micahlerner.com
POSH: A Data-Aware Shell
Published August 07, 2021
Found something wrong? Submit a pull request!
Discussion on Hacker News
This is the fourth paper in a series on “The Future of the Shell”Here are links to Part 1, Part 2, and Part 3. . These weekly paper reviews can be delivered weekly to your inbox, or you can subscribe to the new Atom feed. Over the next few weeks I will be reading papers from Usenix ATC and OSDI - as always, feel free to reach out on Twitter with feedback or suggestions about papers to read!
POSH: A Data-Aware Shell Deepti Raghavan, et. al
This week’s paper review covers POSH, a system capable of achieving dramatic speedups for unmodifiedRequiring fewer changes to a shell script in order to make it POSH-compatible simplifies adoption. shell scripts that perform large amounts of IO - intriguing use cases of POSH are log analysis or the git workflows of large software projectsThe paper analyzes git workflows for Chromium. . In particular, POSH shines in environments that use distributed file systems like Network File SystemNFS allows you to “mount” a remote disk to your computer and then sends RPC calls to a remote server to perform file accesses. I highly recommend this amazing (and free!) description of NFS from Operating Systems: Three Easy Pieces. The entire book is available for free online here. (NFS) mounts - I’ve included a link to a great overview of NFS in the sidebar (or if you are on mobile, you can click the number “4” to reveal it).
POSH achieves speedups by minimizing data transfers in scripts that use networked storage. To minimize data transfers, POSH can execute parts of a script that read or write remote files in a process on the remote machine. As an example, consider a grep of a file stored on a remote machine. When a clientClient in this case meaning the computer where the script was initiated by a user. computer attempts to grep the file, the shell will transfer the whole file over the network to the client node, then filter the file on the client. In contrast, POSH can perform the grep on the remote storage server, and only transfer the filtered output back to the client, dramatically lowering network traffic.
To make decisions about which parts of a script are executed remotely, POSH produces a graph representation of the shell script’s execution - the nodes in the graph are commands, while the edges represent the flow of data between commands. Correctly transforming a shell script into this graph representation is a nuanced, yet critical function. To facilitate it, POSH leverages an annotation language capable of describing a given command’s parameters, inputs, and outputs (as well as a number of important configuration options).
POSH and the system described in last week’s paper review, PaSh, are similar in that they both aim to speedup shell script execution without requiring modifications to the original script. Additionally, they both leverage annotations of shell commands in their implementations. Even though the two projects are similar in some respects, PaSh and POSH focuses on different uses cases - PaSH focuses on parallelizing “trivially parallelizable” computation local to a machine, while POSH focuses on parallelizing scripts that perform large amounts of IO across remote machines. Both projects are part of an exciting (and high impact) thread of research related to modernizing the shell, and I’m looking forward to seeing more from the two teams!
What are the paper’s contributions?
The paper makes two contributions. The first is an annotation language that describes a shell command. These command specifications are used to transform the script into a graph representation - the different steps of a script’s execution are the nodes, and the data flow between those nodes are the edges. The second contribution is a scheduling algorithm that decides how the steps in a script should be executed, taking into account the dependencies in the script’s graph representation as well as the interactions that a step has with remote storage.
Before we dive into the details of these two contributions, it is first helpful to understand POSH’s three high level components:
- Annotation interface: As mentioned above, the annotation language allows a shell script to be correctly transformed into a graph representation.
- Parser and scheduler: The parser uses the aforementioned annotations to produce a graph representation of a shell script. The scheduler uses this graph representation to assign the execution of steps to remote or local nodes called proxy servers. The internals of the scheduling process are detailed later on in this paper review.
- Execution engine: Once the scheduler has assigned work to a proxy server, that work will be executed, and the result will be transferred over the network back to the client node.
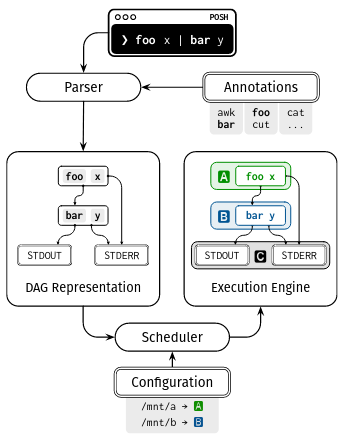
Shell annotation language
POSH uses its shell annotation language to describe the constraints of any given shell command’s execution. These annotations are then used to transform a shell script into a correct graph representation that, when scheduled, will accomplish POSH’s goal of minimizing network traffic.
The paper outlines three questions that POSH (and the annotation language) must answer to achieve the system’s goals:
- Which commands can be executed on remote nodes (called proxy servers)?: this is important for determining what must run locally, versus what can run on a remote proxy server.
- Do any commands in a provided script “filter their input”?: knowing if a command does or does not filter its input is useful for determining whether it should be executed remotely in conjunction with other commands. The paper provides the example of a executing a
catfollowed by agrepon the same remote proxy server - as “cat usually produces the same amount of output as input, but grep usually filters its input, POSH must also offload grep” to minimize network traffic. - Can a command be parallelized?: to enable optimal scheduling, POSH should aim to parallelize a command as much as possible. Without an annotation language, the system might not be have the information it needs to make scheduling decisions. One motivating example is
cat file1 file2 file3- the annotation language defines that the inputs tocatare “splittable”, meaning that it might be possible run the three commandscat file,cat file2, andcat file3in parallel on different machines.
