micahlerner.com
Towards an Adaptable Systems Architecture for Memory Tiering at Warehouse-Scale
Published June 29, 2023
Found something wrong? Submit a pull request!
Discussion on Hacker News
This is one in a series of papers I’m reading from ASPLOS. These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
Towards an Adaptable Systems Architecture for Memory Tiering at Warehouse-Scale
Applications running in datacenter environments require resources to operate, like dynamic random access memorySee reference. . DRAM is both expensiveIn this article cited by the paper, a distinguished engineer from Azure cloud at Microsoft said, “About 50 percent of my server cost is memory.” and in high demandPartially due to the growth of AI applications. . As alternatives to DRAM emerge, new approaches to trading off performance for cost became available to datacenter applications - specifically, the paper mentions Intel Optane, which offers significant cost savingsOne point-in-time description of the cost savings is here.
To use this new resource type while limiting the impact to application performance, the authors proposed, built, and deployed at scale a new system called Transparent Memory Tiering System (TMTS). The approach interacts with Google’s Borg schedulerAt scale, cluster schedules abstract allocation of raw resources to an application - see Borg from Google, Twine from Facebook, and the open source Mesos project (used at some point by Twitter and Apple). to adaptively move an applications in-memory data from high performance memory to lower cost mediums, an approach it calls memory tiering - based on usage, the system “promotes” in-use memory pages into high performance memory, and “demotes” infrequently-used memory to lower/performance mediums.
When deployed at scale, TMTS replaced 25% of DRAM with lower cost solutions, while incurring little performance impact to the vast majority of applications.
What are the paper’s contributions?
The paper makes three main categories of contributions:
- Design and implementation of a memory tiering system.
- A testing methodology for evaluating changes to the system at scale.
- Lessons and evaluation from running the implementation in production.
How does the system work?
System metrics
The paper discusses the key tradeoff the system needs to make between potential cost savings and performance degradation. For example, applications on the critical path of user requests (which the paper calls high importance latency sensitive (HILS)) are more sensitive to latency and performance impact than batch workloads.
Furthermore, for a tiered memory system to deliver on its promise of cost savings, it needs to strike the right balance of using lower performance hardware - if the cluster scheduler doesn’t run jobs on the lower performance hardware, the resources intended to save cost will sit around being unutilized (meaning the potential cost savings will not occur and there are more resources that you’ve paid for). On the other hand, if the scheduler assigns latency-sensitive applications to lower performance hardware, performance will suffer.
Using these two considerations, the paper defines two metrics to measure the success of memory tiering:
- Secondary Tier Residency Ratio (STRR) represents the “fraction of allocated memory residing in tier2 [lower performance memory]”.
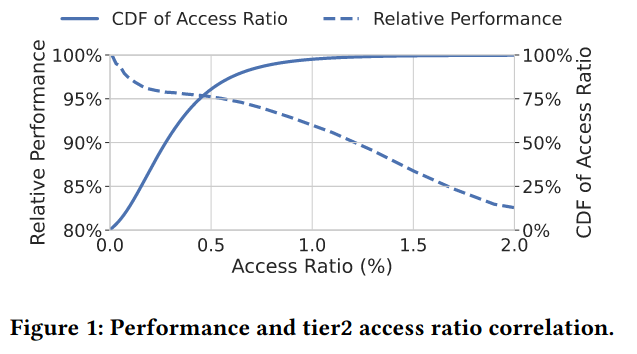
- Secondary Tier Access Ratio (STAR) “is the fraction of all memory accesses of an application directed towards pages resident in tier2”. This is a proxy for application performance impact because an application accessing lower tier memory will likely incur higher latency.
In summary, the goal of the system is to maximize usage of cheaper/lower performance memory (represented via STRR) while minimizing negative impact to application performance (via STAR).
System Architecture
The memory tiering system is divided into four levels of abstraction: hardware, kernel, userspace, and the cluster scheduler.
