micahlerner.com
ghOSt: Fast & Flexible User-Space Delegation of Linux Scheduling
Published December 28, 2021
Found something wrong? Submit a pull request!
Discussion on Hacker News
This is one of the last papers I’m writing about from SOSP - I am trying out something new and publishing the queue of papers I plan on reading here. These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
ghOSt: Fast & Flexible User-Space Delegation of Linux Scheduling
The ghOSt paper describes a system for implementing Linux schedulingThis paper is about CPU scheduling, not data center scheduling (like I covered in a previous paper review). policies in user spaceSee What is difference between User space and Kernel space?. . Operating system scheduling is more complicated for data center workloads, as there are additional factors to consider when deciding what to run and when (like ensuring low latency for user queries). Previous research aims to take higher-level context about applications into consideration when making scheduling decisionsOne example scheduler, Shinjuku, is designed to reduce tail latency. The approach is able to achieve up to 6.6× higher throughput and 88% lower tail latency by implementing a custom scheduling policy. , with dramatic positive results.
Unfortunately, custom schedulers can be difficult to implement, deploy, and maintain. Shinjuku is an exampleThe paper also cites a set of Dune-themed projects, like Caladan and Shenango as prior work in the space that runs into the coupling problem. of a custom scheduler facing these problems - it is designed to reduce tail latency for data center applications, but requires tight coupling between an application and the scheduler. This tight coupling means that changes to the kernel could also unintentionally impact applications using the approach, potentially causing a brittle implementation with high ongoing maintenance costs.
ghOSt aims to address the problems faced by custom schedulers and those who implement them, while facilitating the dramatic performance and scalability gains workload-specific schedulers allow. The key to its approach is separating scheduling logic and the components that interact with the kernel. Custom schedulers, called policies, are moved into user space.
In contrast, relatively stable code that interacts directly with the Linux kernel remains in kernel-space, and exposes an API for the user-space schedulers to interact with. This split approach means that custom schedulers run just like any other application - as a result, they can be implemented in variety of languages, tested using existing infrastructure, and deployed a faster rate for a wider set of workloads.
What are the paper’s contributions?
The paper makes three main contributions: design and implementation of a system that allows custom scheduling logic to run in user space, implementations of several custom schedulers using the system, and evaluation of the architecture (including in a production setting).
Challenges and Design Goals
The paper identifies five challenges to implementing custom schedulers:
- Implementing schedulers is hard because of the constraints posed on kernel code, like restrictions on languagesSupport for Rust in the kernel is a work in progress. and debug toolingSee a previous discussion on difficulties with kernel debugging on HN. .
- Deploying schedulers is even harder because upgrading a kernel requiresTechnically, not all changes to the kernel require a reboot. a time-consuming multi-step process of shifting workloads and rebooting the machine. The potential for kernel upgrades to introduce performance regressions make the process more difficult.
- Custom schedulers must schedule kernel-level threads, not user-level threadsSee Difference between user-level and kernel-supported threads?. - scheduling user-level threads on top of kernel-level threads does not guarantee that the associated kernel-level threads are actually runThe paper notes two approaches that allow developers to overcome the limitations of user-level threads: “(1) Dedicate CPUs to the native threads running the user-threads, thus guaranteeing implicit control. However, this option wastes resources at low workload utilization, because the dedicated CPUs cannot be shared with another application (see §4.2), and requires extensive coordination around scaling capacity. Alternatively, developers can (2) stay at the mercy of the native thread scheduler, allowing CPUs to be shared, but ultimately losing the control over response time that they turned to a user-level runtime for.” .
- Custom schedulers tailored to specific workloads pose their own challenges because they do not adapt well to different use cases (not to mention their internals are complex and potentially not shared across multiple schedulers).
- Existing custom scheduling techniques are not sufficient, in particular Berkeley Packet Filter (BPF)Julia Evans has a great post on BPF, which was originally designed to capture and filter packets inside of the kernel. More recently, eBPF extends the idea to other parts of the kernel - see A thorough introduction to eBPF for more details on how BPF/eBPF works. There is also an exciting ecosystem building around eBPF tooling, like Cilium and Isovalent, the company behind the tool, recently raised money from Andreessen Horowitz. . While BPF programs are amazingly cool, they run synchronously and block the CPU - non-ideal from a performance perspectiveIt is worth noting that the paper does mention using BPF for fast-path .
These challenges translate into four design goals for the system:
- Custom scheduling logic should be easy to implement and test: separating scheduling logic from the kernel simplifies development and testing.
- It should be possible to easily create scheduling logic for many different use cases: unlike previous specialized schedulers built into the kernel, ghOSt aims to be a generic platform that schedulers can be built on top of.
- Scheduling should be able to operate across multiple CPUs: existing Linux schedulers make per-CPU scheduling decisions and it is difficult to execute scheduling decisions over a set of CPUs to optimize for other properties, like tail latencyThe paper cites a number of previous systems (like Shenango: Achieving high CPU efficiency for latency-sensitive datacenter workloads) that achieve their goals by scheduling across multiple CPUs .