I wanted to note two important components of the annotation language important to understanding the rest of the paperThe paper provides a significant amount of detail on the annotation language and I highly recommend referring to the original paper if this is interesting to you! . First, the annotations can be defined per command and per argument - this flexibility is important because different arguments to a command can change its behavior and arguments. Second, a command’s inputs/outputs can be typed, and its behavior is defined. For example, the annotation language can indicate a command’s parallelizablityAs an example, cat is annotated with splittable to indicate that it is potentially parallelizable. or whether the command relies on the current directoryAn example being git add is dependent on the current directory. . Defining these properties of a command allow the parser and scheduler to answer the three questions above.
The next section covers how a graph representation of a shell script, produced by passing the shell script through POSH’s parser, is scheduled and executed.
Scheduling
As discussed above, each shell script is passed through the POSH parser to produce a graph representation. The nodes in the graph representation are then scheduled to execute based on a two step process that resolves scheduling constraints and minimizes network transfers.
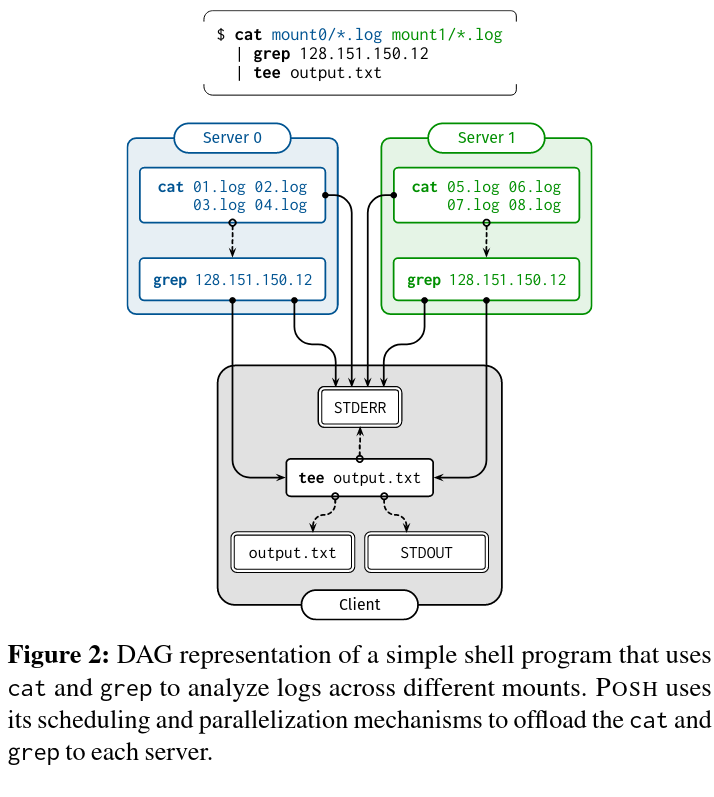
The first step of scheduling, resolving constraints, determines whether any nodes in the graph must run on a given remote machine (and if so, which one). Scheduling constraints are created for a variety of reasons - one example constraint is for a command that accesses remote files. To avoid transferring the whole file over the network, that command must be scheduled on the remote node.
The second step, minimizing data transfer, assigns commands to a remote machine if the command was not assigned in the first step. For this assignment, POSH makes use of some graph theory and implements an algorithm using sources, sinks, and pathsTo quote Steve Yegge, “Graphs are, like, really really important.” . A source is a “file that is read”, a sink is the “output file that is written to”, and paths connect them. To assign nodes, POSH iterates over every source node, checking whether the sink and source node in the path are already assigned to the same machine - if they are, assign all the intermediate nodes along the path to that machine as well! If the sink is not on the same machine, “the scheduler must find the edge along which cross-location data transfer should occur: to minimize data transfer, this should be the edge where the least data flows.” The paper describes a set of heuristics (implemented here in Rust!) used to find the min-cut edge in the path. After this edge is found, unassigned nodes are scheduled to run on the machine that the source or sink is scheduled for, “depending on if the node is before or after the minimum cut edge”.
Applying and evaluating POSH
POSH was evaluted on the time it takes to execute a number of applications. This paper review focuses on two specific applications: a distributed log analyis and a git workflow for Chromium. The experimental configuration involved using either a cloud-to-cloud setup (where client and machines are in the cloud) or a university-to-cloud setup (where the POSH client is located at Stanford). The cloud-to-cloud setup has significantly higher bandwidth and significantly lower RTT, and helps to demonstrate that POSH is capable of achieving speedups even with a more powerful network.
The baseline performance measurement in these experiments comes from exercising each application using NFS instead of POSH. The NFS-only setup mimics a situation where the applications would perform IO-heavy workloads, but be unable to parallelize them (nor be able to limit network overhead).
For the distributed log analysis (which involves searching for an IP address in a 15GB log dump), POSH sees a speedup from parallelizing across multiple NFS mounts in both experimental setups, although POSH sees a more dramatic speedup in the university-to-cloud setup than in the cloud-to-cloud setup (12.7x improvement in the former versus 2x improvement in the latter).
For the git workflow experiment, git operations (like git status, git add, and git commit) were exercised by reverting, then recommitting 20 commits from the (quite large) Chromium open source project - git commands on such a large project make many metadata calls (to determine whether a file has changed, for example). POSH shines in this experiment, achieving a 10-15x latency improvement in the cloud-to-cloud environment. This application seems incredibly useful - in the past, I’ve read about Facebook’s efforts to scale Mercurial.
Conclusion
POSH is a novel system for parallelizing IO-intensive shell scripts by performing work “close to the data”. The paper is one component of an exciting thread of research that could lead to significant improvements to user experience - given that technical folks from many different backgrounds use the shell every day, these improvements would be high impact.
Next week I will move on from this series and into papers from Usenix ATC and OSDI. As always, feel free to reach out on Twitter with feedback or suggestions about papers to read. Until next time!