypass and the microsecond era are leading to an exciting time in systems as researchers figure out how to rework existing systems and ensure high performance. Accelerators (and abstracting away the use of them) is an area I hope to cover more in the future. While this paper is a slight deviation from the types of papers that I’ve previously reviewed on this blog, I hope you enjoyed it - if you have feedback feel free to ping me on Twitter. Until next time!
Thanks to Pekka Enberg for reading a draft of this post!