micahlerner.com
Scaling Large Production Clusters with Partitioned Synchronization
Published October 10, 2021
Found something wrong? Submit a pull request!
Discussion on Hacker News
This is one of the last papers we will be reading from Usenix ATC and OSDI. There are several great conferences coming up over the next few months that I’m excited to read through together. Next week we will be moving on to VLDB (Very Large Data Bases), and SOSP (Symposium on Operating Systems Principles) is coming up later this month. As always, feel free to reach out on Twitter with feedback or suggestions about papers to read! These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed.
Scaling Large Production Clusters with Partitioned Synchronization
This week’s paper review won a best paper award at Usenix ATC, and discusses Alibaba’s approach to scaling their production environment. In particular, the paper focuses on the evolution of the scheduling architecture used in Alibaba datacenters in response to growth in workloads and resourcesAn increase in resources or workloads impacted the load on the existing scheduler architecture. The former translates into more options for the scheduler to choose from when scheduling, and the latter means more computation that needs to be performed by the scheduler. . Beyond discussing Alibaba’s specific challenges and solutions, the paper also touches on the landscape of existing scheduler architectures (like Mesos, YARN, and Omega).
Scheduler architectures
The paper first aims to decide whether any existing scheduling architectures meet the neeeds of Alibaba’s production environment - any solution to the scaling problem’s encountered by Alibaba’s system needed to not only scale, but also simultaneously provide backward compatibility for existing users of the cluster (who have invested significant engineering effort to ensure their workloads are compatible with existing infrastructure).
To evaluate future scheduler implementations, the authors considered several requirements:
- Low scheduling delay: the selected scheduler should be capable of making decisions quickly.
- High scheduling quality: if a task specifies preferences for resources, like running on “machines where its data are stored” or “machines with larger memory or faster CPUs”, those preferences should be fulfilled as much as possible.
- Fairness: tasks should be allocated resources according to their needs (without being allowed to hog them)There are a number of interesting papers on fairness, like Dominant Resource Fairness: Fair Allocation of Multiple Resource Types (authored by founders of Spark and Mesos).
- Resource utilization: the scheduler should aim to use as much of the cluster’s resources as possible.
These requirements are then applied to four existing scheduler architecturesThe Omega paper is also an excellent resource on this topic, and the figure below is sourced from there :
- Monolithic: an architecture with a single instance that lacks parallelism, common in HPC settings or lower-scale cloud environments.
- Statically partitioned: generally used for fixed-size clusters that run dedicated jobs or workloads (like Hadoop).
- Two-level: a scheduling strategy where a central cordinator assigns resources to sub-schedulers. This is implemented by Mesos, which uses “frameworks” to schedule tasks on resources offered by the central scheduler. Examples of frameworks are batch schedulers, big data processing systems (like Spark), and service schedulers. A Mesos-like implementation is labeled “pessimistic concurrency control” because it aims to ensure that there will few (or no) conflicts between schedulers.
- Shared-state: one or more schedulers read shared cluster metadata about resources, then use that metadata to make scheduling decisions. To schedule tasks, the independent schedulers try to modify the shared state. Because multiple schedulers are reading from and attempting to write to the same state, modifications may conflict. In the event of a conflict, one scheduler succeeds and others fail (then re-evaluate their scheduling decisions). Omega is a shared-state scheduler cited by the authors. An Omega-like implementation utilizes “optimistic concurrency control” because the design assumes that there will be few conflicts between schedulers (and only performs additional work to resolve conflicts when they actually happen).
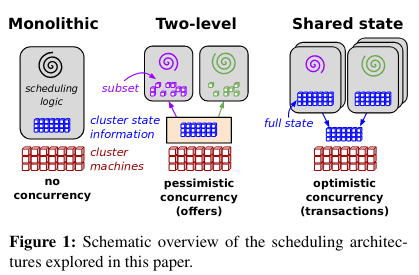
The authors decide, after applying their requirements to existing scheduler architectures, to extend the design of Omega.
After making this decision, the paper notes that a potential issue with an Omega-based architecture at scale is contention. Contention occurs when multiple schedulers attempt to schedule tasks with the same resources - in this situation, one of the scheduling decisions succeeds, and all others could be rejected (meaning that the schedulers who issued the now-failed requests need to re-calculate scheduling decisions.
The authors spend the majority of the paper evaluating how contention can be reduced, as it could pose a limit to the scalability of the future scheduler. In the process, the paper performs multiple simulations to evaluate the impact of adjusting critical scheduling-related variables.
What are the paper’s contributions?
The paper makes three contributions. After outlining existing scheduler architectures, it evaluates (using simulation techniques) how the selected approach would handle possible contention if adopted in Alibaba’s production environment. Using these results, the paper suggests an extension to the shared-state scheduling architecture. Lastly, the paper characterizes the performance of this solution, and provides a framework for simulating its performance under a variety of loads.
Modeling scheduling conflicts
As mentioned above, more tasks competing for the same set of resources means contention - jobs will try to schedule tasks to the same slots (“slots” in this context correspond to resources). Given the optimistic concurrency control approach taken in an Omega-influenced shared-state scheduler, the paper argues that there will be latency introduced by scheduling conflicts.
To evaluate potential factors that impact in a cluster under high load, the paper considers the effect of additional schedulers. Adding extra schedulers (while keeping load constant) spreads the load over more instances. Lower per-scheduler loads corresponds to lower delay in the event of contentionIf a scheduling decision fails, the failed request doesn’t compete with a long queue of other requests. , although there are diminishing returns to flooding the cluster with schedulersNot to mention the cost of adding more schedulers - each scheduler likely has multiple backup schedulers running, ready to take over if the primary fails. .
