micahlerner.com
The Demikernel Datapath OS Architecture for Microsecond-scale Datacenter Systems
Published November 09, 2021
Found something wrong? Submit a pull request!
Discussion on Hacker News
The papers over the next few weeks will be from SOSP. As always, feel free to reach out on Twitter with feedback or suggestions about papers to read! These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed.
The Demikernel Datapath OS Architecture for Microsecond-scale Datacenter Systems
This week’s paper is The Demikernel Datapath OS Architecture for Microsecond-scale Datacenter Systems. DemikernelIrene Zhang, the paper’s first author, also gave a talk at Papers We Love! is an operating systems architecture designed for an age in which IO devices and network speeds are improving faster than CPUs areThe “Attack of the Killer Microseconds” describes this problem area, and is available on the ACM website. . The code is open source and predominantly implemented in Rust.
One approach to addressing the growing disconnect between IO and CPU speeds is a technique called kernel-bypass. Kernel-bypass allows more direct access to devices by moving functionality typically inside of an OS kernel to user spaceHelpful reference on the difference between kernel space and user space is here. or offloading features to the device itself. Executing operating system functionality inside user space provides several latency-related advantages, like reducing costly userspace to kernel space transitionsThe Cloudflare blog provides more details on this topic. and allowing applications to limit memory copies during IO (known as “zero copy IO” - more details later in this paper review).
While kernel bypass systems are becoming ubiquitous and can enable dramatic speedups for applications (in particular, those in cloud environments), there are challenges to adoption - engineering resources must be used to port applications to this new architecture and new device APIs or versions can incur ongoing maintenance costs.
Demikernel aims to solve the tension between the utility of kernel-bypass and the engineering challenges that limit the technique’s adoption - one key to its approach is providing abstractions that applications migrating to kernel-bypass can use.
What are the paper’s contributions?
The Demikernel paper makes three contributions: a new operating system API for developing kernel-bypass applications, the design for an operating system architecture that uses the new API, and several implementations of operating systems that implement the design using the API proposed by the paper.
Demikernel approach
There are three main goals of Demikernel:
- Make it easier for engineers to adopt kernel-bypass technology
- Allow applications that use Demikernel to run across many different devices and in cloud environments
- Enable systems to achieve the ultra-low (nanosecond) IO latency required in the “Age of the killer microseconds”
First, Demikernel aims to simplify usage of kernel-bypass technology by building reusable components that can be swapped in (or out) depending on the needs of an application. Before Demikernel, kernel-bypass applications would often re-implement traditional operating system features inside of user space, one example being the network stack. Two new abstractions in Demikernel, PDPIX and libOS, are targeted at encapsulating these common user space features in easy to use APIs, limiting the amount of time that developers spend reimplementing existing logic.
Next, Demikernel aims to allow kernel-bypass applications to run across many different devices and environments (including cloud providers). The system focuses on IO, but Demikernel still runs alongside a host kernel performing other OS functions outside of the datapath.
Lastly, achieving ultra-low IO latency in the “Age of the Killer Microseconds” requires more advanced techniques that pose their own complexities. One example of these advanced technique is zero-copy IOFor more on zero-copy IO, I had the chance to dig into the topic in a previous paper review of Breakfast of Champions: Towards Zero-Copy Serialization with NIC Scatter-Gather! , which ensures that information on the data path is not copied (as unnecessary copies incur latency). Implementing zero-copy IO is complicated by different devices implementing different abstractions around the memory used in zero-copy IOFor example, some kernel-bypass devices (like RDMA) require ‘registration’ of memory used for zero-copy IO through specific API calls - more on this topic in a later section. .
To achieve these design goals, Demikernel implements two concepts: a portable datapath interface (PDPIX) and a set of library operating systems (libOSes) built with this API.
Portable Datapath API (PDPIX)
The portable datapath interface (PDPIX) aims to provide a similar set of functionality to POSIX system calls, but reworks the POSIX systems calls to satisfy the needs of low-latency IO.
In contrast to the POSIX API:
- PDPIX replaces the file descriptorWhat are file descriptors? abstraction used in POSIX with IO queues - applications
createqueues, thenpushdata to orpopdata from the queue, finally callingcloseto destroy the queue. - PDPIX implements semantics that allow zero-copy IO (as zero-copy is crucial for low-latency IO). In one example, API calls that push data to a given queue provide access to arrays in a shared heap. The data in the shared heap can be read by the device in the kernel-bypass system immediately, without requiring an unnecessary copy into kernel space.
