micahlerner.com
Data-Parallel Actors: A Programming Model for Scalable Query Serving Systems
Published June 04, 2022
Found something wrong? Submit a pull request!
Discussion on Hacker News
After this paper, I’ll be switching gears a bit and reading/writing about papers from NSDI 2022. These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
Data-Parallel Actors: A Programming Model for Scalable Query Serving Systems
What is the research?
The research describes an actor-based frameworkActors are a programming paradigm where one deploys multiple independent units that communicate through messages - here is one resource on the approach. for building query-serving systems, a class of database that predominantly respond to read requests and frequent bulk writes. The paper cites several examples of these systems, including Druid (covered in a previous paper review) and ElasticSearch.
The paper argues that query-serving systems are a common database deployment pattern sharing many functionalities and challenges (including scaling in cloud environments and recovery in the face of failure). Rather than relying on shared implementations that enable database scaling and fault tolerance, query-serving systems often reinvent the wheelOr choose not to provide functionality. . Custom implementations incur unnnecessary developer effort and require further optimizations beyond the initial implementation. For example, Druid clusters provide scaling using a database-specific implementation, but often end up overprovisioningThe paper cites Popular is cheaper: curtailing memory costs in interactive analytics engines, an article about Yahoo/Oath’s efforts to improve the provisioning of their Druid cluster. . Sometimes query-serving systems take a long time to develop their own implementation of a feature - for example, Druid’s implementation of joinsDruid’s join support was proposed in 2019, many years after the project’s initial release. , and MongoDB’s implementation of consensusMongoDB replication is covered by Fault-Tolerant Replication with Pull-Based Consensus in MongoDB, which is very interesting in and of itself. :) .
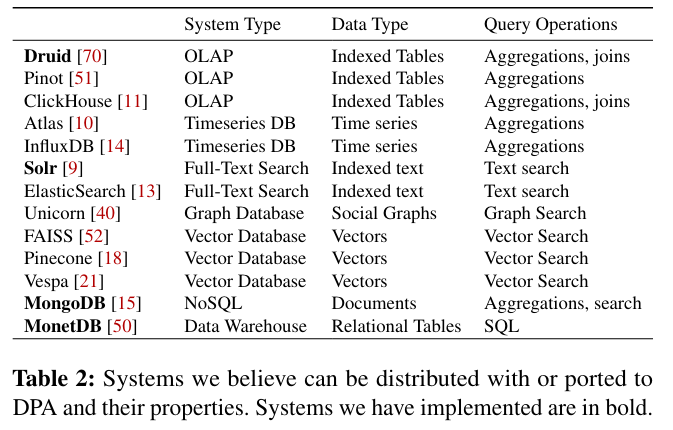
The DPA paper aims to simplify development, scaling, and maintenace of query-serving systems, using a runtime based on stateful actors. While the idea of building distributed systems on top of stateful actors is not necessarily newExamples of using stateful actors exist in Orleans and Ray. , implementing a database runtime targeted at a common class of databases (query-serving systems) is novel.
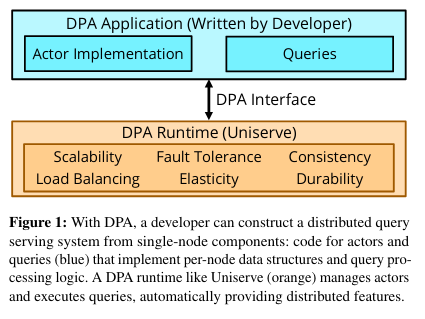
What are the paper’s contributions?
The paper makes three main contributions:
- Identifying and categorizing query-serving systems, a class of databases supporting “low-latency data-parallel queries and frequent bulk data updates”
- A Data Parallel Actor (DPA) framework aimed at simplifying the implementation of query-serving systems using stateful actors.
- Porting several query-serving systems to the Data Parallel Actor paradigm, then evaluating the performnace of the resulting implementations.
How does the system work?
Actors and Data
Actors are a key component of the DPA framework - several ideas from existing databases are reworked to fit an actor-based model, in particular partitioning, writes, and reads.
