micahlerner.com
ServiceRouter: Hyperscale and Minimal Cost Service Mesh at Meta
Published March 28, 2024
Found something wrong? Submit a pull request!
ServiceRouter: Hyperscale and Minimal Cost Service Mesh at Meta
What is the research and why does it matter?
Many tech companies have distributed services deployed in the cloud in regions around the world. The systems often depend on each other, meaning that they need to determine which dependencies are where (service discovery), and route the requests across the network (often performed via a “service mesh. Inter-system communication also needs to be highly reliable and load balanced.
This paper is about Meta’s infrastructure that implements these capabilities, called ServiceRouter.
While there are well known open source systems for routing traffic (e.g. Linkerd, Envoy, and Istio), there are a few interesting components of ServiceRouter:
- ServiceRouter supports embedding inside Meta application code, significantly reducing cost from the common pattern of running separate “service mesh” infrastructure - the paper suggests that a separately deployed service mesh at Meta scale would need the equivalent of 1,750,000 AWS t4g.small VMs.
- ServiceRouter is one of the first pieces of RPC routing infrastructure discussed in research deployed at hyperscale.
- ServiceRouter is able to handle sharded stateful services, unlike open source alternativesThe paper makes the claim that open source service meshes ‘exclusively focus on un-sharded services’, which I’m slightly confused about - one of my friends Max pointed out that people run sharded services like Kafka on Kubernetes. .
- The technology handles load balancing across regions using the novel idea of “Latency Rings”The paper also mentions that Istio supports a simpler version of this idea. .
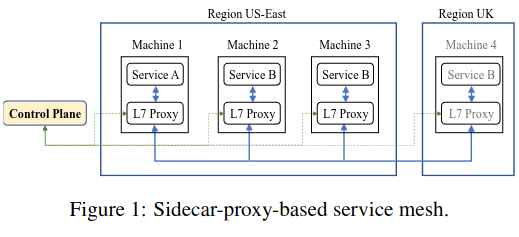
How does the system work?
Design
There are three main functions of ServiceRouter:
- Gathering the data that informs how services talk to each other.
- Distributing that data reliably around the network.
- Routing a request from a service to another service.
To build a source of truth for routing decisions (which the paper calls the Routing Information Base (RIB)), ServiceRouter gathers information from the cluster manager about which services are running where. Importantly, ServiceRouter can also handle stateful services (discussed in my previous paper review on ShardManager) - for example, some services will store a specific subset of data on a specific server, so knowing the server alone is not enough.
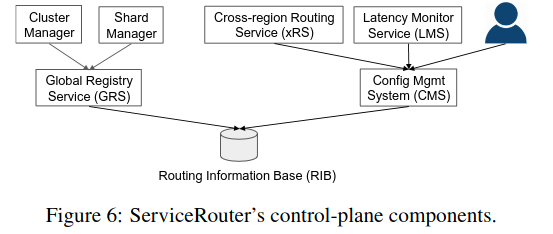
As an input to the Routing Information Base, ServiceRouter also gathers information that allows it to make decisions about how services talk to each other across clusters (for example, monitoring the latency of traffic from North America to South America).

ServiceRouter then distributes the Routing Information Base across infrastructure in the network to allow services to make routing decisions.
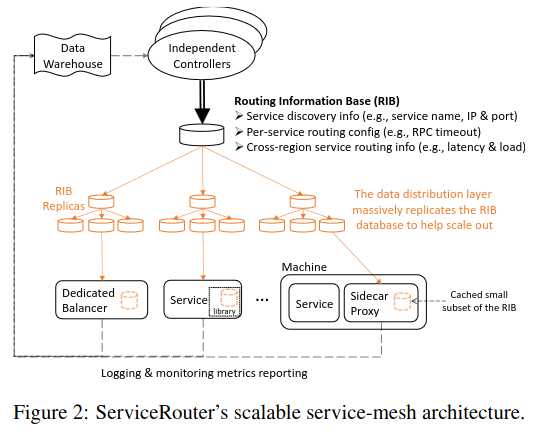
To implement the part of the system responsible for making routing decisions, ServiceRouter supports three main types of deployments: SRLib, Remote Proxy, and Sidecar Proxy (the paper also mentions a fourth, SRLookaside which is now deprecated).
