micahlerner.com
PaSh: Light-touch Data-Parallel Shell Processing
Published July 31, 2021
Found something wrong? Submit a pull request!
This week’s paper review is the third in a series on “The Future of the Shell”Here are links to Part 1 and Part 2 . These weekly paper reviews can be delivered weekly to your inbox, and based on feedback last week I added an Atom feed to the site. Over the next few weeks I will be reading papers from Usenix ATC and OSDI - as always, feel free to reach out on Twitter with feedback or suggestions about papers to read!
PaSh: Light-touch Data-Parallel Shell Processing
This week’s paper discusses PaSh, a system designed to automatically parallelize shell scripts. It accomplishes this goal by transforming a script into a graph of computation, then reworking the graph to enhance parallelism. To ensure that this transformation process is correct, PaSh analyzes a command as annotated with a unique configuration language - this configuration explicitly defines a command’s inputs, outputs, and parallelizability. The final step in applying PaSh transforms the intermediate graph of computation back into a shell script, although the rewritten version of the shell script will (hopefully) be able to take advantage of greater parallelism.
On its own, PaSh can provide dramatic speedups to shell scripts (applying the system to common Unix one-liners accelerates them by up to 60x!), and it would certainly be interesting to see it coupled with other recent innovations in the shell (as discussed in other paper reviews in this series).
What are the paper’s contributions?
The paper makes three main contributions:
- A study of shell commands and their parallelizability. The outcome of this study are categorizations of shell commands based on their behavior when attempting to parallelize them, and an annotation language used to describe this behavior.
- A dataflow modelThere are many interesting papers that implement a dataflow model, although a foundational one is Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks useful for representing a shell script. A given script’s model is informed by the commands in it and the behavior of those commands (each command’s behavior is described with the custom annotation language mentioned above). The intermediate dataflow model is reworked to enhance parallelism, and is finally transformed back into a shell script (which then executes a more parallel version of the original computation).
- A runtime capable of executing the output shell script, including potentially custom steps that the PaSh system introduces into the script to facilitate parallelization.
Shell commands and their parallelizability
PaSh seeks to parallelize shell commands, so the author’s first focus on enumerating the behaviors of shell commands through this lens. The result is four categories of commands:
- Stateless commands, as the name suggests, don’t maintain state and are analagous to a “map” function. An example of stateless commands are
grep,tr, orbasename. - Parallelizable pure commands produce the “same outputs for same inputs — but maintain internal state across their entire pass”. An example is
sort(which should produce the same sorted output for the same input, but needs to keep track of all elements) orwc(which should produce the same count for a given input, but needs to maintain a counter). - Non-parallelizable pure commands are purely functional (as above, same outputs for same inputs), but “cannot be parallelized within a single data stream”. An example command is
sha1sum, which hashes input data - if the stream of data passed to the command is evaluated in a different order, a different output will be generated. This is contrast to a parallelizable pure command likesort- no matter which order you pass in unsorted data, the same output will be produced, making the computation it performs parallelizable. - Side-effectful commands alter the state of the system, “for example, updating environment variables, interacting with the filesystem, and accessing the network.”
This categorization system is applied to commands in POSIX and GNU Coreutils.
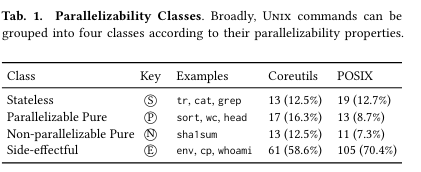
While the vast majority of commands (in the non-parallizable pure and side-effectful categories) can not be parallelized without significant complication, a significant portion of commands can be relatively-easily parallelized (stateless or parallelizable pure categories).
Shell command annotation
To describe the parallelizability class of a given command and argument, the paper’s authors built an extensibility framework. This framework contains two components: an annotation language and custom aggregators which collect the output of commands executing in parallel and stream output to the next command in the script.
The annotation languageThe annotation language is defined in JSON which seems helpful for initial development - it would be interesting to see the language ported to a more constrained format, like protobuf/textproto. is used to produce annotations that indicate inputs, outputs, and parallelization class on a per-command basisThe entirety of PaSh, including annotations, are open source on GitHub - the docs include a useful reference for annotating commands. . An example for the default behavior of the cut command is below:
{ "command": "cut", { "predicate": "default", "class": "stateless", "inputs": ["stdin"], "outputs": ["stdout"] }
One can also define behavior for specific command and argument combinations. For example, providing (or omitting) a specific argument might change the parallelizability class or inputs/outputs for a command - an example of this is cut with the -z operand (cut reads from stdin if the -z operand is not provided):
{ "predicate": {"operator": "exists", "operands": [ "-z" ]}, "class": "n-pure", "inputs": [ "args[:]" ], "outputs": [ "stdout" ] }
The second component of the extensibility framework are custom aggregators that coalesce the results of parallelized operations into a result stream - an example aggregator takes in two streams of wc results and produces an element in an output stream. The PaSh open source project includes a more complete set of examples that can aggregate the results of other parallelized commands, like uniq.

The implementation of PaSh relies on the annotation language and custom aggregators described above in order to transform a shell script into an intermediate state where the script’s commands are represented with a dataflow model - this transformation is covered in the next section.
