micahlerner.com
Druid: A Real-time Analytical Data Store
Published May 15, 2022
Found something wrong? Submit a pull request!
Discussion on Hacker News
These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
Druid: A Real-time Analytical Data Store
What is the research?
DruidThe paper notes that, “The name Druid comes from the Druid class in many role-playing games: it is a shape-shifter, capable of taking on many different forms to fulfill various different roles in a group”. is an open-source database designed for near-realtime and historical data analysis with low-latencyThe ideas that Druid discusses are closely connected to Lambda Architecture, covered in this great post from Nathan Marz on How to beat the CAP Theorem. . While originally developedThe original engineering blog posts are also a great read! by MetaMarkets, an Ad Tech company since acquired by SnapTechcrunch reference. , Druid is being used for a variety of different use cases by companies like Netflix, Confluent, and Lyft.
Druid’s goal of supporting near-realtime and historical access patterns makes it uniqueOr at least was more unique at the time the original paper was published in 2014 - more recently, combined batch/streaming architectures have grown in popularity. Also relevant is Questioning the Lambda Architecture from Jay Kreps (one of the creators of Kafka) - the post points out several downsides of a Lambda Architecture, including being built on the idea that “real-time processing is inherently approximate, less powerful, and more lossy than batch processing.” . The system’s approach opens it to a wider variety of use cases - for example, near real-time ingestion allows applications like production alerting based on logs (similar to Netflix’s use case) to find issues quickly, while also executing against a large history of data. In contrast, many data warehouse products are updated on a recurring “batch” basis, introducing lag between the time that metrics are logged and the time they are available for analysis.
Beyond covering the system’s design and implementation, the paper also discusses how reduced availability of different system components impacts users. Relatively few papers on production systems are structured in this way, and the approach was refreshing.
What are the paper’s contributions?
The paper makes several contributions:
- A description of the system’s architecture.
- Exploration of design decisions and an implementation.
- An evaluation of the system’s query API and performance results.
How does the system work?
Segments and data sources
Segments are a key abstraction in Druid. They are an immutable (but versioned) datastructure storing a collection of individual records. Collections of segments are combined into data sources, Druid’s version of database tables. Each segment stores all of the records that arrived during a given time period, for a given data source.

Architecture
Druid builds segments by ingesting data, then accesses the segments while responding to queries against data sources.
The Druid architecture uses four types of nodesNewer versions of the system seem to break up functionality TODO to implement ingesting data and responding to queries: real time nodes, historical nodes, broker nodes, and coordinator nodes.
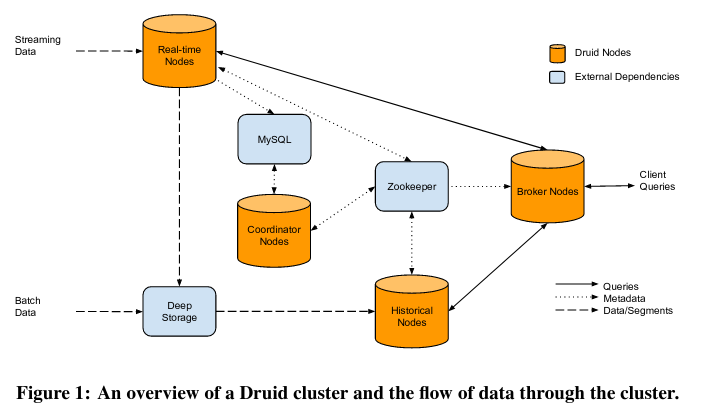
Unlike relatively stateless individual nodes, a Druid deployment stores state in two data sources:
- MySQL, which contains configuration and metadata, like an index of the existing segments.
- Zookeeper, which stores the current state of the system (including where multiple copies of segments are distributed on the machines in the system)
Real time nodes
Real time nodes have two responsibilties: ingesting data from producers, and responding to requests from users for recent data.
Producers provide raw data (like rows from a database), or transformed data (like the output of a stream processing pipeline) to real time nodes - a common producer pattern relies on Kafka topics. Kafka (or other message bus approaches) help with the availability and scalability of ingestion - real time nodes can store the offset that they have consumed into a stream, resetting to that offset if they crash/restart. To scale ingestion, multiple real time nodes can read different subsets of the same message bus.
When a real time node consumes records from a producer, it checks the time period and data source associated with the record, then routes the incoming record to an in-memory buffer with the same (time period, data source) key.