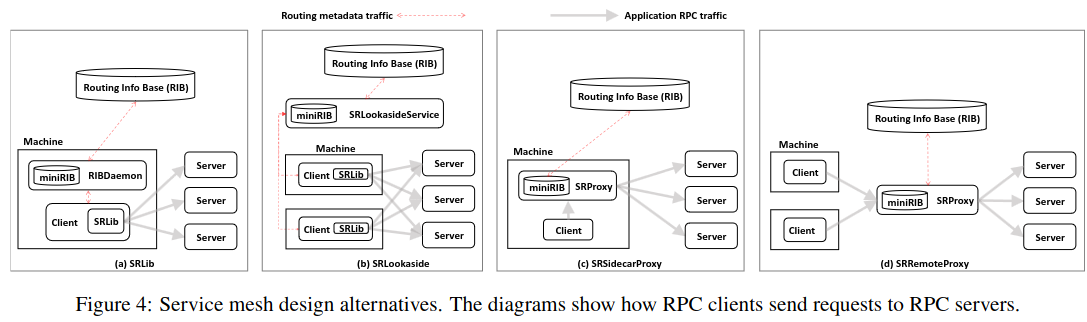

SRLib embeds the ServiceRouter functionality actually inside the application binary, deeply integrated with application source code. While this introduces some risk (e.g. if the embedded library had a bug or vulnerability, all applications would need to be re-released), it dramatically reduces hardware cost.
There are several situations in which SRLib performs suboptimally - for example, with traffic that goes across regions, it is preferable to have a smaller set of proxies that perform the RPC forwarding using long-held connections, lowering the overhead of sending RPCs.
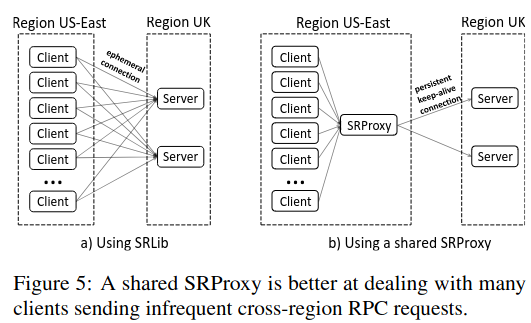
ServiceRouter also supports codebases where it is difficult or impossible to embed SRLib directly. The paper cites one example of internal Erlang applications which didn’t have builtin support for the library, but still wanted to make use of Meta-internal systems.
Load Balancing
One of the most novel features of ServiceRouter is its approach to global load balancing traffic across regions.
The system implements this capability using the idea of locality rings for a service:
An RPC client uses cross-region RTTs to estimate its latency to different servers. Starting from ring1, if the client finds any RPC server whose latency is within the latency bound for ring i, it filters out all servers in ring i+1 and above, and randomly samples two servers from ring i. If the service has no servers in ring i, it considers servers in ring i+1, and so forth. SR’s default setting maps [ring1 ring2 ring3 ring4] to [same region neighboring regions same continent global].
The paper discusses several downsides to this approach, notably that latency alone doesn’t reflect how servers in a locality ring are being utilized. To solve this shortcoming, ServiceRouter integrates another input to the Routing Information Base - the load of a “locality ring”. This data allows ServiceRouter to support functionality like “route X% of traffic to this locality ring until the load of that locality ring exceeds X%, then send traffic to the next locality ring.” This is particuarly useful during incidents, where traffic can spill across multiple regions.
The paper also discusses alternatives to the locality ring approach, including relying solely on RPC latency and feedback from a service about overload to decide when to send traffic to a different locality ring - the authors decided not to follow this approach as they argue that routing would change only under severe overload.
How is the research evaluated?
The paper evaluates ServiceRouter on four main aspects: its scalability, the cost-savings of an embedded routing library, performance of global load balancing, and ability to handle sharded services.
To assess scalability, the paper shares data on the number of servers used by services and the requests per second by service:
A small fraction of services are very large while most are very small. Specifically, while 90% of services each use less than 200 servers, 2% of services each use more than 2,000 servers and the largest service uses about 90ć servers…Similarly, while most services have a low RPS, some hyperscale services process billions of RPS.
