micahlerner.com
Blueprint: A Toolchain for Highly-Reconfigurable Microservice Applications
Published January 02, 2024
Found something wrong? Submit a pull request!
Blueprint: A Toolchain for Highly-Reconfigurable Microservice Applications
What is the research?
The Blueprint paper talks about a new open source framework for configuring, building, and deploying application code. This framework aims to simplify iteration on system design, application development, and configuration.
The authors argue that these tasks are currently difficult to accomplish because many services have tight coupling between application code, framework-level components (like RPC libraries and their behavior), and the actual deployment of the service (e.g. with Docker, Kubernetes, or other systems like Ansible).
By explicitly separating concerns of an application, and explicitly defining their interactions in a programmatic configuration, the authors are able to test out new configurations of a system - for example, quickly reconfiguring a set of independently deployed microservices into a single monolithic binary, then measuring the performance impact of the change.
How does the system work?
Blueprint’s approach divides a system into three types of components:
- Application level workflows: business logic that a developer writes to perform a specific function.
- Scaffolding: underlying framework-level components like RPC functionality, distributed tracing libraries, and storage backends (like caches and databases).
- Instantiations: specific configuration for framework-level components (e.g. using a specific RPC library with deadlines set or with novel functionality like circuit-breakers enabled.
A system is described in a programmatic configuration called a workflow spec which contains application logic and its external interface.


Next, a user of Blueprint creates a wiring spec that encode the relationship between pieces of application code and framework-level components. In one example, the authors recreate a simple microservice for posting on a social network, including connection to external caches and databases.

Blueprint then uses the wiring spec to compile an intermediate representation (an idea common to many compilers) of the system. The intermediate representation is effectively a graph with nodes describing code and edges describing dependencies (e.g. service A calls service B).
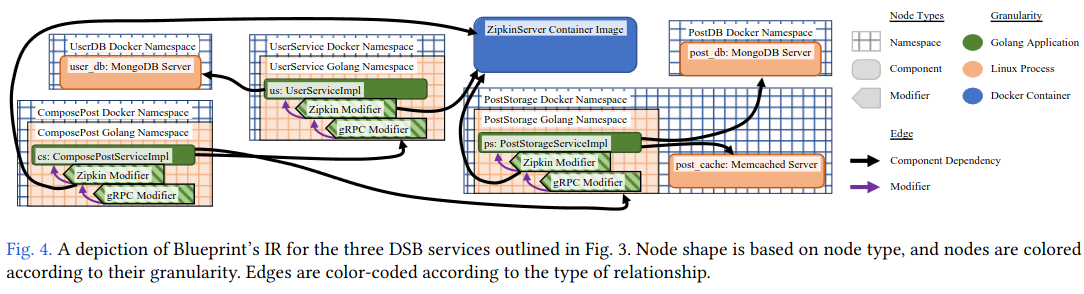
Lastly, the intermediate representation is used to build concrete artifacts representing the components of the system - for example, the build system can compile the code for a service written in Go and wrap it with a Docker image, enabling later deployments to production.
How is the research evaluated?
The authors evaluate several research claims about the implementation, but three themes stood out to me:
- Does Blueprint make it easier for developers to try new configurations of an system’s existing components and libraries?
- Can Blueprint be used to create system configurations that reproduce reliability issues?
- What are the costs of the abstractions that Blueprint provides?
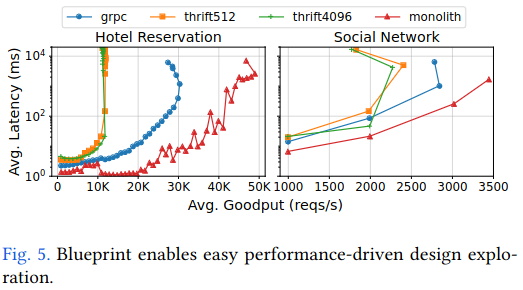
To evaluate the first question of whether Blueprint makes it easier to try new configurations for a system’s existing components, the authors considered the lines of code required to enable/disable tracing and to convert a microservice deployment into a monolith.
They were able to perform the first task of making changes to tracing with 5 lines of code. Similarly, by changing ~10 lines of code in the Blueprint configuration, they were able to generate a monolithic version of an application previously deployed as microservices, then quantify the performance impact of this change.
The authors also used Blueprint to reproduce or create reliability issues in a service - in particular they focused on Metastable failures described in a previous paper review. While creating specific configurations of a system to enable reliability testing is not necessarily a unique feature of Blueprint (e.g. Metastable Failures in the Wild discusses replicating metastability), the ease with which the authors performed this analysis was intriguing.
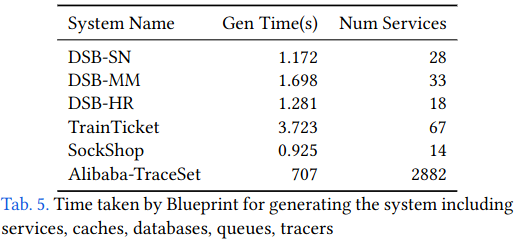
Lastly, paper analyzes how long it takes for Blueprint to generate systems of different sizes. While many of the examples are based on prototype systems, the authors also ran Blueprint on a system derived from a microservice dataset published by Alibaba.
Conclusion
Blueprint’s idea of separating the concerns involved in an application seems like a promising approach to dramatically increasing the velocity of the software development lifecycle (at least for microservices). One area that seems particularly exciting about Blueprint is the ability to simplify testing different service configurations across infrastructure - for example, rather than rewriting a large body of application code to test out a new tracing library, a developer can simply swap out the code in the Blueprint definition.
From reading the paper, there are several areas of further research for Blueprint, particularly around production readiness. For example, Blueprint’s compilation time for a system of ~3000 microservces described in a paper from Alibaba ran for 12 minutes. For organizations that would have many components in their configuration, the cost to run Blueprint would certainly be non-negligible. To speedup compliation of Blueprint, perhaps it would only recompute parts of the system touched by a developer’s changes.
Furthermore, adoption via onboarding new systems to Blueprint also seems like a challenge, as developers would need to perform some implementation in order to create the definition of their system - perhaps the team behind Blueprint will expand on tooling that automates this process by reading metadata source from a running system (e.g. traces).