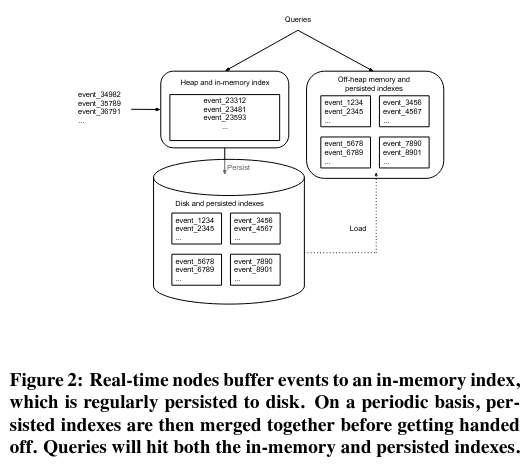
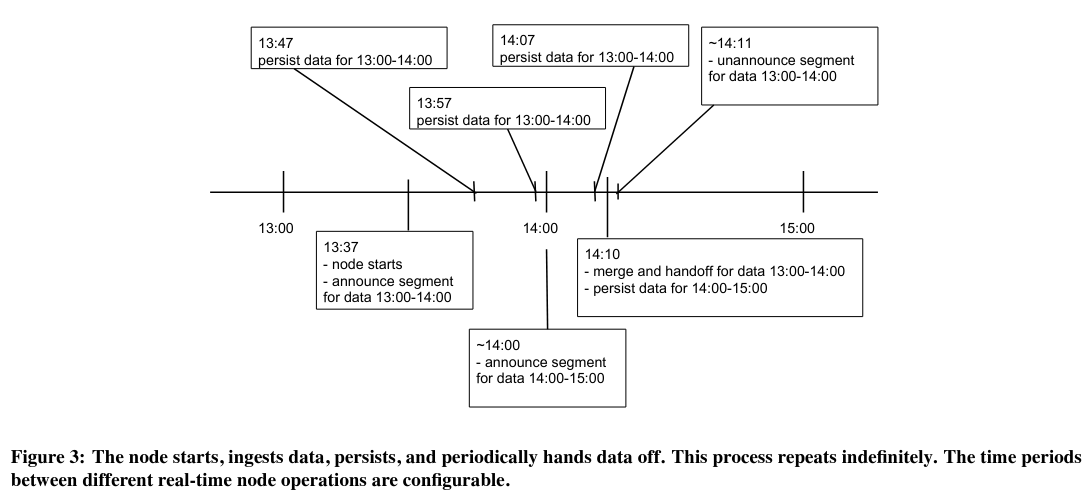
Each (time period, data source) buffer temporarilyController nodes (discussed in more detail further down) configure the length of this time range, in addition to other parameters like the datasources assigned to each Real-time node. remains on the node before being evicted - because of limited resources, nodes need to evict record buffers from memory periodically. On eviction, the in-memory buffer’s data is written to “deep” storage (like S3 or Google Cloud Storage).
Beyond ingestion, each real-time node responds to queries accessing recent data. To respond to these requests, the nodes scan using temporary in-memory indices.
Historical nodes
Historical nodes read immutable segments from storage, and respond to queries accessing them - coordinator nodes (discussed in the next section) control which segments a historical node fetches. When a Historical node downloads a segment sucessfully, it announces this fact to a service discovery component (Zookeeper) of the system, allowing user queries to access the segment. Unfortunately, if Zookeeper goes offline, the system will not be able to serve new segments - Historical nodes won’t be able to announce successful segment fetches, so the components of Druid responsible for querying data won’t forward queries.
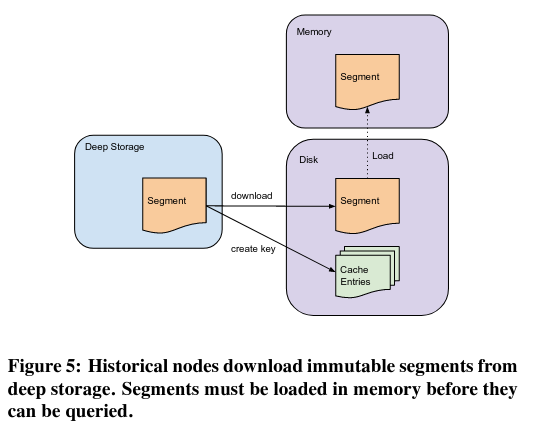
The decision to use immutable segments simplifies the implementation of historical nodes. First, it simplifies scaling of the system - if there are many requests that cover a segment, more historical nodes can store copies of the segment, resulting in queries diffusing over the cluster. Second, operating on segments rather than a lower level abstraction means that the historical nodes can simply wait to be told that there is a new version of data to serve, rather than needing to listen for changes to a segment itself.
Coordinator nodes
Coordinator nodes configure which segments are stored on historical nodesMultiple copies of a segment can be stored on different Historical nodes in the cluster to scale querying and increase redundancy. , and for how longFrom reading the Druid docs, it seems like there is a new, separate node-type responsible for controlling data-ingestion, called the Overlord. .
To make decisions, coordinator nodes read data from two locations: MySQL and Zookeeper. MySQL durably stores information on the universe of segmentsEssentially storing (time period, data source, version) - while there can be multiple copies of a segment, there would be one entry in the MySQL database to represent its type. and associated metadata about each segment typeLike how long a segment with a specific configuration should remain on a historical node. . Zookeeper stores the current state of all segments served by the system - real time nodes and historical nodes use it to announce changes in which segments are available. Coordinator nodes also load balance segmentsBalancing segment load is discussed in more detail in the Druid docs. across the system in order to limit “hot spots” that occur from many reads going to the same nodeThe Monarch paper also mentions a similar load-balancing mechanism! .