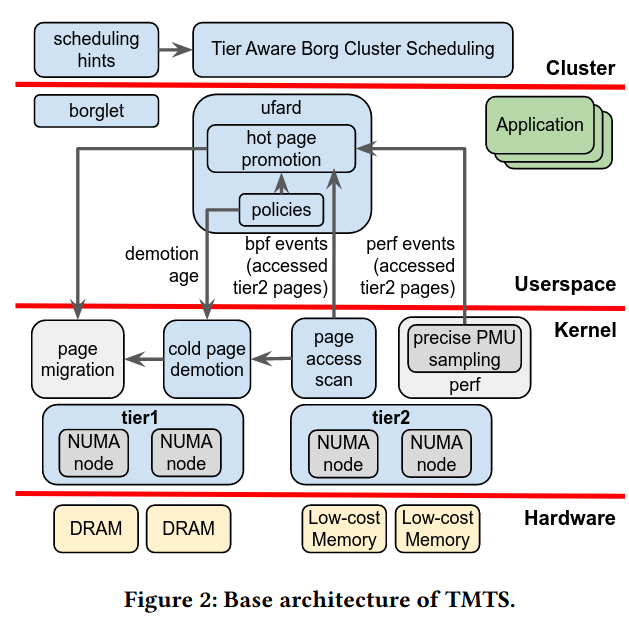
At the bottom of the stack is the underlying hardware, made up of several types of memory devices with different performance and cost profiles.
Immediately above the hardware is the kernel, which abstracts the hardware into different tiers (tier1 for higher performance, tier2 for lower performance) and operates on hardware abstractions like memory pagesFor more context on memory abstractions like pages, I highly recommend Operating Systems: Three Easy Pieces, an amazing free operating systems book. . Inside the kernel, the system uses daemons to monitor memory accesses, building the dataset that will inform the promotion/demotion process.
Above the kernel is user space, where a management daemon (ufard) makes demotion and promotion policies for memory between tier1 and tier2, then conveys changes in policies to the kernel. The promotion/demotion policy can change over time based on information that the kernel provides to this userspace daemon - for example, information on how many pages were not accessed recently. Other components of the system also run in user space, including a scheduler component and the applications themselves.
At the top layer, the cluster scheduler makes decision about where to run applications based on their memory needs and performance of the system. The paper describes how the scheduler consumes information about which tiers of memory are available on which machines to make placement decisions.
Hot page promotion and cold page demotion
A key component of the memory system is demoting cold pages to low-cost memory, and promoting hot pages to higher performance resources.
A page is classified as “cold with threshold t if it has not been accessed in the prior t seconds”, but the policy about when to demote pages to cold memory is dependent on the needs of the application.
An application’s policy can also be adaptive, for example:
“the kernel provides the userspace daemon a cold age histogram - the frequency distribution of inter-access interval duration. It answers questions such as how many pages were not accessed for at least 2 minutes. The policy engine uses this to identify application access patterns and adjust parameter values.”
To promote pages from tier2 to tier1, the tiered memory system relies on two approaches: proactive promotion and periodic scanning.
Proactive promotion aims to move pages from tier2 to tier1 as soon as they are likely to receive more accesses, rather than waiting until a surge of access occurs (which would introduce application latency). This proactive process is informed by signals from hardware, in particular the Performance Monitoring Unit (PMU)For more info on PMUs, I found this article to be useful. ) - for example, sampling last level cacheSee more information on last level caches here. miss events provides insights into which data is actively being usedWhen trying to find an example explanation to link to, I found this one I really liked. .
Periodic scanning complements the sampling-based approach by scanning pages over repeating periods. and promoting them based on how many consecutive “scan periods” the page has been accessed in. This approach is more accurate, but higher overhead. The system also aims to limit thrashing - if a page is potentially going to be demoted, but was recently promoted, the demotion process waits for a longer time period before taking action.
These monitoring processes use a combination of perf_event_openThere is a useful guide on Linux performance here. and Berkley Packet Filter (BPF) in the kernelFor more background, I would recommend Julia Evans’ blog. BPF has been a hot topic recently for a variety of different use cases, including security and observability. which “optimize[s] the collection of tier2 hot page ages and their page addresses from the in-kernel page.”
