micahlerner.com
A Linux Kernel Implementation of the Homa Transport Protocol, Part II
Published August 29, 2021
Found something wrong? Submit a pull request!
Discussion on Hacker News
Programming note: I will be taking a several week break from writing paper reviews for the summer. When we come back, I will be finishing off the papers from Usenix ATC and OSDI, then moving on to the great upcoming conferences (my non-exhaustive list is here). As always, feel free to reach out on Twitter with feedback or suggestions about papers to read! These paper reviews can be delivered weekly to your inbox, or you can subscribe to the new Atom feed.
A Linux Kernel Implementation of the Homa Transport Protocol
This week’s paper review is Part II in a series on the Homa Transport Protocol - part I is available here. As a refresher, Homa is a transport protocol with the goal of replacing TCP in the data center. The first part of the series focuses on describing the goals of Homa, while this paper review discusses an open source implementation of the protocol as a Linux Kernel moduleThere is an excellent Kernel Module programming guide that has been revamped continuously since the 2.2 kernel. Another great description of writing your own Linux Kernel module here. .
The author (John Ousterhout, one of the inventors of the Raft consensus algorithm) has three goals in mind with implementing Homa as a Linux Kernel Module:
- Understand how Homa performs in a more production-like environment, represented by the Linux kernel.
- Perform apples to apples comparisons of Homa to implementations of competing protocols (TCP and DCTCP).
- Build an implementation of Homa that could be used and extended by real users
What are the paper’s contributions?
In accomplishing the three goals above, the paper makes two contributions:
- Showing that Homa beats TCP and DCTCPDCTCP is a project that preceded Homa, but has a similar goal of replacing TCP in the dataceter. The paper is here. , replicating the results of the paper presented in Part I.
- An analysis of Homa’s limits. This study indicates potential future directions for research tackling the tension between faster network speeds and using more cores to handle increased bandwidth.
Homa API
Homa aims to deliver a connectionless transport protocol for RPCs in the data center. The protocol’s approach contrasts with TCP on two dimensions.
Homa is:
- RPC-oriented, rather than stream-oriented: TCP’s stream-based approach (which relies on FIFO delivery of messages) can experience high tail latency. The cause of this latency is head of line blocking, where delay in a message at the front (or “head”) of a stream delays the rest of the stream. Homa limits head of line blocking because the protocol does not enforce FIFO ordering of messages.
- Connectionless, rather than connection-oriented: TCP’s connection-oriented approach is not well suited for datacenters because “applications can have hundreds or thousands of them, resulting in high space and time overheads”.
To make the protocol available to developers, the implementation defines an API focused on sending and receiving RPC messages. The primary methods in the API are homa_send, homa_recv, and homa_reply. These calls operate on sockets that can be reused for many different RPC requests (notably different from TCP). The methods return or accept a 64 bit identifier for a corresponding RPC. Furthermore, an RPC-based approach facilitates abstracting away logic responsible for Homa’s reliability, like the internals of retries.

Challenges in implementing
The paper outlines three main challenges toWhen viewing these challenges, it is important to remember that Homa is designed for reliable high-speed datacenter networks. Thus the constraints Homa faces in the kernel are different than in other, non-datacenter environments. implementing Homa as a Linux Kernel module:
- Moving packets through the protocol stack is costly.
- Multiple cores are needed to process incoming packets, yet Linux load balancing of this work is non-optimal.
- Packets need to be assigned priorities and transmitted in real-time. Accomplishing this task with a single core is difficult, using multiple cores to solve the problem even more so.
Sending packets is costly, as doing so involves copies and interaction with other Linux features. One approach to this overhead is userspace networkingTouched on in a past paper review of Breakfast of Champions: Towards Zero-Copy Serialization with NIC Scatter-Gather. . Another approach mentioned in the paper is batching packets together to amoritize cost - unfortunately, this approach does not work well for Homa because batching packets can introduce latency (a main concern of the protocol).
Multiple cores are needed to process packets because networks are improving faster than CPUs areA problem discussed in this great ACM article on “Attack of the Killer Microseconds”. . A challenge to using multiple cores is Linux scheduling, which creates “software congestion” when “too much work is assigned to one core”.
Lastly, Homa strives to assign priorities to packets, while minimizing the size of the network interface card’s (NIC) transmit queue - more items in this queue means a potentially longer wait time, and more tail latency.
Implementation
As discussed above, there are three primary challenges to implementing Homa as a Linux Kernel module. These challenges impact the sending and receiving path for packets - the visualization below describes these two paths and the components involved in implementing them. Fair warning that the implementation is heavy on Linux internals, and I try to link to documentation for further deep dives where possible!