Many databases use partitioning to address problems related to fault tolerance, load balancing, and elasticityPartitioning a dataset increases fault tolerance because a partitioned dataset can be scaled by adding more copies of each partition - if any one of them fails, requests can be forwarded to another copy. The paper cites the Shard Manager paper (covered by a previous paper review), when discussing this idea of forwarding requests. A partitioned dataset is also easier to load balance because partitions can be shifted independently away from hotspots, distributing load across more machines. Lastly, partitioning increases elasticity by facilitating capacity increases in response to additional load - new machines can be started, each containing additional copies of partitions. . DPA adapts partitioning by assigning partitions of a dataset to an actor. Actors manage partitions using a limited set of methods (including create, destroy, serialize, and deserialize) that a database developer implements according to the internals of their project.
The paper describes several advantages to the actor-based approach - in particular, building a distributed database on top of the DPA-based actor abstraction simplifies the implementation of fault tolerance, load balancing, and elasticity that databases would otherwise build themselves (or not at all). Rather than each query-serving system custom-writing these featuresets, the DPA framework handles them. In turn, the main component that developers become responsible for is implementing the Actor interface with the DPA framework.

Write handling
To handle writes, a query-serving system based on DPA implements an UpdateFunction (accepting parameters like the table to be updated, the records to change or add, and the consistencyConsistency relates to how data updates are processed and reflected in the system - for example, does the system fail a transaction if some of its writes fail? The Jepsen content is one of the resourcs I commonly reference. If you like any other resources on the topic feel free to send a pull request! of the update). The DPA framework then determines which actors need to be updated (and how) under the hood. Importantly, DPA supports building query-serving systems with different consistency guarantees, from eventually consistent to full serializability - depending on the consistency level chosen, the update has different behavior. This configurability is useful because consistency requirements vary by query-serving system.
Read handling
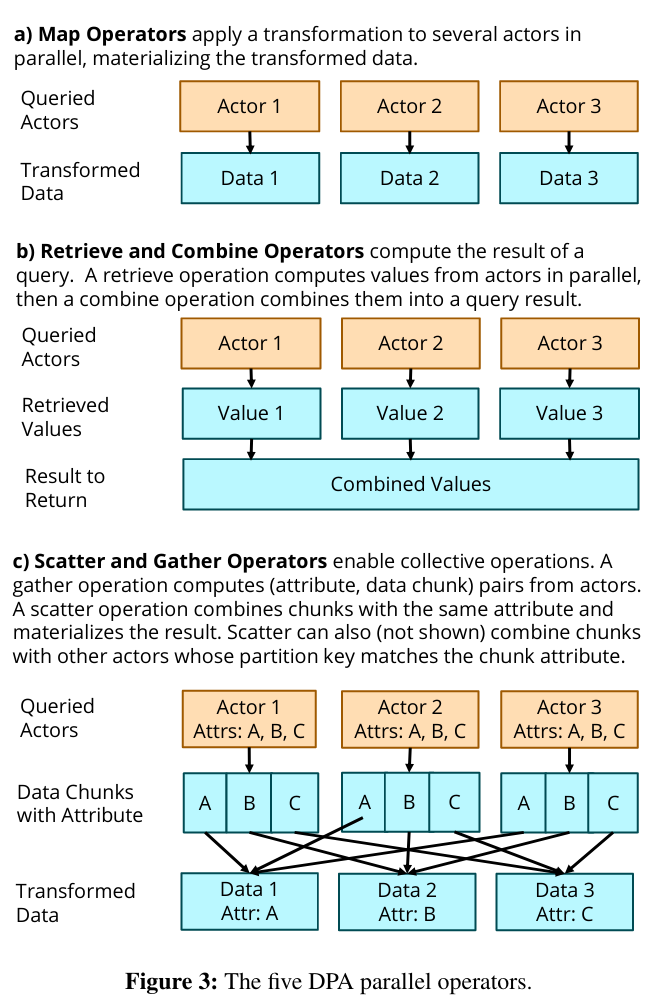
To handle reads, DPA uses a client layer for receiving queries. The client layer converts queries into ParallelOperators that can be run across many actors as needed. Example of ParallelOperators are Map (which “applies a function to actors in parallel and materializes the transformed data.”), and Scatter and Gather (a “collective” operation used in functionality like like joins).
Architecture
The DPA paper discusses a runtime (called Uniserve) for running query-serving systems using an actor-based model. The runtime has four high-level components: a query planner, a client layer, the server layer, and a coordinator.