How is the research evaluated?
System Evaluation
Memory tiering is deployed in production and is constantly evolving to perform more effectively. To evaluate the system, the paper considers three areas: memory utilization / task capacity, residency ratios, access ratios / bandwidth, and overall performance impact
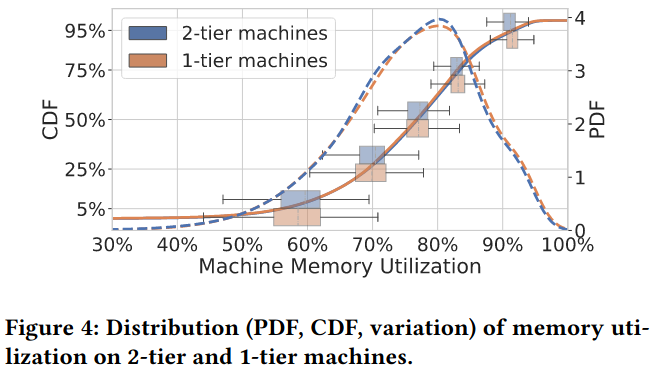
Memory utilization / task capacity represents the impact that the system has on individual applications - if an application is performing poorly (for example, serving requests with high user facing latency), the scheduler will either schedule more tasks for the application (increasing task capcity) or put fewer tasks on the impacted machines (leading to lower utilization, as there will be machines with fewer tasks). The paper presents data that shows memory utilization and task capacity isn’t significantly impacted by the memory tiering system.
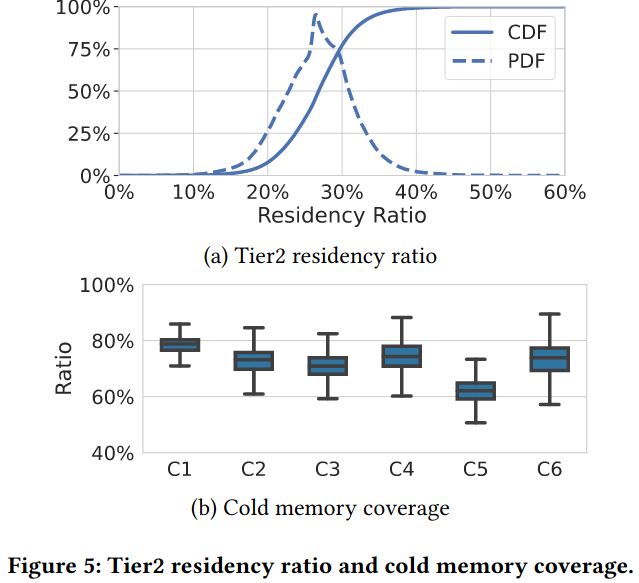
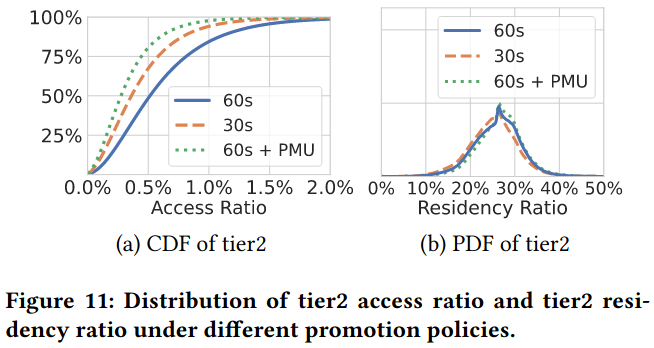
Residency ratios gauges how successful the system is at storing infrequently used pages in tier2 memory. First, the paper shows that the Secondary Tier Residency Ratio (STRR) is close to the percentage of deployed tier2 hardware, demonstrating effective use of tier2 memory. Additionally, the paper includes data on the ratio of cold memory stored in tier2, which is between 50 and 75% across all clusters - the paper compares this to swap based solutionsSpecifically citing data from Software-Defined Far Memory in Warehouse-Scale Computers. which reach 10-25% memory coverage.
