micahlerner.com
Firecracker: Lightweight Virtualization for Serverless Applications
Published June 17, 2021
Found something wrong? Submit a pull request!
Firecracker: Lightweight Virtualization for Serverless Applications Agache et al., NSDI ‘20
This week’s paper review is a bit different than the past few weeks (which have been about distributed key-value stores). Inspired by all of the neat projects being built with the technology discussed in this paper, I decided to learn more. As always, feel free to reach out on Twitter with feedback or suggestions about papers to read! These paper reviews can be delivered weekly to your inbox, or you can subscribe to the new Atom feed.
Firecracker is a high-performance virtualization solution built to run Amazon’s serverlessServerless meaning that the resources for running a workload are provided on-demand, rather than being paid for over a prolonged time-period. Martin Fowler has some great docs on the topic here. applications securely and with minimal resources. It now does so at immense scale (at the time the paper was published, it supported “millions of production workloads, and trillions of requests per month”).
Since the paper was published, there has a been a buzz of interesting projects built with Firecracker. Fly.io (a speed-focused platform for running Docker applicationsApologies if a Fly.io engineer reads this and has a different short summary of the company. I did my best. ) wrote about using the technology on their blog, Julia Evans wrote about booting them up for a CTF she was building, and Weave Ingite lets you launch virtual machines from DockerVirtual machines and containers are sometimes conflated to be one and the same, but the internals are different. The difference is discussed later in this paper review! :) containers (and other OCIOCI stands for “Open Container Initiative” and works to define standards for containers and the software that runs them. A nice thing about OCI containers is that you can run them (with a container runtime) that complies with the standards, but has different internals. For example, one could choose Podman instead of Docker. images).
Now that you are excited about Firecracker, let’s jump into the paper!
What are the paper’s contributions?
There are two main contributions from the paper: the Firecracker system itself (already discussed above), and the usage of Firecracker to power AWS Lambda (Amazon’s platform for running serverless workloads).
Before we go further, it is important to understand the motivation behind building Firecracker in the first place.
Originally, Lambda functions ran on a separate virtual machine (VM) for every customer (although functions from the same customer would run in the same VM). Allocating a separate VM for every customer was great for isolating customers from each other - you wouldn’t want Company A to access Company B’s code or functionality, nor for Company A’s greedy resource consumption to starve Company B’s Lambdas of resources.
Unfortunately, existing VM solutions required significant resources, and resulted in non-optimal utilization. For example, a customer might have a VM allocated to them, but the VM is not frequently used. Even though the VM isn’t used to its full capacity, there is still memory and CPU being consumed to run the VM. The Lambda system in this form was less-efficient, meaning it required more resources to scale (likely making the system more expensive for customers).
With the goal of increasing utilization (and lowering cost), the team established constraints of a possible future solution:
- Overhead and density: Run “thousands of functions on a single machine, with minimal waste”. In other words, solving one of the main problems of the existing architecture.
- Isolation: Ensure that applications are completely separate from one another (can’t read each other’s data, nor learn about them through side channels). The existing solution had this property, but at high cost.
- Performance: A new solution should have the same or better performance as before.
- Compatibility: Run any binary “without code changes or recompilation”. This requirement was there, even though Lambda oringally supported a small set of languages. Making a generic solution was planning for the long-term!
- Fast Switching: “It must be possible to start new functions and clean up old functions quickly”.
- Soft Allocation: “It must be possible to over commit CPU, memory, and other resources”. This requirement impacts utilization (and in turn, the cost of the system to AWS/the customer). Overcommittment comes into play a few times during a Firecracker VM’s lifetime. For example, when it starts up, it theoretically is allocated resources, but may not be using them right away if it is performing set up work. Other times, the VM may need to burst above the configured soft-limit on resources, and would need to consume those of another VM. The paper note’s “We have tested memory and CPU oversubscription ratios of over 20x, and run in production with ratios as high as 10x, with no issues” - very neat!
The constraints were applied to three different categories of solutions: Linux containers, language-specific isolation, and alternative virtualization solutions (they were already using virtualization, but wanted to consider a different option than their existing implementation).
Linux containers
There are several Isolation downsides to using Linux containers.
First, Linux containers interact directly with a host OS using syscallsSyscalls are a standard way for programs to interact with an operating system. They’re really neat. I highly reccommend Beej’s guide to Network Programming for some fun syscall programming . One can lock-down which syscalls a program can make (the paper mentions using Seccomp BPF), and even which arguments the syscalls can use, as well as using other security features of container systems (the Fly.io article linked above discusses this topic in more depth).
Even using other Linux isolation features, at the end of the day the container is still interacting with the OS. That means that if customer code in the container figures out a way to pwn the OS, or figures out a side channel to determine state of another container, Isolation might break down. Not great.
Language-specific isolation
While there are ways to run language-specific VMs (like the JVM for Java/Scala/Clojure or V8 for Javascript), this approach doesn’t scale well to many different languages (nor does it allow for a system that can run arbitrary binaries - one of the original design goals).
