micahlerner.com
Rudra: Finding Memory Safety Bugs in Rust at the Ecosystem Scale
Published October 31, 2021
Found something wrong? Submit a pull request!
Discussion on Hacker News
The papers over the next few weeks will be from SOSP. As always, feel free to reach out on Twitter with feedback or suggestions about papers to read! These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed.
Rudra: Finding Memory Safety Bugs in Rust at the Ecosystem Scale
This week’s paper is about Rudra, a systemThe Rudra code itself is open source on Github. for finding memory safety bugs in code written with the Rust programming language. Rust is used for many purposes, although it is particularly popular for lower level systems programming - the language’s approach to memory management allows the compiler to eliminate many common types of memory management issues, in turn improving security. As a result, Rust is used across many high-profile open source projects where security matters, including the Mozilla Servo engine, the open-source Firecracker MicroVM technology used in AWS Lambda/FargateFirecracker is also used in many other open source projects - see my previous paper review on Firecracker for more details. , and the Fuschia operating system.
Unfortunately, it is not possible to implement every functionality with code that obeys the language’s rules around memory management. To address this gap, Rust includes an unsafe tag that allows code to suspend some of the rules, albeit within well defined blocks of code. While unsafe sections of Rust code are generally reviewed closely, the language construct can lead to subtle bugs that compromise the security Rust code.
The goal of Rudra is automatically evaluating these unsafe sections of code to find security issues. Rudra has achieved remarkable success - at the time of the paper’s publication, the system had identified 76 CVEs and ~52% of the memory safety bugs in the official Rust security advisory database, RustSec.
What are the paper’s contributions?
The Rudra paper makes three primary contributions: it describes scalable algorithms for finding memory safety bugs in unsafe Rust code, implements the algorithms in the open source Rudra project, and demonstrates using the project to find bugs in existing open source code.
Safe Rust
In order to understand the memory safety issues that Rudra detects, it is important to understand how Rust provides memory safety guarantees at compile time and the idea of unsafe Rust. For those familar with these topics, skipping to “Pitfalls of Safe Rust” might make sense.
Language features
To provide memory safety guarantees at compile time, Rust uses: ownership, borrowing, and aliasising xor mutabilityThere are many great posts from the Rust community that explore these topics - feel free to DM me on Twitter with more as I am far from a Rust expert! While writing this paper review, I read the amazing Rust docs, Rust: A unique perspective and Thread safety and Learning in Rust. .
Ownership, according to the Rust documentation means that:
- Each value in Rust has a variable that’s called its owner.
- There can only be one owner at a time.
- When the owner goes out of scope, the value will be dropped.
Borrowing allows one “to access data without taking ownership over it” - Rust By Example has a helpful section on the topic. Integration of borrowing semantics into the language help to address problems related to accessing variables after the reference is no longer validWhich are exploited by Use After Free.
Aliasising xor mutability means that the language prevents, “both shared and mutable references … at the same time. This means that concurrent reads and writes are fundamentally impossible in Rust, eliminating the possibility of conventional race conditions and memory safety bugs like accessing invalid references”The paper cites iterator invalidation as one example of accessing invalid references prevented by this approach. .
Unsafe Rust
To implement certain features (and bound undefined behavior), writers of Rust code can mark blocks with unsafe. From the Rust docs, this allows that code block to perform a number of actions that wouldn’t be permitted otherwise, like “call unsafe functions (including C functions, compiler intrinsics, and the raw allocator)”. C doesn’t operate according to Rust’s constraints (specifically around undefined behavior), so using it inside of Rust code needs to be marked unsafe.
An example use case of unsafe is performing memory-mapped IO. Memory-mapped IO relies on mapping a file to a region of memory using mmap. The implementation of memory-mapping IO from one of the most popular Rust memory mapping libraries calls the C function mmap, meaning that the function must be inside of an unsafe block.
Pitfalls of Unsafe Rust
Now that we roughly know why code is marked unsafe, this section moves on to the three main types of issues detected by Rudra in unsafe Rust code: panic safety, higher order invariant safety, and propagating send/sync in generic types.
Panic safety is a problem that crops up in unsafe blocks that initialize some state with the intention of further action. If these code blocks hit a panic (which “unwinds” the current call, destroying objects along the way), the further action isn’t taken and “the destructors of the variable will run without realizing that the variable is in an inconsistent state, resulting in memory safety issues similar to uninitialized uses or double frees in C/C++.”
Higher order invariant safety means that a “Rust function should execute safely for all safe inputs.” To ensure that a function operates only on arguments it can use safely (failing otherwise), Rust code can check the properties of the provided arguments. Checking arguments is made more difficult in some cases because a provided argument may be generic, and the specifics about the implementation of the argument may not be available. One example of a higher order invariant is:
“passing an uninitialized buffer to a caller-provided Read implementation. Read is commonly expected to read data from one source (e.g., a file) and write into the provided buffer. However, it is perfectly valid to read the buffer under Rust’s type system. This leads to undefined behavior if the buffer contains uninitialized memory.”
