micahlerner.com
A Cloud-Scale Characterization of Remote Procedure Calls
Published March 03, 2024
Found something wrong? Submit a pull request!
This is one of several papers I’ll be reading from 2023’s Symposium on Operating Systems Principles (SOSP). If you’d like to receive regular updates as soon as they’re published, check out my newsletter or follow me on the site formerly known as Twitter. Enjoy!
“A Cloud-Scale Characterization of Remote Procedure Calls”
What is the research and why does it matter?
This paper is slightly different from others I’ve written about recently - rather than a novel system design, it contains a characterization of a production system, with the goals of sharing data with the research community.
Specifically, the research dives deep on contributors to RPC latency and performance in Google’s hyper-scale systems, including Google Search, Google Maps, Gmail, and YouTube. In some areas, this data matches existing research and points towards the benefits that further investment could provide. Other datapoints don’t match up with previous thinking, indicating the possibility of new research threads or focused interest in existing ideas!
Characteristics of RPCs at Hyperscale
The paper focuses on production traffic that uses Google’s internal RPC library, Stubby. This traffic powers first-party services and their accesses to other internal systems and databases. The authors use data from Monarch (the subject of a previous paper review!), Dapper (a library for distributed tracing) and Google Wide Profiling (which continuously gathers performance data from services deployed in Google datacenters).
An analysis of these datasets exposes five insights about Google-internal RPCs.
- RPC performance is growing over time
- Some RPCs take microseconds, while many take milliseconds
- The RPC call graph mostly involves fan out, rather than deep call trees.
- Many RPCs response/request sizes are small, but some are quite large.
- A significant portion of RPC traffic is associated with access to storage.
First, the authors measure RPC performance improvement over time using “RPCs per CPU cycle”. This effect is because of factors like optimizing the RPC library (which reduces the cost of sending RPCs, allowing more RPCs to be sent with fewer resources). In turn, these performance improvements are posing a greater load on other resources, like the network.
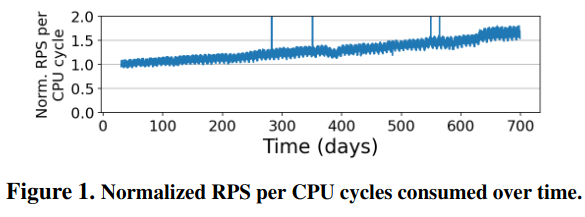
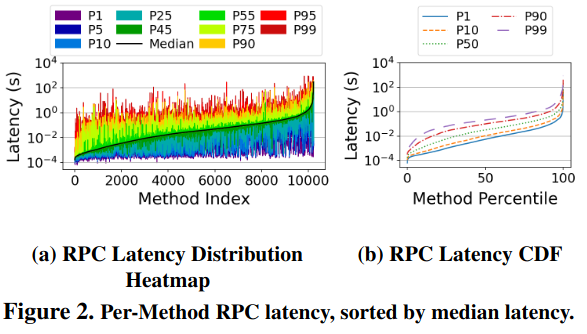
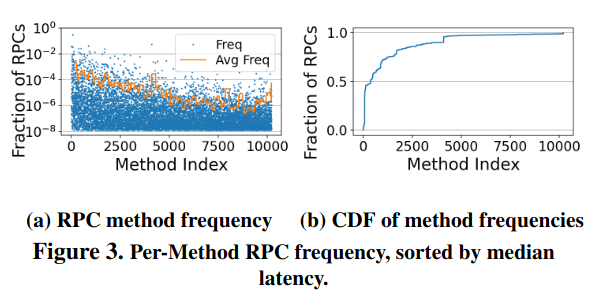
Second, “not all RPCs are the same” in terms of their latency - some take microseconds, while others take milliseconds. Furthermore, a small number of RPC calls make up a majority of traffic, meaning that optimizing them could have outsized impact. Other calls are infrequent, but take up significant computation - “the slowest 1000 RPC methods account for only 1.1% of all calls, but they take 89% of the total RPC time.” The authors share data on per-method RPC latency and frequency to demonstrate these trends.
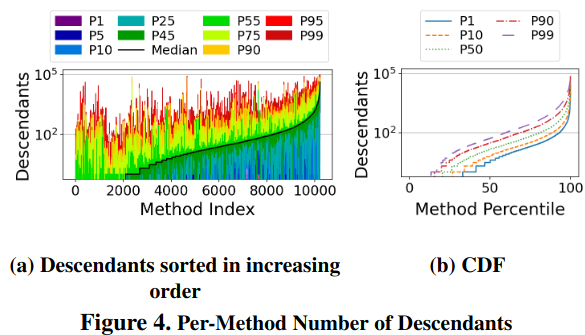
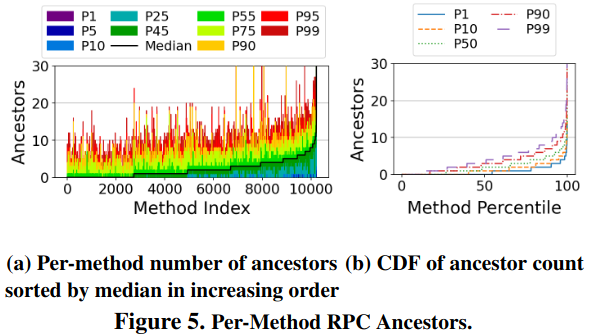
Third, “RPCs are Wider than Deep” - RPCs have significant fan out into other systems Google infrastructure, but don’t normally result in many services calling each other far down into the stack. The authors note this behavior matches with existing studies from Alibaba and Meta. The paper visualizes this insight with CDFs of “descendants” and “ancestors” in the RPC call graph - “looking at the number of descendants shows the scale of distributed computation performed by an RPC, and the number of ancestors provides insights into how the properties of RPCs change as they get deeper into the call graph of a root RPC.”