- Non-disruptive updates and fault isolation: it should be easy to deploy scheduling logic like one would with other tasks running on a machine, allowing updates without requiring a reboot. Furthermore, failures or regressions in scheduling policies should not crash the whole machine.
Design and Implementation
To achieve the goals of the system, ghOSt introduces policies (custom scheduling logic). Policies are executed in user-space and associated scheduling decisions are communicated to the kernel.
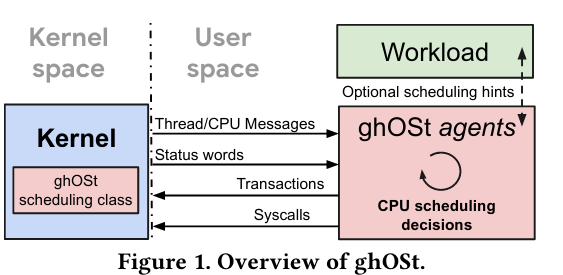
Policies (and their scheduling decisions) propagate over three main components running across kernel and user space:
- The ghOSt scheduling classHere is a great article about scheduling classes and Linux’s Completely Fair Scheduler. There is also the man page about the related
schedsystem call. runs inside of the Linux kernel and provides a syscall interface that other components use to communicate scheduling decisions. - Agents run policies (custom scheduling logic) in user-space, and make scheduling decisions that they communicate to the ghOSt scheduling class running in kernel-space.
- Enclaves are groups of agents. Each enclave has a primary agent that makes the scheduling decisions. Assigning multiple agents to an enclave provides redundancy in the case of the primary agent failing.
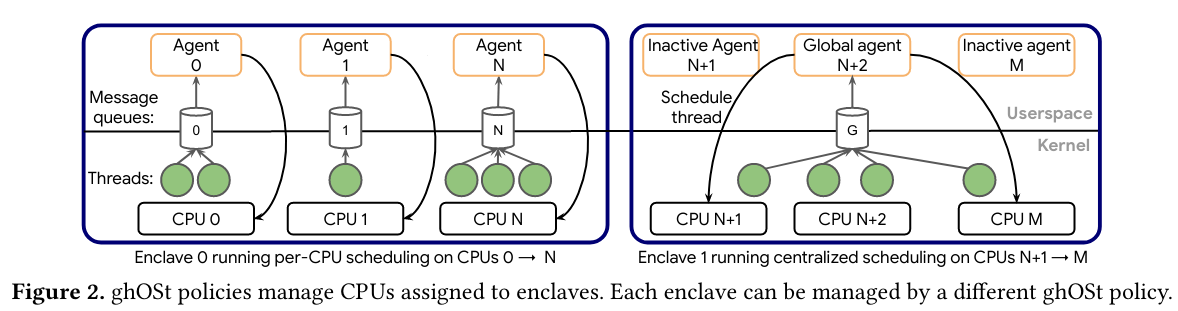
Communication
ghOSt components running in kernel or user-space need a way to provide information and feedback to each other. The paper discusses the two primary communication flows: kernel-to-agent and agent-to-kernel.
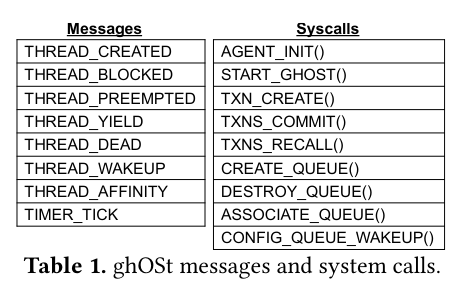
In the kernel-to-agent flow, the kernel communicates to agents using messages and message queuesDefinition of the messages here. . The kernel sends messages on queues when events happen in the kernel that could impact scheduling decisions. Each CPU has an associated queue, and each queue is associated with an enclaveNot every agent has a message queue because in some configurations there is a single primary agent for the enclave that is receiving information from the kernel - reference the enclave diagram above for a visual representation of this idea. . While there are several existing queue approaches (including io_uring or BPF ring buffers), not all kernel versions support them - the authors argue that this makes ghOSt’s queue abstraction necessary.
In the agent-to-kernel direction, the agent communicates by making system calls to communicate scheduling decisions and to perform management operations on the shared queue. To send scheduling decisions, the agent creates and commits transactions (like TXN_CREATE() and TXNS_COMMIT()). Transactions are important because they allow a policy to make scheduling decisions across a range of CPUs, ensuring all or none succeed, while batching scheduling information - batching is critical because it limits the number of interrupts that impact the to-be-scheduled CPUs (as the kernel component of ghOSt needs to respond to agent transactions).
Lastly, there is a challenge to both kernel-to-agent and agent-to-kernel communication: keeping up to date with the state of the system. The kernel needs to ensure that it doesn’t execute out of date scheduling decisions, and the agent need to make sure that it doesn’t make scheduling decisions based on an old state of the world. The key piece of information used to track state is a sequence number that exists for every agent.
In kernel-to-agent commmunication, the kernel provides the sequence number to agents in each message, and in a shared memory region. The sequence number in shared memory is updated by the kernel whenever it publishes a new message. The agent consumes the sequence number from shared memory when reading messages from the queue, comparing the value to the sequence number in shared memory. When the sequence number from consumed messages matches the value in shared memory, the agent knows it has read an up to date state.