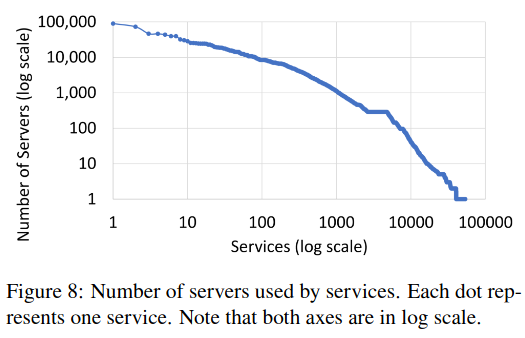
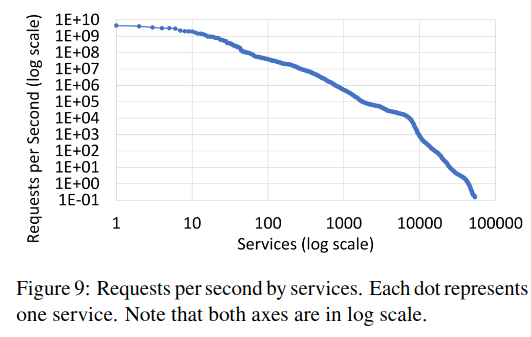
The paper also discusses several scalability challenges, specifically with the Routing Information Base, which must store data on Meta’s ever-changing services and production infrastructure. Interestingly, the authors say that the RIB is not currently a bottleneck, following their work to migrate off of Zookeeper and onto a custom datastore.
To evaluate hardware cost, the paper compares RPC latency and CPU overhead for Meta’s raw RPC library (called Thrift), embedded SRLib and the SRProxy - “across the RPC client and proxy, the SRProxy setup in total consumes more than twice the amount of CPU cycles as the SRLib setup”.
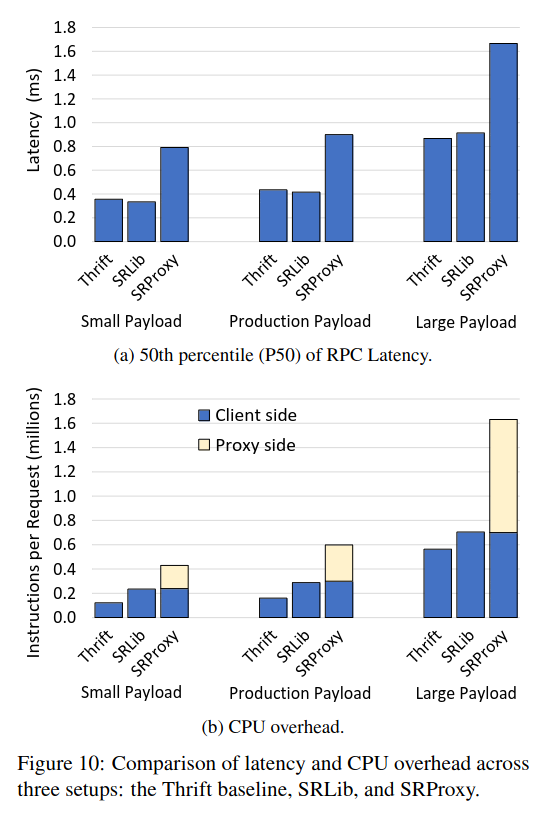
The paper also includes several production use cases of SRProxy. One example was for a sharded system that sends traffic cross-region. SRProxy was able to reduce cross-region latency because it reuses connections. Because ServiceRouter was able to effectively support cross-region load balancing, the system didn’t need to replicate all the shards to all the regions, significantly reducing capacity usage.