Propagating send/sync in generic types is related to two traitsTraits in Rust often contain shared functionality that can be mixed into code. (Send and Sync) used for thread safetyMore information and examples of how Send and Sync are used from the Rust docs and StackOverflow. . The compiler can automatically determine how a Trait gets assigned Send/Sync - if all of a Trait’s properties are Send/Sync, it is safe to conclude that the Trait containing those properties implements Send/Sync itself. For other Traits (like locks), Send/Sync behavior can not be automatically passed on - one example is for a container class (like a list) that contains types that are not Send/Sync themselves. In these situations, the code must implement Send/Sync manually, leading to potential memory safety issues if the implementation uses unsafe code and is incorrectThe paper notes it is possible for an implementation to be incorrect initially, or for the implementation to become incorrect over time due to ongoing maintenance (made more likely by having the implementation spread out over a codebase). in some way.
Design of Rudra
This section describes the system’s design goals (what the system needs to do in order to find memory safety issues in unsafe Rust code), as well as how Rudra is designed to achieve those goals.
Design Goals
To achieve the goal of finding memory safety issues in unsafe Rust code, Rudra needs to:
- Consume metadata about Rust typing, not available at lower levels of the compiler (more on what this means later).
- Analyze the entirety of the Rust ecosystem, using limited resources.
- Be able to make the tradeoff between using limited resources and the precision of results. More resources can be expended in order to verify resultsOne way to think about this tradeoff is that Rudra aims to find paths in the code that could potentially lead to memory safety issues. Using more resources allows further verification or simulation along those paths to determine whether a code path does in fact lead to a bug. , leading to fewer false positives. On the other hand, Rudra aims to analyze the entirety of the Rust ecosystem on an ongoing basis, so the program should also be able to expend fewer resources and run faster, with the potential for more false positives.
Rudra components
To achieve its design goals, Rudra implements two algorithms on intermediate representations (IR)The Rust docs on how code is represented and compiled is really great! I highly recommend it for those interested in learning more about the internals. produced by the Rust compiler: an unsafe dataflow checker and send/sync variance checker.
The unsafe dataflow checker finds panic safety bugs (which can occur if a panic happens during an unsafe section and the code is in a temporarily inconsistent state) and higher order invariant bugs (which can happen if a function doesn’t, or can’t, verify passed arguments to ensure it is safe to operate on them). The algorithm checks for lifetime bypasses in unsafe Rust code that perform logic not otherwise permitted by the compilerWhat is or is not allowed by the compiler is discussed in the ‘Language Features’ section above. - this general category of functionality can contribute to panic safety bugs or higher order invariant bugs.
The algorithm models six classes of lifetime bypasses:
- uninitialized: creating uninitialized values
- duplicate: duplicating the lifetime of objects (e.g., with mem::read())
- write: overwriting the memory of a value
- copy: memcpy()-like buffer copy
- transmute: reinterpreting a type and its lifetime
- ptr-to-ref : converting a pointer to a reference
The send/sync variance checker evaluates a set of rules to determine whether a data type meets Send/Sync constraints given the usage of the data type - for example, some data types might require only Send, only Sync, both, or neither. The heuristics for performing this evaluation are described in more detail in the paper (and are also implemented in the open source project). Once the variance checker determines whether Send/Sync are needed for a data type, it compares that to the actual implementation, raising an issue if there is a mismatch.
Implementation
Rudra is implemented as a custom Rust compiler driver, meaning it hooks into the Rust compilation process:
It works as an unmodified Rust compiler when compiling dependencies and injects the analysis algorithms when compiling the target package.
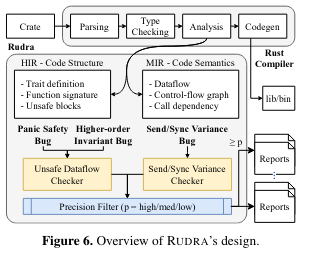
The two algorithms implemented in Rudra operate on different intermediate representationsThe Rust docs on how code is represented and compiled is really great! I highly recommend it for those interested in learning more about the internals. (IR) of Rust code. The unsafe dataflow checker runs on the HIR, which has code structure, while the send/sync variance checker operates on the (MIR).
Evaluation
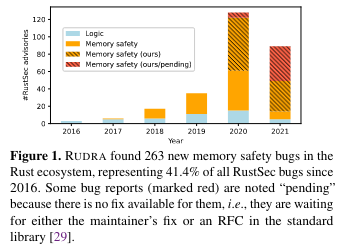
At the time of publication, Rudra had found 264 memory safety bugs in open source Rust packages, including 76 CVEs. To make the point about how tricky (and novel) some of these problems were to detect before Rudra found them, the paper notes that several of the issues were in the Rust standard library (which is reviewed by Rust experts).
While the project had significant success finding bugs, it als has false positive rate of around 50%, although the precision is adjustable). On the other hand, most of the false positives could be quickly resolved by visual inspection according to the authors.
The authors compare Rudra to other tools for finding bugs in Rust code. Rudra ran faster than commonly used fuzzers, while also finding more bugs. When applied to the same codebases as another Rust-focused tool, Miri, the issues found by the two tools partially overlap (although Miri found unique bugs, indicating the approach is complementary).
Conclusion
Rudra focuses on finding memory management issues in Rust code (and does so quite successfully). Importantly, when Rudra does find issues, the paper notes it is relatively easier to assign ownership of fixing the root cause to the package with the unsafe block.
Even though unsafe is required so Rust can support certain functionality, it is an opt-in language feature, limiting the surface area of memory management issues. This reflects a significant improvement over other languages where similarly unsafe code can be anywhere in a code base. While there is still work to be done on changing how the system detects and limits false positives, I am hopeful that it continues to evolve alongside the growing Rust ecosystem.
As always, feel free to reach out with feedback on Twitter!