Alternative Virtualization Solutions
Revisiting virtualization led to a focus on what about the existing virtualization approach was holding Lambda back:
- Isolation: the code associated with the components of virtualization are lengthy (meaning more possible areas of exploitation), and researchers have escaped from virtual machines before.
- Overhead and density: the components of virtualization (which we will get into further down) require too many resources, leading to low utilization
- Fast switching: VMs take a while to boot and shut down, which doesn’t mesh well with Lambda functions that need a VM quickly and may only use it for a few seconds (or less).
The team then applied the above requirements to the main components of the virtualization system: the hypervisor and the virtual machine monitor.
First, the team considered which type of hypervisor to choose. There are two types of hypervisors, Type 1 and Type 2. The textbook definitions of hypervisors say that Type 1 hypervisors are integrated directly in the hardware, while Type 2 hypervisors run an operating system on top of the hardware (then run the hypervisor on top of that operating system).

Linux has a robust hypervisor built into the kernel, called Kernel Virtual Machine (a.k.a. KVM) that is arguably a Type 1 hypervisorDifferent resources make different arguments for whether KVM is a Type 1 or Type 2 hypervisor. .
Using a hypervisor like KVM allows for kernel components to be moved into userspace - if the kernel components are in user space and they get pwned, the host OS itself hasn’t been pwned. Linux provides an interface, virtioFun fact: the author of the paper on virtio, Rusty Russell, is now a key developer of a main Bitcoin Lightning implementation. , that allows the user space kernel components to interact with the host OS. Rather than passing all interactions with a guest kernel directly to the host kernel, some functions, in particular device interactions, go from a guest kernel to a virtual machine monitor (a.k.a. VMM). One of the most popular VMMs is QEMU.

Unfortunately, QEMU has a significant amount of code (again, more code means more potential attack surface), as it supports a full range of functionality - even functionality that a Lambda would never use, like USB drivers. Rather than trying to pare down QEMU, the team forked crosvmI enjoyed this post on crosvm from a former Google intern. (a VMM open-sourced by Google, and developed for ChromeOS), in the process significantly rewriting core functionality for Firecracker’s use case. The end result was a slimmer library with only code that would conceivably be used by a Lambda - resulting in 50k lines of Rust (versus > 1.4 million lines of C in QEMURelatedly, there was an interesting blog post about QEMU security issues and thoughts on Rust from a QEMU maintainer. ). Because the goal of Firecracker is to be as small as possible, the paper calls the project a MicroVM, rather than “VM”.
How do Firecracker MicroVMs get run on AWS?
Now that we roughly understand how Firecracker works, let’s dive into how it is used in running Lambda. First, we will look at how the Lambda architecture works on a high level, followed by a look at how the running the Lambda itself works.
High-level architecture of AWS Lambda
When a developer runs (or Invokes, in AWS terminology) a Lambda, the ensuing HTTP request hits an AWS Load Balancer Lambdas can also start via other events - like ‘integrations with other AWS services including storage (S3), queue (SQS), streaming data (Kinesis) and database (DynamoDB) services.’ .
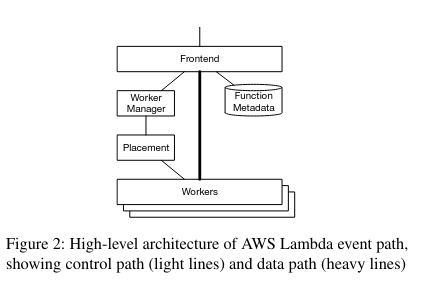
There are a four main infrastructure components involved in running a Lambda once it has been invoked:
- Workers: The components that actually run a Lambda’s code. Each worker runs many MicroVMs in “slots”, and other services schedule code to be run in the MicroVMs when a customer Invokes a Lambda.
- Frontend: The entrance into the Lambda system. It receives Invoke requests, and communicates with the Worker Manager to determine where to run the Lambda, then directly communicates with the Workers.
- Worker Manager: Ensures that the same Lambda is routed to the same set of Workers (this routing impacts performance for reasons that we will learn more about in the next section). It keeps tracks of where a Lambda has been scheduled previously. These previous runs correspond to “slots” for a function. If all of the slots for a function are in use, the Worker Manager works with the Placement service to find more slots in the Workers fleet.
- Placement service: Makes scheduling decisions when it needs to assign a Lambda invocation to a Worker. It makes these decision in order to “optimize the placement of slots for a single function across the worker fleet, ensuring that the utilization of resources including CPU, memory, network, and storage is even across the fleet and the potential for correlated resource allocation on each individual worker is minimized”.
Lambda worker architecture
Each Lambda worker has thousands of individual MicroVMs that map to a “slot”.