For each number of schedulers, the simulation varies:
- Task Submission Rate: the number of decisions the cluster needs to make per unit time.
- Synchronization Gap: how long a scheduler has in between refreshing its state of the cluster.
- Variance of slot scores: the number of “high-quality” slots available in the system. This is a proxy for the fact that certain resource types in the cluster are generally more preferred in the cluster, leading to hotspots.
- The number of partitions of the master state: how many subdivisions of the master state there are (each part of the cluster’s resources would be assigned to a partition).
To evaluate the performance of different configurations, the experiment records the number of extra slots required to maintain a given scheduling delay. The count of additional slots is a proxy for actual performance. For example, if the task submission rate increases, one would expect that the number of extra slots required to maintain low scheduling delay would also increase. On the other hand, changing experimental variables (like the number of partitions of the master state) may not require more slots or schedulers.
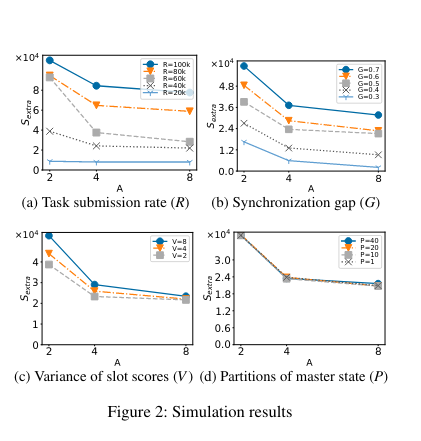
The experimental results indicate that flexibility in the system lies in the quality of the scheduling (Variance of slot scores) and in the staleness of the local states (Synchronization Gap).
In other words, scheduling can scale by:
- Relaxing constraints on scheduling decisions, possibly scheduling tasks to resources that are slower or don’t exactly fit the job’s needs).
- Communicating more with nodes in order to get updated state about their resources: A scheduler that updates its state more frequently would have a more up-to-date view of the cluster (meaning that it would make fewer scheduling decisions that collide with recent operations by the other schedulers in the cluster). State syncing from cluster nodes to a centralized store is costly and grows with the number of nodes.
Partitioned Synchronization
Up to date scheduler state leads to lower contention, but syncing the required state from nodes to achieve this goal is costly (both in networking traffic and space). To address this cost, the authors suggest an approach called partitioned synchronization (a.k.a ParSync) with the goal, “to reduce the staleness of the local states and to find a good balance between resource quality (i.e., slot score) and scheduling efficiency”. ParSync works by syncing partitions of a cluster’s state to one of the manyThe previous section notes that there are significant performance benefits to adding schedulers in a shared-state architecture, up to a point. schedulers in a cluster. Then, the scheduling algorithm weights the recency (or staleness) of a partition’s state in scheduling decisions.
The authors argue that short-lived low latency tasks, as well as long-running batch jobs benefit from ParSync. For example, if a task is short lived, it should be quickly scheduled - a non-ideal scheduler would take more time making decisions than the task takes to actually run. In this situation, ParSync-based scheduling can assign the task to a recently updated partition, with high likelihood that the scheduling decision will succeed - other schedulers will not update the partition’s state at the same time, instead preferring their own recently updated partitions. On the other side of the spectrum, a long running job might prefer certain resources, trading off more time spent making a scheduling decision for running with preferred resources.
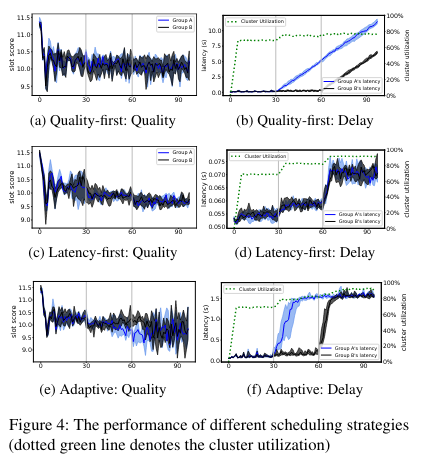
ParSync is coupled with three scheduling strategies:
- Quality-first: optimize for use of preferred resources.
- Latency-first: optimize for faster scheduling decisions (even if they are non-optimal).
- Adaptive: use the Quality-first or Latency-first strategy depending on whether scheduling delay is high or not. If there is low scheduling delay, the scheduler will prefer quality-first. If there is high scheduling delay, the scheduler prefers latency-first.
The next section discusses the performance of the three different strategies.
Evaluation
The paper results indicate that both quality-first and latency-first scheduling strategies don’t adapt to conditions they are not optimized for. Quality-first scheduling experiences latency at high load (when the scheduler should make decisions quickly), while latency-first scheduling generally makes worse scheduling decisions under low load (when the scheduler could take more time and choose ideal resources). In contrast, the adaptive strategy is able to switch between the aforementioned strategies, while achieving high resource utilization.
Conclusion
This paper discusses a number of interesting scheduler architectures, as well as touching on the body of work covering scheduler internalsSee Dominant Resource Fairness: Fair Allocation of Multiple Resource Types and Firmament: Fast, Centralized Cluster Scheduling at Scale (which I would love to read in the future). While the content of this paper leans heavily on simulation, there is a discussion of performance evaluation using internal Alibaba tools - I’m hopeful that we will be able to learn more about the real world performance of the team’s scheduler in future research (as we often see with industry papers).
As always, feel free to reach out on Twitter with any feedback or paper suggestions. Until next time!