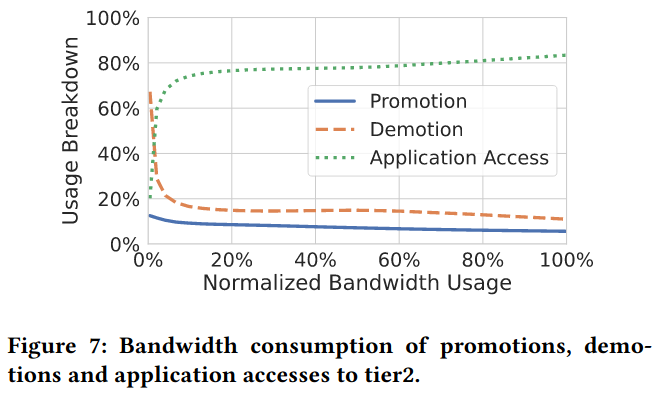
Access ratios / bandwidth are used to understand if the pages in tier2 are accessed frequently (which would impact performance), and whether accesses result in promotions/demotions - “about 80% of tier2 bandwidth is due to applications accessing pages resident in that tier, promotion being about 1/3 of the remaining and demotion 2/3”. The paper argues, “This suggests the system is effective in selecting pages for demotion while avoiding thrashing/ping-pong effects.”
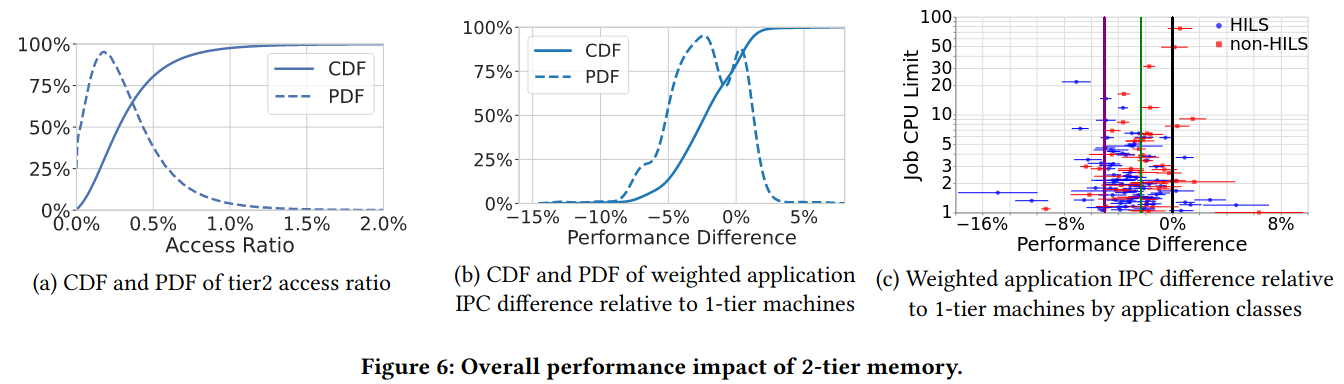
Overall performance impact is core to the tradeoffs that the tiered memory system is making, and the paper uses instructions per cycle (IPC). The authors were targeting a performance impact of 5%, but TMTS impacted a subset of applications more severely.