In agent-to-kernel communication, the agent includes the sequence number when sending scheduling decisions (via transactions) to the kernel. The kernel compares the sequence number from the agent’s transaction with the most recent sequence number the kernel is aware of. If the transaction’s sequence number is too old, the kernel doesn’t execute the scheduling decision.
Evaluation
To evaluate ghOSt, the paper considers the overheads associated with the system, compares ghOSt to previous custom scheduler implementations, and evaluates the system in production.
ghOSt overhead
To evaluate the overheads of the system, the paper includes microbenchmarks that show the time spent in the different parts of the scheduling system, showing that it is competitive.

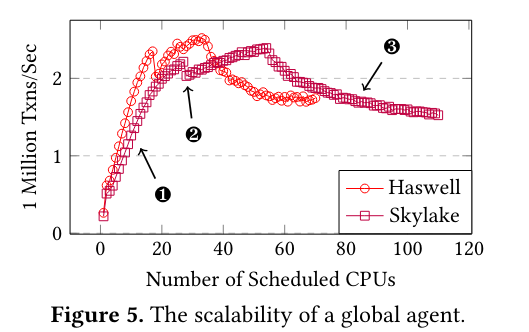
The paper also determines the performance of a global scheduler (that schedules all cores on a system) implemented with ghOSt - previous research shows the potential advantage of this approach as the scheduler has more complete knowledge of the system. The evaluation shows that ghOSt is able to scale to millions of transactions, even when responsible for many CPUs.
Comparison to existing systems
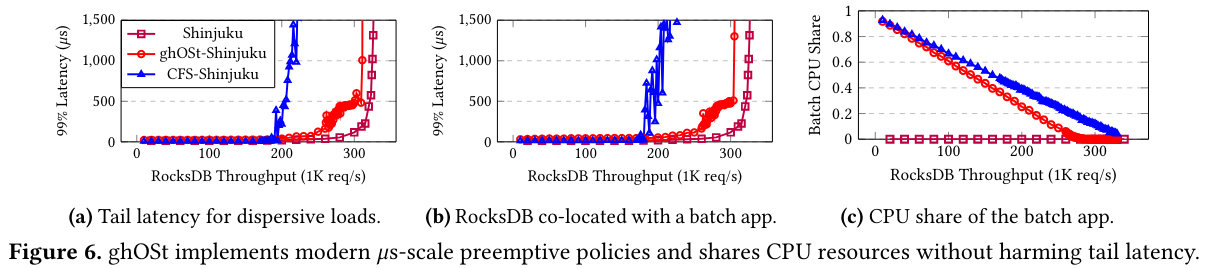
Next, the paper compares ghOSt to ShinjukuSee the Shinjuku paper. , an example of a custom scheduling system tailored to reduce tail latency. The goal of this evaluation is to see whether ghOSt performs similarly to a custom scheduler (which theoretically could achieve higher performance by using tailored optimization techniques). Shinjuku has a number of differences from ghOSt - it uses dedicated resources (spinning threads that consume all of a CPU or set of CPUs), is constrained to a physical set of cores, and takes advantage of virtualization features to increase performance (like posted interrupts). The authors also port the Shinjuku scheduling policy itself so that it is compatible with ghOSt.
The two systems run a generated workload, “in which each request includes a GET query to an in-memory RocksDB key-value store and performs a small amount of processing”.
The results indicate:
ghOSt is competitive with Shinjuku for 𝜇s-scale tail workloads, even though its Shinjuku policy is implemented in 82% fewer lines of code than the custom Shinjuku data plane system. ghOSt has slightly higher tail latencies than Shinjuku at high loads and is within 5% of Shinjuku’s saturation throughput.
Production traces
Lastly, the paper runs a production workload against ghOSt and compares the results to the same workload executed by machines using the completely fair scheduler (CFS)More info on the Completely Fair Scheduler here - on the older side, but seems like it was updated relatively recently. .
The workload contains three query types (CPU and memory bound, IO and memory bound, and CPU-bound) - ghOSt is able to reduce tail-latency for the first two types of requests, but doesn’t have a huge impact for the thirdThe paper does note that it is possible to impact compute bound tasks by extending the ghOSt policy with similar logic to what Linux’s CFS contains around nice values. .
What stood out to me the most about this section is actually ghOSt’s impact on developer productivity:
When developing a kernel scheduler, the write-test-write cycle includes (a) compiling a kernel (up to 15 minutes), (b) deploying the kernel (10-20 minutes), and (c) running the test (1 hour due to database initialization following a reboot). As a result, the enthusiastic kernel developer experiments with 5 variants per day. With ghOSt, compiling, deploying and launching the new agent is comfortably done within one minute.
Conclusion
The ghOSt paper builds on a body of previous research that demonstrates how critical scheduling is to the scalability and performance of datacenter workloads. Scheduling is far from a solved problem, especially because of the “rise of the killer microsecond” and new device types - I’m looking forward to following along future work on the ghOSt open source project!
As always, feel free to reach out on Twitter with feedback. Until next time.