- PDPIX explicitly is designed around asynchronous IO operationsWhile Linux has epoll, the paper notes two shortcomings: “epoll: (1) wait directly returns the data from the operation so the application can begin processing immediately, and (2) assuming each application worker waits on a separate qtoken, wait wakes only one worker on each I/O completion.
“ . API calls, like
pushandpop, return aqtoken. Applications can callwait(orwait_allfor a set of qtokens) to block further execution until an operation has completed.

Library Operating System (libOS)
Demikernel implements the idea of library operating systems (each implementation is called a libOS) to abstract an application’s use of a kernel-bypass device - there are multiple types of devices used by kernel-bypass sytems, and using a different type of device involves potentially moving different parts of the operating system stack into user space. Each libOS takes advantage of the PDPIX API discussed in the previous section.
The paper discusses libOS implementatations for several different types of IO devices, but this paper review focuses on two:
- Remote Direct Memory Access (RDMA), which allows computers to directly access the memory of other computers (for example, in a datacenter), without interfering with the processing on the other computer. RDMA is commonly used in data center networksSee research from Microsoft and Google. Also, this article about RDMA from Nvidia’s blog. -
- Data Plane Development Kit (DPDK): the goal of DPDK devices is high-performance processing TCP packets in user space, rather than in kernel space (the Microsoft Azure docs provide additional context).
While RDMA and DPDK are both targeted at networking applications, devices that support the two approaches don’t implement the same capabilities on the device itself - for example, RDMA devices support features like congestion control and reliable delivery of messagesSee Congestion Control for Large-Scale RDMA Deployments , while DPDK devices may not.
Because RDMA and DPDK devices don’t natively support the same functionality on the device, kernel-bypass applications that aim to use these devices are limited to what logic they can run on the device versus in user space. To make this more concrete - if an application wanted to use DPDK instead of RDMA, it would need to implement more functionality in code, placing a greater burden on the application developer.
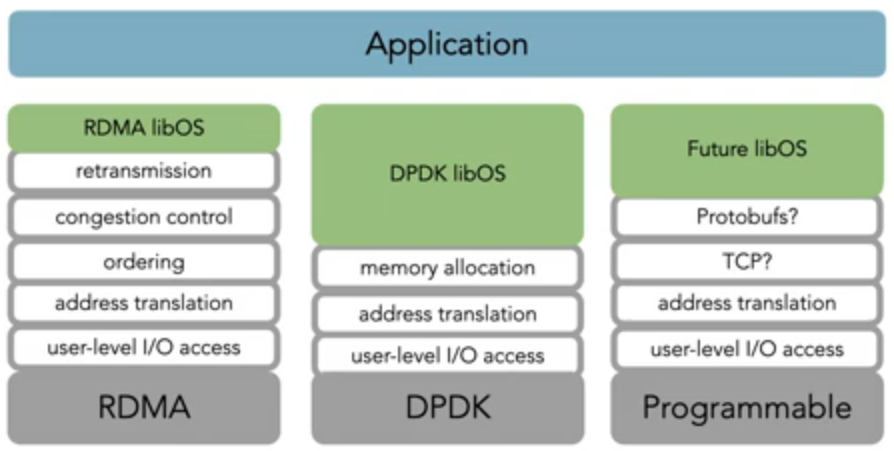
There are three main components to the libOS implementations: IO processing, memory management, and a coroutine scheduler.
The libOS implemenations are in Rust and uses unsafe codeRelated to my last paper review on Rudra, which aims to analyze unsafe code for security issues! to call C/C++ libraries for the various devices
Each libOS processes IOs with an “error free fast path” that makes various assumptionsFor example “packets arrive in order, send windows are open … which is the common case in the datacenter”. based on the goal of optimizing for conditions in a datacenterIt is very interesting to see how diffferent papers implement systems using this assumption - see my previous paper review on Homa, a transport protocol that aims to replace TCP/IP in the datacenter. (where kernel-bypass applications are normally deployed). The libOS has a main thread that handles this “fast path” by polling for IOs to operate onThe paper notes that polling is CPU intensive but ensures that events are processed quickly (a similar type of tradeoff is made by Homa). .