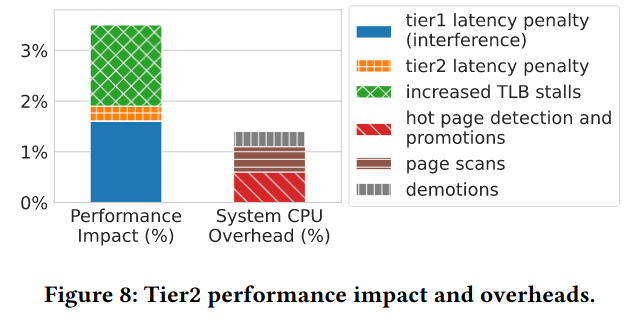
Digging deeper into the performance impact of tier2 memory, one example discussed by the paper is on huge pagesSee Huge Pages are a Good Idea and previous research on hugepages. . Hugepages can take up to large amounts of memory, but accesses to a small part of the hugepage can cause it be promoted. Demoting hugepages is also difficult because while the system was capable of breaking up the hugepages into smaller components when demoting, a “mostly cold” hugepage wouldn’t be demoted at all. Because many hugepages weren’t demoted, they were occupying space in tier1 memory, lowering tier2 memory. The authors describe two solutions including “migrating hugepages intact, without breaking them apart into 4KB pages on demotion” and compacting huge pages to produce more entirely cold pages (which can then be migrated to tier2).
Policy Evaluation
Beyond the performance of the system itself, the paper also considers the impact that different policies can have on its northstar metrics (STRR and STAR).
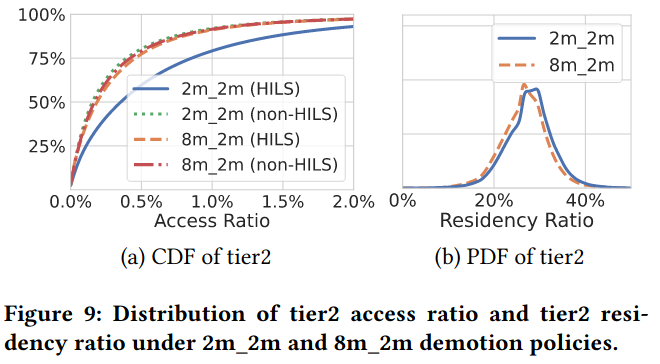
Demotion policies are capable of changing the amount of cold memory in tier2 by trading off performance, for example executing policies more frequently (leading to cold pages moving to tier2 faster). The paper describes tweaking demotion policies according to whether an application serves high importance latency sensitive (HILS)) traffic. Lengthening the time that pages used by HILS applications take to demote to tier2 had minimal impact on percent of tier2 used (STRR), but significant performance impact (represented via STAR, the amount of access ratios for pages in tier2).
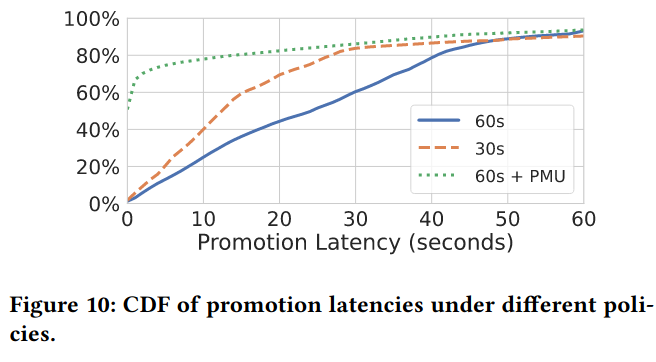
The paper also discusses promotion policies, and argues that applications are actually more sensitive to situations when a page is not yet promoted to tier1, but is frequently accessed. The paper considers three policies to address this concern: 60s promotion (2, 30 second scans), 30s (1 30s scan), and a combination of 60s promotion with PMU-based sampling. Effectively all policies have the same outcome with respect to memory ending up in tier1, but the combined approach (described earlier in the paper) is able to successfully promote pages faster because the PMU-based sampling datasource provides faster information on accesses to tier2 memory.
Conclusion
I found the tiered memory paper interesting because it illustrates the tradeoffs between performance and cost for hardware resources deployed at scale at scale. The research also builds on previous work, but uniquely includes many lessons from production - for example, evaluating policies based on their impact to north star metrics gathered from the wild. Lastly, the system described by the paper is enabled by integrating with a robust, extensible scheduler capable of making informed decisions about job placement. This abstraction allowed successful deployment at scale without involving individual application developers, dramatically decreasing the time to deployment.