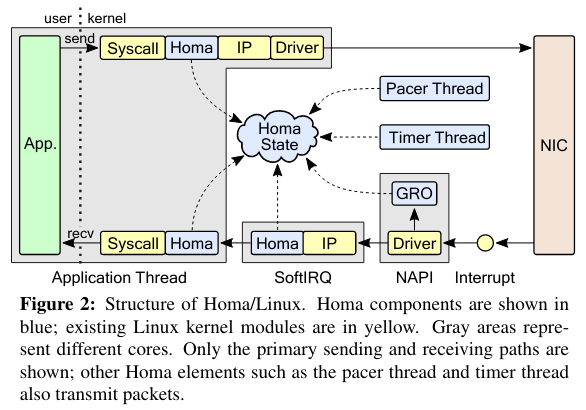
Moving packets
The first challenge in implementing Homa is the cost of moving packets through the networking stack. To solve this problem, the implementation uses batching on the send and receive paths, rather than pushing packets through the stack one by one.
On the sending path, Homa/Linux uses TCP Segmentation Offload (TSO)There are extensive docs on Linux segmentation offloading here. Generic Segment Offload is also mentioned, but isn’t supported at this time. . A TSO-based strategy offloads work to the NIC - the kernel passes large packets to the NIC, which then performs the work of breaking down the packet into smaller segments.
The implementation of batching on the receive path is somewhat more complicated. When the NIC receives packets, it issues an interrupt. In response to the interrupt, the networking driver schedules a NAPINAPI stands for “New API” and is a framework for packet processing. I found this additional documentation on the Linux Foundation site useful. action that polls the NIC for packets until it reaches a configured limit. Once the driver reaches this limit, it communicates batches to the SoftIRQ layer of the Linux kernel. SoftIRQ “is meant to handle processing that is almost — but not quite — as important as the handling of hardware interrupts”.From Jonathan Corbet’s 2012 article. Another comprehensive article on receiving data in the Linux Networking Stack is here. Homa builds up messages from the incoming batches, and signals waiting application threads once a message is complete - these applications are then able to make use of the response to the Homa calls mentioned in the API section above.
Load balancing
Homa is intended for high speed networks under load. In this environment, a single core is not capable of processing incoming packets - to use multiple cores, Homa must load balance workThe paper notes that, “load balancing is easy for packet output, because the output stack executes entirely on the sending thread’s core, with a separate NIC channel per core. The Linux scheduler balances threads across cores, and this distributes the packet transmission load as well.” .
Load balancing is implemented in the kernel with two load balancers:
- Receive Side Scaling (RSS), which performs load balancing inside the NIC to distribute processing across CPUs. The Linux Networking documentation provides helpful documentation on RSS.
- NAPI (mentioned previously), which performs load balancing at the SoftIRQ layer (once batches of packets are created, those batches need to communicated to waiting application threads)
The paper also mentions that the balancing implementation hurts performance at low load, as “at low load it is best to concentrate all processing on a single core”The experimental section of the paper quantifies this effect. . While ideally Homa could implement an adaptive load balancing scheme, the paper mentions that “there does not appear to be a way to do this in Linux.” This remark ties into a theme throughout the paper - that the Linux kernel’s focus on TCP (in particular, design impacted by this focus) introduces overhead.
Real-time processing
Homa aims to assign packet priorities and limit the amount of time packets spend in the NIC’s transmit queue - more time in the transmit queue means more delay/potential tail latency. Because the NICs used do not make the size of their transmit queues available, Homa needs to estimate their size. The implementation does so using an estimate of the size of the packets and the link speed. This estimate is updated by a pacer thread (visible in the architecture diagram above). Unfortunately, there are complications to running the pacer thread: the pacer can not keep up at high bandwidth, and the operating system scheduler potentially interferes by descheduling the thread’s execution. The paper outlines three workarounds that assist the pacer thread, ensuring it doesn’t fall behind:
- Small packets don’t interact with the pacer (meaning less work)
- Other cores pitch in if the main pacer thread falls behind
- Other parts of the Homa implementation will queue packets if the thread falls behind
Evaluation
A primary goal of the paper was to evaluate Homa in a production-like environment, reproducing the results of the original Homa paper (covered in Part I).
To accomplish this goal, the paper tests the Linux implementation of Homa with four workloads from the original paper. The workloads cover a wide arrange of message sizes (including both small and large RPCs). Furthermore, the paper focuses on cases where there are many clients - Homa is not well suited for situations where there are few RPC clients (arguing that this situation does not arise in data center like environments). The same workloads are executed with TCP and DCTCP (a TCP-like protocol adapted for the datacenter), and compared to Homa’s results.