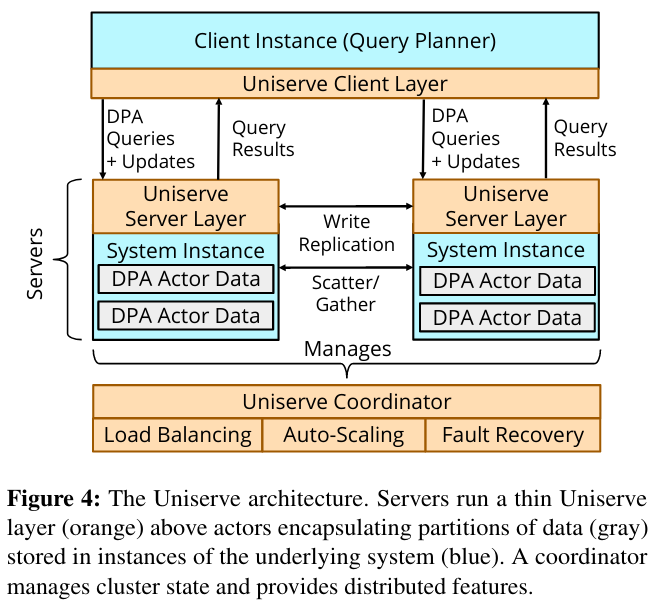
The query planner is responsible for receiving queries from clients, and “translates them to DPA parallel operators (or update functions)” - in other words, determining which partitions and actors the query needs to access. The paper discusses how developers can (or need to) implement the query planner themselves, which seemed related to the idea of creating a general query planner (discussed in existing research like F1).
The client layer communicates with the query planner, fanning out subqueries to the deeper layers of the Uniserve stack - in particular the nodes with actors and the partitions they are associated with.
Actors (and the partitions they are responsible for) live in the Uniserve Server Layer. There are many nodes in this layer, each with several actors and their associated partitions. The nodes in this layer communicate with one another in order to execute queries (like Scatter and Gather operations) and replicate data from one actor to another as needed.
Lastly, the allocation of actors to servers is handled by the coordinator. The coordinator scales the system by adding or removing servers/actors in response to demand, in addition to managing fault tolerance (by ensuring that there are multiple replicas of an actor, all of which converge to the same state through replication).
How is the research evaluated?
In addition to establishing the paradigm of DPA, the paper also discusses how several existing databases were ported to the approach, including Solr, MongoDB, and Druid. The implementations of these databases on DPA is significantly shorter with respect to lines of code:
DPA makes distributing these systems considerably simpler; each requires <1K lines of code to distribute as compared to the tens of thousands of lines in custom distribution layers (~90K in Solr, ~120K in MongoDB, and ~70K in Druid).
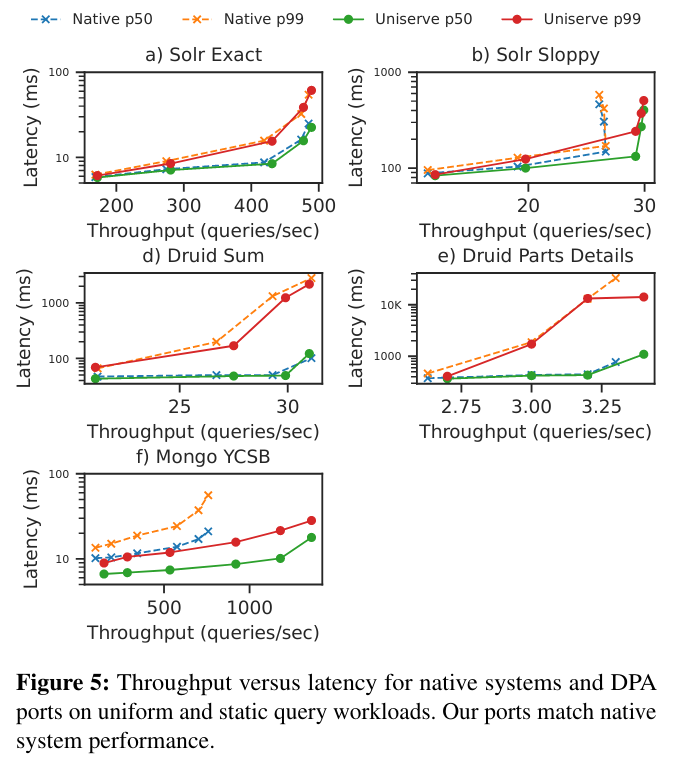
The paper also measures overheads associated with the DPA model by comparing native systems to the comparable system on DPA, finding that the approach adds minimal overhead.
