micahlerner.com
Noria: dynamic, partially-stateful data-flow for high-performance web applications
Published March 28, 2021
Found something wrong? Submit a pull request!
Discussion on Hacker News
Noria: dynamic, partially-stateful data-flow for high-performance web applications Gjengset, Schwarzkopf, et al. OSDI 2018
I started reading this paper after finding the work of Jon Gjengset - he has great streams about Rust (in particular, I have been enjoying Crust of Rust, where he goes over intermediate Rust topics).
What is Noria?
The Noria paper outlines a system that could replace a traditional two-tier architecture used in web applications to serve high read request volume.
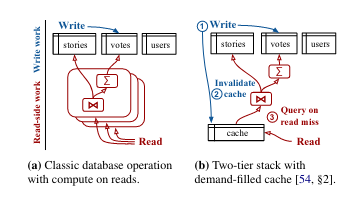
This two-tier architecture uses a backing database and a cache (like Memcached, Redis, etc.) to limit the number of requests that hit the backing database. Putting a cache in front of the database to serve read requests raises several important questions:
- How is the cache invalidated when a write is made to the backing datastore? Presumably, the cache should be invalidated when a write happens, but how does one make sure that cache invalidations don’t trigger all at once (an event that could overload your infrastructure if all reads suddenly hit the backing database, causing it to fall over).
- How is the cache set up to handle changes in user patterns? For example, say that the cache only has a subset of popular records, but traffic suddenly shifts to a different set of records (imagine that a different set of videos go viral).
Another challenge with a traditional two-tier architecuture is being able to handle aggregations well - for example, say that you wanted to maintain the top-k posts on a site, or the min/max of a set of values. These types of aggregations are supported by current stream processing systems, with a caveat - the stream processing systems often perform aggregations over a window of time to limit the data that needs to be retained. Once a record goes out of the window used by the aggregation, the record is dropped, limiting the number of records that need to be kept around.
Data Flow
The Noria paper proposes a new database (and includes an implementation), that aims to support “read-heavy applications that tolerate eventual consistency”.
In order to achieve the goal of getting rid of an external cache, Noria effectively caches results for common queries inside the database. 
To supporting caching inside the database, two structures are used:
- Base tables (a persistent store of the database state)
- Derived views (“the data that an application might choose to cache”)
Derived views (similar to materialized views in current database implementations) are populated using data from base tables. Operations on the database like writes, updates, and deletes flow through a graph that contains state, updating the cache - the concept of changes propagating through graph is called data flowThe paper points to past research on data-flow systems, like Naiad: A Timely Dataflow System. .
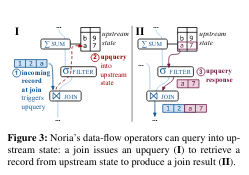
The nodes in the data-flow graph are views of the database used by readers, or cached intermediate results used to build those views. The edges can represent relationships between intermediate results - for example, if a derived view relies on two tables, there would be edges between the intermediate results and the output derived view. Interestingly, related derived views (views that use the same underlying tables) can reuse the graph of state (more on reuse of the state in the graph later).
If a read query occurs, but the data required to answer the query is not cached, Noria can choose to fetch the data using an upquery.
The idea of representing derived views as a graph of intermediate results comes in handy when new user patterns emerge or new derived tables are added. In this situation, Noria will transition to a new graph of data-flow:
Noria first plans the transition, reusing operators and state of existing expressions where possible (§5.1). It then incrementally applies these changes to the data-flow, taking care to maintain its correctness invariants (§5.2). Once both steps complete, the application can use new tables and queries.
The paper argues that this transitioning pattern is fundamentally different than existing data-flow systems, which can not perform updates to the graph on the fly (or without a restart).
To ensure that the size of the data in the derived views does not have unbounded growth, Noria implements partially stateful data-flow - if the footprint of the derived views grows to be too large, the system evicts data intelligently (a user of the system need to ensure enough resources are provided so that there is not significant churn in the data kept in cache). The paper mentions that partial materialization is not entirely new, but that applying the idea to “data-flow” systems is. .
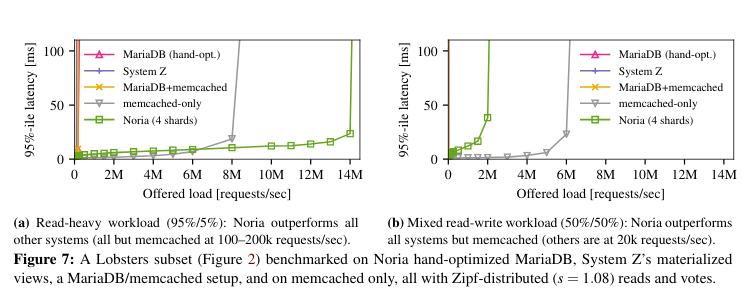
Performance evaluation
The paper includes an evaluation section, where the system is benchmarked against a set of other databases. The benchmark contains a simulation of read traffic to lobste.rs, and in this comparison Noria does quite well, scaling to many millions of requests before hitting a wall.