micahlerner.com
Ray: A Distributed Framework for Emerging AI Applications
Published June 27, 2021
Found something wrong? Submit a pull request!
Discussion on Hacker News
Ray: A Distributed Framework for Emerging AI Applications Moritz, Nishihara, Wang et. al.
This week I decided to revisit a paper from the 2018 edition of OSDI (Operating Systems Design and Impelementation). In the coming few weeks, I will likely be reading the new crop of papers from HotOS 2021. If there are any that look particuarly exciting to you, feel free to ping me on Twitter!
Ray is a thriving open-source project focused on “providing a universal API for distributed computing” - in other words, trying to build primitives that allow applications to easily run and scale (even across multi-cloud environments), using an actor-like framework. There are a few exciting demos which show how easy it is to parallelize computationThe demos are from Anyscale, a company founded by several original authors of the paper. Apache Spark is to Databricks, as Ray is to Anyscale. . The idea that (somewhat) unlimited cloud resources could be used to drastically speed up developer workflows is an exciting area of research - for a specific use case see From Laptop to Lambda: Outsourcing Everyday Jobs to Thousands of Transient Functional Containers.
While the current vision of the project has changed from the published paper (which came out of Berkeley’s RISELabThe RISELab is the “successor to the AMPLab”, where Apache Spark, Apache Mesos, and other “big data” technologies were originally developed) ), it is still interesting to reflect on the original architecture and motivation.
Ray was originally developed with the goal of supporting modern RL applications that must:
- Execute large numbers of millisecond-level computations (for example, in response to user requests)
- Execute workloads on heterogenous resources (running some system workloads on CPUs and others on GPUs)
- Quickly adapt to new inputs that impact a reinforcement-learning simulation
The authors argue that existing architectures for RL weren’t able to achieve these goals because of their a-la-carte design - even though technologies existed to solve individual problems associated with running RL models in production, no individual solution was able to cover all of the aforementioned requirements.
What are the paper’s contributions?
The Ray paper has three main contributions: a generic system designed to train, simulate, and server RL models, the design and architecture of that system, and a programming model used to write workloads that run on the system. We will dive into the programming and computation model first, as they are key to understanding the rest of the system.
Programming and computation model
Applications that run on Ray are made up of runnable subcomponents with two types: tasks or actors.
Tasks are a stateless function execution that rely on their inputs in order to produce a future result (futures are a common abstraction in asynchronous frameworksFor more on futures, I would recommend Heather Miller’s book on Programming Models for Distributed Computing. ). A programmer can make a future depend on another future’s result, like one would be able to in most asynch programming frameworks.
Actors are functions that represent a stateful computation (like a counter), and can depend on or be depended on by other computations. Because they require maintenance of state, they are also more difficult to implement (for example, how is the state recovered in event of failure?).
Resources can be explicitly allocated to tasks and actors - for example, an actor can be annotated with the number of GPUs it needs.
Because Tasks and Actors in an application can depend on one another, Ray represents their execution as a graph. The nodes in the graph are computation or state that computation produces, while the edges in the graph describe relationships between computations and/or data. Representing computation as a graph allows the state of an application be to re-executed as needed - for example, if part of the state is stored on a node that fails, that state can be recovered Several of the authors dig further into representing lineage in a future paper here. .

To instatiate tasks and actors, Ray provides a developer API in Python (and now in other languages). To initialize a remote function, a developer can add the @ray.remote decorator. The example below (from the open source project docs here) shows how one would create a remote function to square a range of numbers, then wait on the results.
import ray
ray.init()
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures))
Architecture
Ray aims to run Tasks and Actors created by developers in a fault-tolerant manner. To do so, it implements a distributed system containing two layers: the Application Layer and the System Layer.
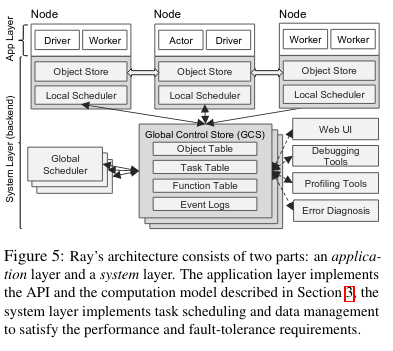
The Application Layer
The Application Layer has three components: a singleton driver (which orchestrates a specific user program on the cluster), workers (processes that run tasks), and actors (which as the name suggests, run Actors mentioned in the previous section).
The System Layer
The System Layer is significantly more complex, and comprises three components: a Global Control Store (which maintains state of the system), a scheduler (which coordinates running computation), and a distributed object store (which store the input and output of computation).
The Global Control Store (a.k.a. GCS) is a key-value store that maintains the state of the system. One of its key functions is maintaining the lineage of execution so that the system can recover in the event of failure. The authors argue that separating the system metadata from the scheduler allows every other component of the system to be stateless (making it easier to reason about how to recover if the different subcomponents fail).