Transforming a script
There are multiple steps involved in transforming a script to a more-parallel form. First, PaSh parses it, then transforms the parsed script into an intermediate state called a dataflow graph (DFG) model. The annotation language facilitates this transformation by providing hints to the system about each step’s inputs, outputs, and behavior when parallelized. The intermediate dataflow model can be reconfigured to produce a more parallel of the script’s associated commands. Lastly, the resulting graph is transformed back into a shell script.
PaSh implements this transformation process end-to-end using three components: a frontend, the dataflow model, and the backend.
The frontend first parses the provided script into an Abstract Syntax Tree (AST). From there, it “performs a depth-first search” on the AST of the shell script, building dataflow regions as it goes along - a dataflow region corresponds to a section of the script that can be parallelized without hitting a “barrier” that enforces sequential executionIt’s worth noting that PaSh also is very conservative when it comes to building dataflow regions that it might try to parallelize later - if an annotation for a command is not defined or it is possible that the parallelizability class of an expression could be altered (for example, if the command relies on an environment variable), then PaSh will not parallelize it. . Examples of barriers are &&, ||, and ;. The resulting dataflow model is essentially a graph where the nodes are commands and edges indicate command inputs or outputs.
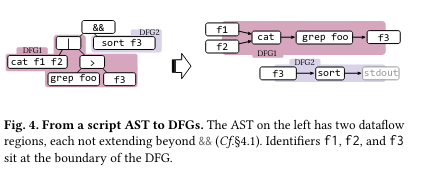
Once the dataflow graphs (DFG) for a script are produced, they can be reworked to take advantage of user-configured parallelism called width. The paper lays out the formal basis for this transformation - as an example, stateless and parallelizable pure commands can be reconfigured to enhance parallelism while still producing the same result (the paper presents the idea that for these two parallelizability classes, the result of reordering nodes is the same).
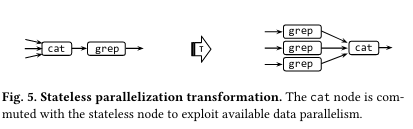
The paper also mentions other useful transformations of the graph - one in particular, adding a relay node between two nodes, is useful for enhancing performance (as described in the next section).
After all transformations are performed on the graph, the Backend transforms the graph back into an executable shell script.
Runtime
The output script generated by the application of PaSh can be difficult to execute for several reasons outlined by the paper, although this paper review doesn’t include a complete description of the runtime challengesThe paper does a better job of noting them than I could and I highly recommend digging in! .
One particularly important detail of the runtime is an approach to overcoming the shell’s “unusual laziness” - the paper notes that the “shell’s evaluation strategy is unusually lazy, in that most commands and shell constructs consume their inputs only when they are ready to process more.” To ensure high resource utilization, PaSh inserts “relay nodes”, which “consume input eagerly while attempting to push data to the output stream, forcing upstream nodes to produce output when possible while also preserving task-based parallelism”. For a number of reasons, other approaches to solving the “eagerness” problem (like not addressing it or using files) result in less performant or even possibly incorrect implementations - this comes into play in the evaluation section of the paper.
Evaluation
The evaluation section of the PaSh paper includes a number of applications, but I choose to focus on three applications that stuck out to me: Common Unix One-liners, NOAA weather analysis, and Wikipedia web indexing.
Applying PaSh to the set of common UNIX one-liners exercises a variety of different scripts that use stateless, parallizable pure, and non-parallelizable pure in different configurations and numbers, speeding up scripts by up to 60x. This set of tests also demonstrates that implementation details like eager evaluating (outlined in the Runtime section above) make a differenceThis result is shown by benchmarking against versions of PaSh without the implementation or with a different, blocking implementation. .
The next example I chose applies PaSh to an example data pipeline that analyzes NOAA weather data. PaSh is applied to the entire pipeline and achieves significant speedups - this example is particularly useful at demonstrating that the system can help to parallelize non-compute bound pipelines (the NOAA example downloads a signficant amount of data over the network). In particular, downloading large amounts of data over the network seems to closely relate to ideas discussed in the first paper in this series, which mentions avoding redundant computation - parallelizing network requests automatically while ensuring that none are repeated unnecessarily (if the script was rerun or slightly changed) would be amazing!
The last example I choose to include in this evaluation section is of Wikipedia web indexing - PaSh is able to achieve a 12X speedup when extracting text from a large body of Wikipedia’s HTML. This example uses scripts written in Python and Javascript, showcasing PaSh’s ability to speedup a pipeline utilizing commands from many different langauges and why the shell is still such a useful tool.
Conclusion
PaSh presents an intriguing system for automatically transforming shell scripts into more-parallel versions of themselves. I was particularly interested in how PaSh accomplishes its goals by leveraging annotations of shell commands and arguments - it would be interesting to see an open source community sprout up around maintaining or generating these annotationsI felt some similarity to Mac’s Homebrew, where users define recipes for downloading different open source projects. . PaSh’s use of a dataflow-based architecture also demonstrates how powerful the paradigm is. Last but not least, I’m looking forward to seeing how a system like PaSh could fit in with other related innovations in the shell (like next week’s paper on POSH)!
As always, if you have feedback feel free to reach on Twitter. Until next time!