To manage memory (and facilitate zero-copy IO), the libOS uses a “uses a device-specific, modified Hoard for memory management.” Hoard is a memory allocator that is much faster than mallocAn interesting comparison of Hoard with other memory allocators is here. . The original Hoard paper is here and discusses the reasons for Hoard’s performance (although the official documentation that the project has changed significantly since the original implementation). Each memory allocator must be device-specific because devices have different strategies for managing the memory available on the device itself - as an example, RDMA devices use “memory registration” that “takes a memory buffer and prepare it to be used for local and/or remote access.”Ref , while DPDK uses a “mempool library” that allocates fixed-sized objectsRef . To ensure that user-after-freeUse-after-free (abbreviated to UAF) vulnerabilities are quite serious! vulnerabilities do not occur, each libOS implements reference countingHere is a helpful description of what reference counting is. .
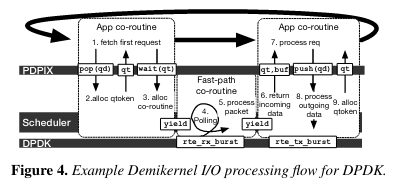
Each libOS uses “Rust’s async/await language features to implement asynchronous I/O processing within coroutines”The paper notes that Rust async/await and coroutines are in active development. I am far from an expert on Rust, so this RFC, design overview, and episode from Crust of Rust were helpful background. .
Coroutines are run with a coroutine scheduler that runs three coroutine types:
(1) a fast-path I/O processing coroutine for each I/O stack that polls for I/O and performs fast-path I/O processing, (2) several background coroutines for other I/O stack work (e.g., managing TCP send windows), and (3) one application coroutine per blocked qtoken, which runs an application worker to process a single request.
The details of the scheduler implementation are fascinating and I highly recommend referencing the paper for more info, as the paper discusses how it achieves the performance needed to meet the nanosecond-level design goal of Demikernel - one interesting trick is using Lemire’s algorithm.
Library Operating System (libOS) implementations
The paper describes several library operating system implementationsThe names of which (Catpaw, Catnap, Catmint, Catnip, and Cattree) indicate that the authors might be cat people 🙂! that implement interfaces used for testing (providing the PDPIX API, but using the POSIX API under the hood), RDMA, DPDK, or the Storage Performance Developer Kit (SPDK)SPDK is a kernel-bypass framework for storage devices. . Each libOS is paired with a host operating system (Windows or Linux), and uses the host operating system’s kernel-bypass interfaces. The paper does an amazing job of giving the implementation details of each libOS, for more detail please see the paper!
Evaluation
The paper evaluates Demikernel on how well it achieves the three design goals described in an earlier section of this paper review.
To evaluate the ease of use and complexity for applications that adopt Demikernel, the paper compares lines of code for a number of different applications that use the POSIX or Demikernel APIs. The authors also note the time it takes to port existing applications to Demikernel, noting that developers commented on Demikernel being the easiest interface to use.

The paper evaluates whether Demikernel achieves nanosecond scale IO processing for storage and networking applications across a number of platforms.
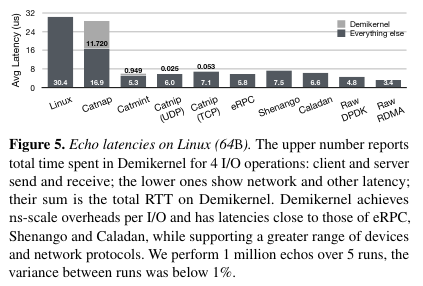
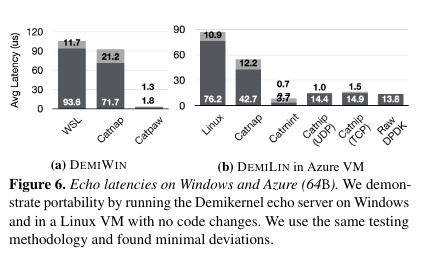
Conclusion
The most recent paper on Demikernel is the culmination of a large body of work from the authors focused on high-performacnce IO. I’m very excited to follow how Demikernel (or similar systems built on top of the ideas) are adopted across industry - in particular, I am looking forward to hearing more about the developer experience of porting applications to the paradigm that the paper outlines.
Thanks for reading - as always, feel free to reach out with feedback on Twitter!