The paper nodes that there are multiple running coordinator nodes in a cluster, but there is only one “leader” at a time - the others are used for failoverTo scale coordination functionality, it sounds like it would be possible to create multiple sets of Coordinator nodes, each responsible for a partition of the dataset, although I didn’t see a discussion in the paper on this. . If coordinator nodes become unavailable (either because of MySQL or Zookeeper problems), historical and real time nodes will continue operating, but could become overloaded (due to non-operation of load balancing features). Additionally, the paper notes that this failure mode results in new data becoming unavailable.
Broker nodes
Lastly, Broker nodes receive requests from external clients, read state from Zookeeper, and forward requests to combinations of historical and real time nodes as appropriate. Broker nodes can also cache segments locally to limit the number of outgoing segment requests for future queries accessing the same data.
If Zookeeper becomes unavailable, then brokers use their “last known good state” to forward queries.
Storage Format
As discussed previously, a key abstraction in Druid is the segment, an immutable data structure used to store data. Each segment is associated with a data source (Druid’s conception of a traditional table), and contains data for a specific time period.
The data stored in segments is made up of two types: dimensions and metrics. Dimensions are values that rows aggregated or filtered on, while metrics correspond to numerical data (like counts).
Segments also contain a version number. If a segment is changed, the version number is incremented, and a new version of the segment is published - this can happen if delayed events come in for a previously finalized segment. Coordinator nodes handle the migration to the new version of a segment by instructing historical nodes to fetch the new version and drop the old version. Because of this approach, Druid is said to implement Multi-version Concurrency Control (MVCC)This paper review doesn’t go into detail on MVCC, but there are great resources about some of the ideas in this talk. One key idea is that there are multiple valid versions of data (like a snapshots), and different readers can view different versions of a dataset. .
Importantly, segments store data in columns, rather than rows - an approach known as “columnar storage”. This design is used in several other databases (like Redshift and Cassandra) and file formats (like Parquet) because of the performance advantages it provides.
For example, if a query is selecting a subset of columns, the database only needs to query the subset of data for those columns. A row-based solution would scan every row, selecting out the related columns. While both scans would yield the same results, the row-based scan is (almost) guaranteed to unnecessarily access columns that aren’t needed to answer the query, nor will be in query results.
Query API
The original Druid paper describes an HTTP query API where one would specify the datasource, time range, filtering mechanism, and potential aggregations.

The query API is one area where the recent versions of Druid diverge from the paper’s description. The current version of Druid exposes a SQL-like API for writing and submitting queries. The paper also discusses how Druid doesn’t support joins, although recent work has implemented the ideaOne of the recent papers I read (and plan on writing about soon!) from NSDI, Data-Parallel Actors: A Programming Model for Scalable Query Serving Systems, discusses how Druid’s long road to implementing could have been simplified by the ideas in the paper. .
How is the research evaluated?
To evaluate the system, the paper considers the performance and scale of Druid deployed at MetaMarkets.
As Druid was initially designed to serve low-latency queries, the paper evaluates latency performance using production traces:
Across all the various data sources, average query latency is approximately 550 milliseconds, with 90% of queries returning in less than 1 second, 95% in under 2 seconds, and 99% of queries returning in less than 10 seconds.
Ingestion latency is another focus of Druid’s design. The production system at MetaMarkets was able to ingest datasets of different shapes and sizes, with minimal latency and significant throughput.
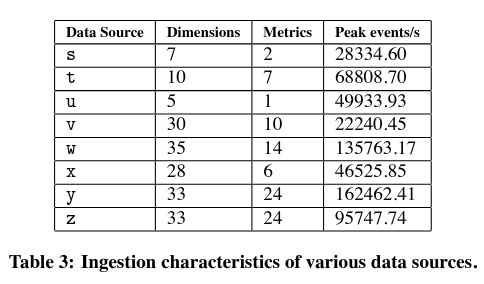
The paper also notes that while there is variation in ingestion latency, the problem can be solved by spending money on more resources for that component of the system (a decision that an implementer might make if especially concerned about this property).
Conclusion
I found the original Druid paper interesting because the design aims to tackle both real-time and historical analysis use cases.
The system also represents a step in the lineage of systems designed with the aforementioned goals in mind - Druid was one of the first implementations of a “Lambda Architecture”, where data is served from a combination of batch and streaming systems. Recent approaches at “Kappa”, and “Delta” architecturesIn particular, Databricks’ Delta Lake. seem like evolutions of what Druid originally proposedEven if the “naming architecture types based on Greek letters” can quickly get out of hand… .
Last but not least, I enjoyed the paper because of its discussion on how the system behaves in a degraded state. While some of the details may not be as relevant given Druid’s continued evolution following the paper’s publication, it is still unique to hear how the system was developed with those concerns in mind.