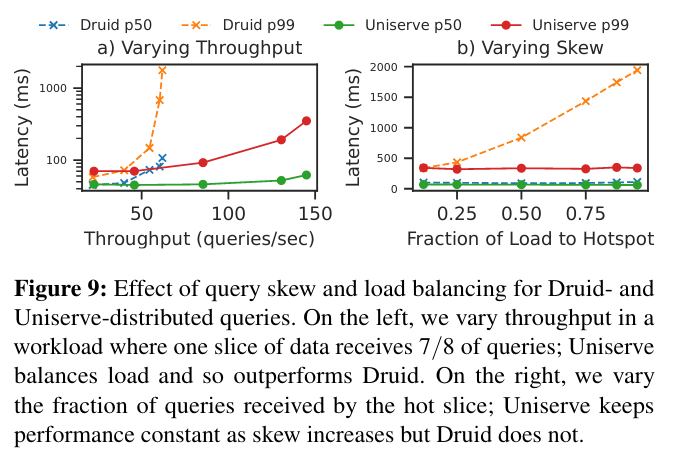
Another key feature of DPA is its ability to generally load balance actors and partitions. To test this behavior, the system executed skewed queries that introduce “hot spots” in the cluster - the coordinator component is able to dissipate “hot spots” across machines while scaling actors.
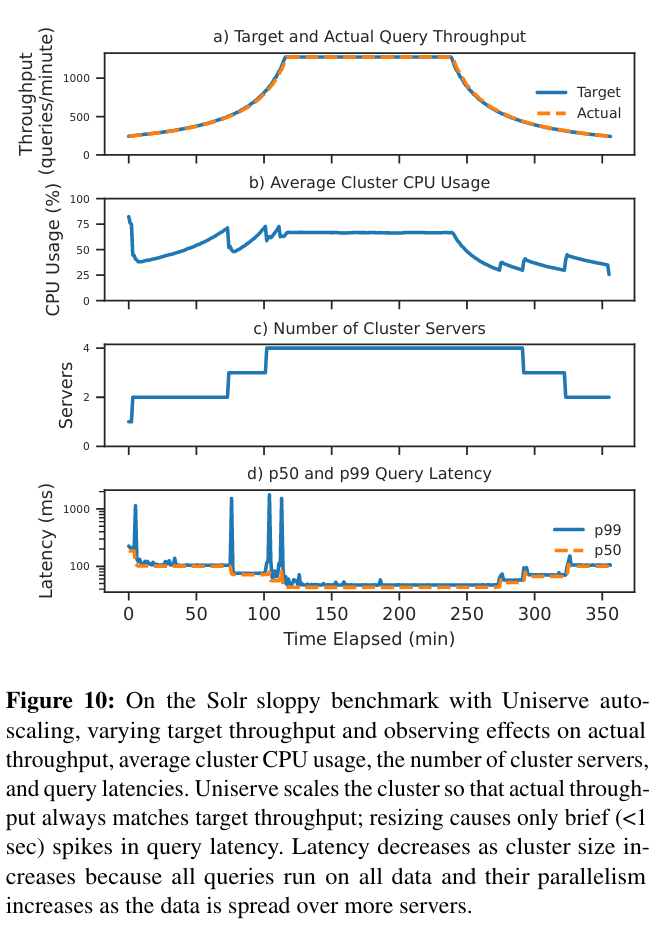
The evaluation also considered how a DPA system scaled in response to load - autoscaling while limiting load balancing and managing faults is difficultEven if some databases like Redshift or Snowflake make it look easy!
Conclusion
The DPA paper combines several ideas from existing research in a novel way - in particular, it draws on ideas related to deploying actor-based systems like Ray and Orleans.
It would be interesting to learn how the DPA design performs for other types of database deploymentsOne example would be MongoDB used with a different (non- query-serving system) access pattern. . For example, how does the DPA paradigm work for OLTP workloads? Are the overheads associated with the paradigm too high (and if so, can they be managed)?
I’m looking forward to seeing answers to these questions, along with further developments in this space - a unified framework for building query serving systems would likely be useful for the many different teams working on similar problems!