The original paper does not dive into the subcomponents of the GCS, but the Ray v1.x Architecture paper provides more context on how components work (or in some cases, how they have been reworked). One of the most important subystems from the original paper was the Object Table, which stores locations of values used by Ray operations - for example, on which node a task is storing its output. We will see the Object Table again in the end-to-end example section of the paper review.
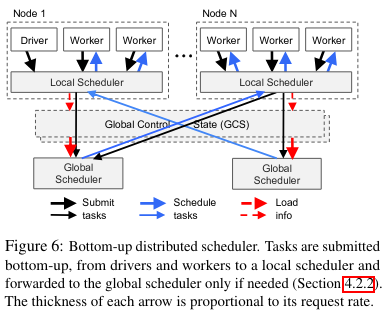
The Scheduler operates “bottoms up” in order to assign the execution of a function to a specific node in the cluster. In contrast to existing schedulers, the Ray scheduler aims to schedule millions of tasks per second (where the tasks are possibly short lived), while also taking into account data localityThe paper also mentions other assumptions that existing schedulers make - other schedulers “assume tasks belong to independent jobs, or assume the computation graph is known.” . Data locality matters for scheduling because the output of computation will end up on a specific node - transferring that data to another node incurs overhead. The scheduler is called “bottoms up” because tasks are first submitted to a local scheduler, only bubbling up to a global scheduler if they cannot be scheduled on the local machine.
Lastly, the distributed object store stores immutable inputs and outputs of every task in memory, transferring the inputs for a task to a different machine if needed (for example, if the local scheduler can’t find resources).
Running an application in Ray
Now that we have an understanding of the different components of Ray, lets walk through an example execution (as described in the original paper)I will caveat this section of the paper review with the fact that Ray has changed significantly, and not all functionality may have stayed exactly the same - even so, understanding how the different components fit together is interesting. .
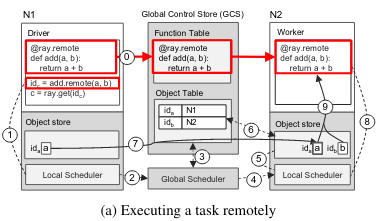
The execution involves adding the results of two existing Ray tasks (using a call to add.remote(a, b)). To begin, a function execution is initiated and submitted for scheduling on the local node (N1). The scheduling request is then forwarded to the Global Scheduler (possibly because the original node didn’t have enough capacity). The Global Scheduler checks the Object Table (which stores task outputs and their locations) for the location of the outputs of the a and b tasks. Then, the Global Scheduler assigns the new computation to a different node (N2). N2 only has the outputs of b, so it needs to fetch the outputs of a from a remote node. In order to fetch a, N2 makes a call to the GCS in order to determine where the other output (a) is stored, then fetches the output. Lastly, execution begins on N2.
Evaluation and microbenchmarks
The original paper evaluates whether Ray achieves the desired goal of being able to schedule millions of tasks with variable running times, and whether doing so on heterogenous architecture provides any benefits. A few of the benchmarks stick out to me, primarily those that show how Ray is able to take advantage of heterogenous computing resources.
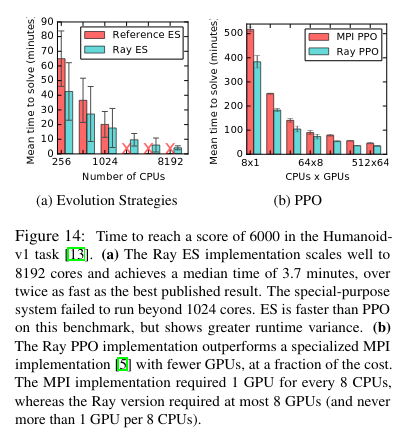
Ray is primarily impressive in this regard:
Ray implementation out-performs the optimized MPI implementation in all experiments, while using a fraction of the GPUs. The reason is that Ray is heterogeneity-aware and allows the user to utilize asymmetric architectures by expressing resource requirements at the granularity of a task or actor. The Ray implementation can then leverage TensorFlow’s single-process multi-GPU support and can pin objects in GPU memory when possible. This optimization cannot be easily ported to MPI due to the need to asynchronously gather rollouts to a single GPU process
For the Proximal Policy Optimization (PPO) algorithm (more information on PPO), the system is able to scale much better than an OpenMPI alternative: “Ray’s fault tolerance and resource-aware scheduling together cut costs by 18×.”
Conclusion
While originally designed as a system for RL applications, Ray is paving an exciting path forward in computing by providing abstractions on top of cloud resources (in particular, I’m excited to see how the projects innovates in multi-cloud deployments). They have an detailed design document for the new version of the system here.
If you find this paper interesting, Ray Summit was last week and covers various Ray system internals (in addition to discussions of the technology being adopted in industry).