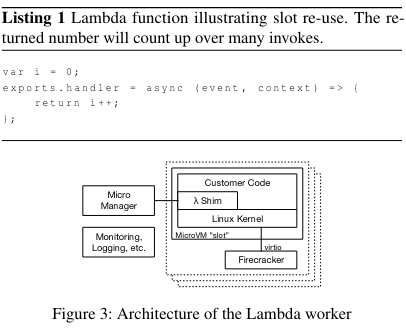
Each MicroVM is associated with resource constraints (configured when a Lambda is setup) and communicates with several components that allow for scheduling, isolated execution, and teardown of customer code inside of a Lambda:
- Firecracker VM: All of the goodness we talked about earlier.
- Shim process: A process inside of the VM that communicates with an external side car called the Micro Manager.
- Micro Manager: a sidecar that communicates over TCP with a Shim process running inside the VM. It reports metadata that it receives back to the Placement service, and can be called by the Frontend in order to Invoke a specific function. On function completion, the Micro Manager also receives the response from the Shim process running inside the VM (passing it back to the client as needed).
While slots can be filled on demand, the Micro Manager also starts up Firecracker VMs in advance - this helps with performance (as we will see in the next section).
Performance
Firecracker was evaluated relative to similar VMM solutions on three dimensions: boot times, memory overhead, and IO Performance. In these tests, Firecracker was compared to QEMU and Intel Cloud HypervisorInterestingly, Firecracker wasn’t compared to crosvm. I am not sure if this is because it wasn’t possible, or whether the authors of the paper thought it wouldn’t be a fair comparison. . Additionally, there are two configurations of Firecracker used in the tests: Firecracker and Firecracker-pre. Because Firecracker MicroVMs are configured via API calls, the team tested setups where the API calls had completed (Firecracker-pre, where the “pre” means “pre-configured”) or had not completed (regular Firecracker). The timer for both of these configurations ended when the init process in the VM started.
Boot times
The boot time comparisons involved two configurations: booting 500 total MicroVMs serially, and booting 1000 total MicroVMs, 50 at a time (in parallel).
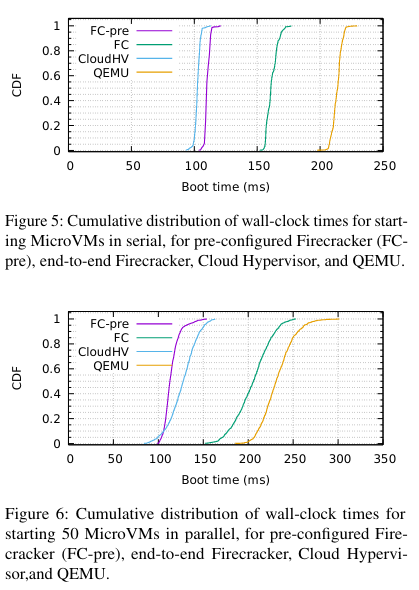
The bottom line from these tests is that Firecracker MicroVMs boot incredibly quickly - Fast switching ✅ !
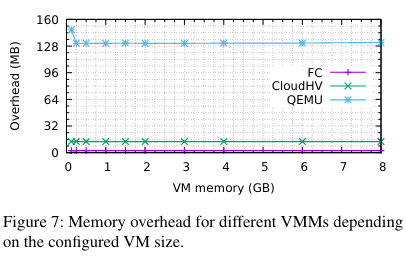
Memory overhead
Relative to the other options, Firecracker uses significantly less memory - overhead and density ✅!
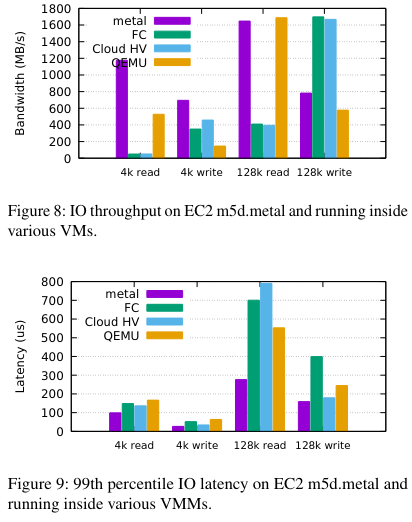
IO Performance
Relative to the other options, Firecracker and the comparable solution of Intel’s Cloud Hypervisor didn’t perform well in all tests. The paper argues that the causes of relatively inferior performance in the IO tests are no flushing to disk and an implementation of block IOs that performs IO serially - the paper notes that “we expect to fix these limitations with time”. Digging into Github issues for Firecracker, I found one that indicates they were prototyping use of io_uring to support async IO (and increase IO performance).
Conclusion
Firecracker was interesting to learn about because it is a high-performance, low overhead VMM written in Rust. The paper also is a great study in pragmatic technical decision making - rather than rewriting already robust software (KVM), the team focused on a specific component of an existing system to improve. Along the way, we learned about how different methods for isolating customer workloads from each other In particular, I thought seccomp-bpf was interesting and look forward to learning more about BPF/eBPF. First stop: Julia Evans’ guide .
If you made it this far, you probably enjoyed the paper review - I post them on my Twitter every week!