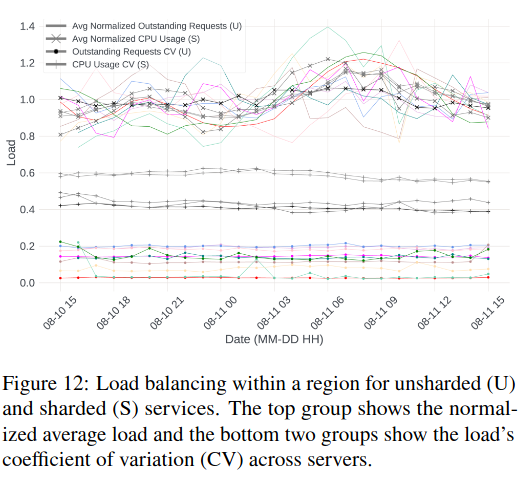
To evaluate load balancing, the paper considers the permutations of same-region and cross-region load balancing for both sharded and unsharded services. For same-region traffic of unsharded services, load balancing is quite good, represented with a low “coefficient of variation” for CPU usage and outstanding requests. The story for sharded services is more complicated due to inherent shard imbalance - “some shards are hot (receiving a lot of traffic) while others are cold (receiving little traffic), due to the nature of data stored in the shards.” In other words, even if ServiceRouter load balances performs perfectly, there will always be some variation of load between shards.
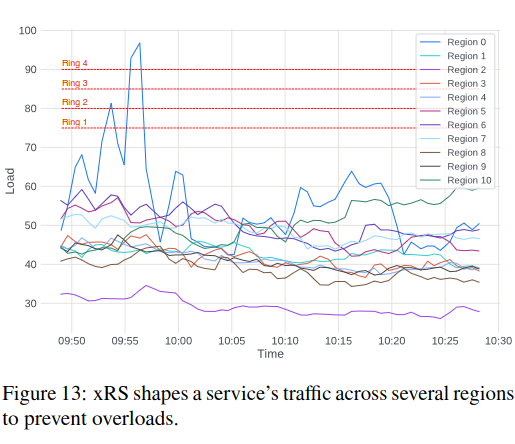
To evaluate global load balancing with locality rings, the paper includes an example of an incident where traffic spilled cross-region, and ServiceRouter was able to balance load below the 75% locality threshold.
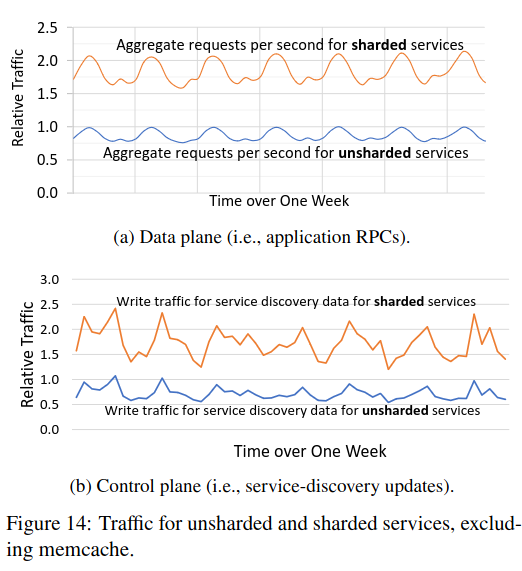
Lastly, the paper shows that traffic to sharded services makes up a significant portion of total traffic, highlighting the requirement that this nuance needs to be natively supported in Meta’s service mesh.
Conclusion
While service meshes aren’t necessarily novel, ServiceRouter’s deployment at scale, along with its implementation of global load balancing and support for sharded services is unique.
Load balancing cross region at scale, in particular to handle reliability issues, is non-trivial. I’d be interested in hearing more about how teams formulate locality rings (as from the paper, it seems like some custom tuning is involved). Furthermore, the ideas behind locality rings seems ripe for further development - are latency and CPU usage the only factors that locality rings should be limited to? Relying only on those two metrics seems like a potential source of further instability during an incident (e.g. if a region was quickly returning many errors, its CPU utilization might appear low, meaning that ServiceRouter would send requests there, potentially exacerbating an outage with overload).
Lastly, embedding SRLib in an application’s code saves resources, but seems like it would introduce risk. For example, if SRLib had a fleet-wide security vulnerability or performance regression that couldn’t be turned off, what would the impact to services and developers be?
In future paper reviews, I’ll continue diving deeper on sharded services in hyperscale environments - for example, I’m planning on comparing ServiceRouter and its discussion of sharded services with Google’s paper from 2016 on Slicer.