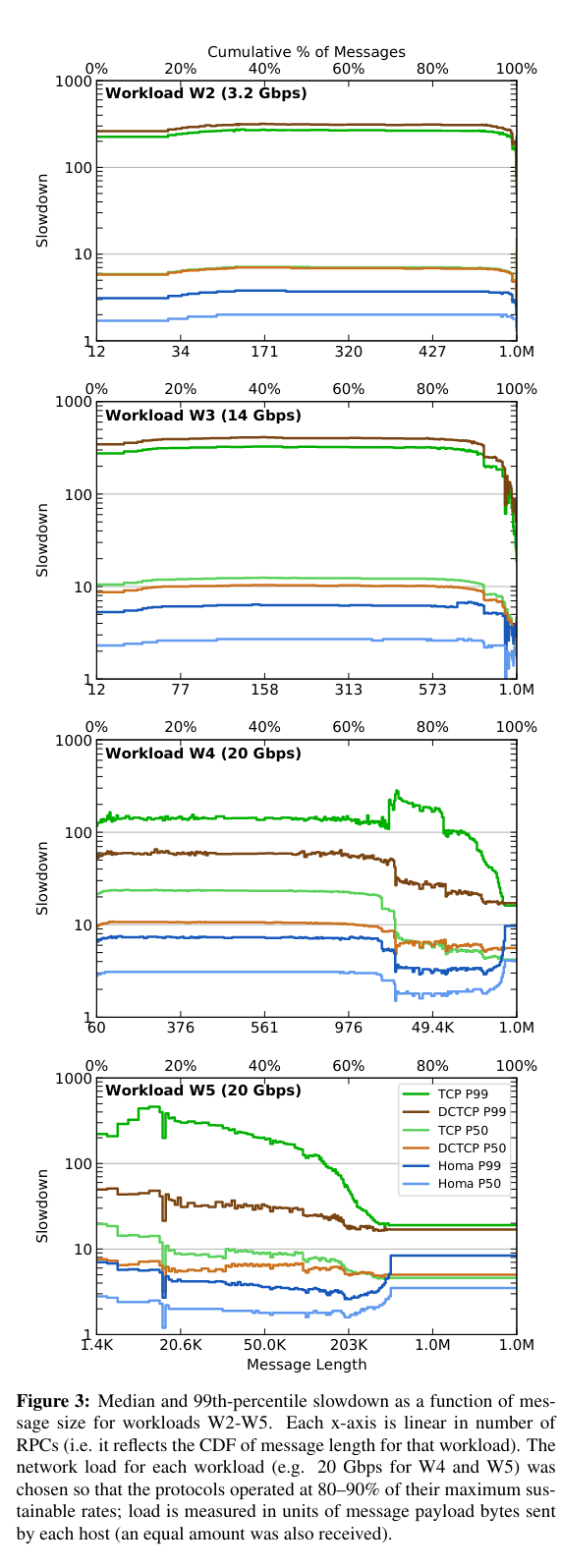
The key metric used in this set of performance evaluations is slowdown. Slowdown is calculated by comparing the round trip time (RTT) of an RPC to the RTT observed using Homa under ideal conditions (Homa is designed to perform well for small messages on a network under high load). Smaller values of slowdown are better than larger values - larger values for slowdown mean that the result is significantly worse than one would expect from Homa under ideal conditions.
The graphs below show Homa’s significantly lower slowdown relative to TCP and DCTCP for a variety of message sizes.
The paper also includes a number of microbenchmarks focused on validating other aspects of the implementation, like how well Homa performs with different numbers of prioritiy levels, or how well the implementation performs under reduced loadHoma is designed for high load, so it is useful to evaluate the implementation in situations it might not otherwise perform well under. .
Conclusion
The conclusion of the Homa paper asserts that while the implementation “eliminates congestion as a significant performance factor”, remaining software-based overheads pose a future area of improvement. These overheads come from conflicts between Homa and Linux implementation details (like scheduling and load balancing that optimize for TCP).
The paper discusses two potential solutions:
- Moving transport protocols to user spaceAn interesting topic that will be covered in papers from at least one conference paper over the next few months!
- Moving transport protocols to the NIC
I thoroughly enjoyed diving into Homa - stay tuned for when we resume in the next few weeks. When we will cover papers from OSDI, ATC, and the upcoming set of conferences. Until then!