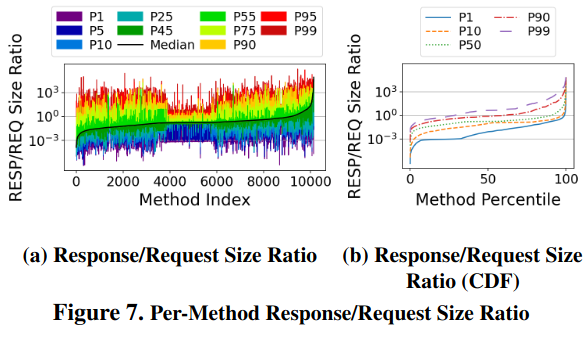
Fourth, there is an “elephant and mice distribution” of RPC sizes - “most RPCs are small with the smallest a single cache line (64 B)”. Others are significantly larger - “P99 requests and responses are 196 KB and 563 KB”. This data shows that projects like hardware accelerators would be able to optimize significant parts of the RPC workload, but would not be able to handle others (specifically, the authors reference “Zerializer: Towards zero-copy serialization”). The authors present this data using CDFs that show percentiles of request sizes and the ratio between response/request.
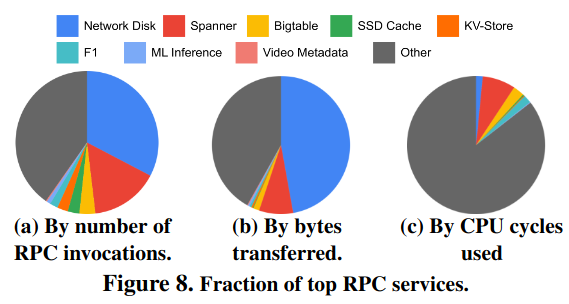
Lastly, a significant portion of RPC traffic is associated with accesses to storage - “these findings motivate application-specific optimizations, especially on storage systems, as storage is by far the largest distributed application in the fleet.”
RPC Latency
The papers dive into the sources of RPC latency in a client-server interaction - at a high level, the components boil down to client/server send and receive queues, server processing logic, the networking stack, and networking infrastructure.
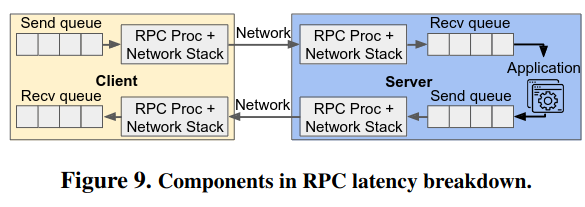
To describe the cost of sending an RPC to an external service, minus server processing time, the paper uses the term RPC latency tax - the paper focuses on this because while “application-processing time dominates…[the] RPC tax can be significant.” This tax applies no matter how good a server gets at returning a response - for many RPC calls this tax makes up the bulk of their time.
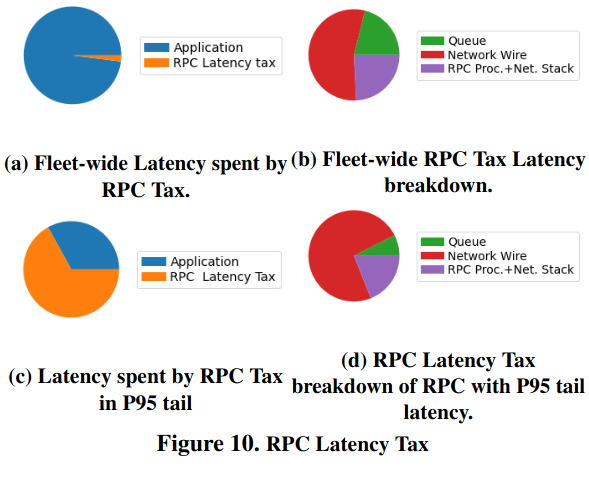
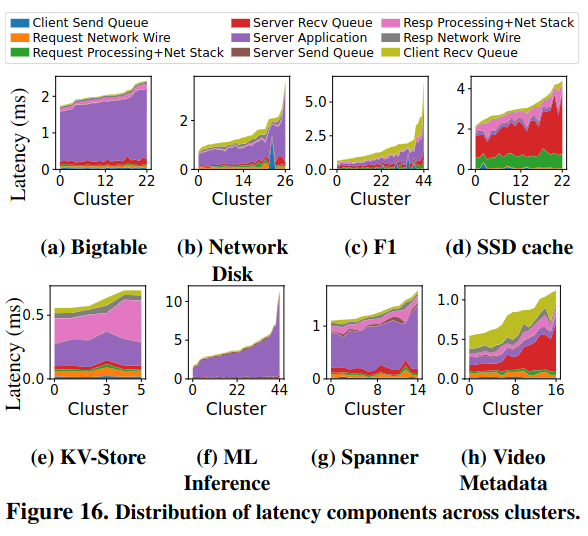
This tax also varies across different types of services. For example, RPCs to an SSD cache would benefit the most from reducing the time an RPC spends in the server send queue, while RPC calls to the F1 database would benefit the most from reducing time in the client recv queue.
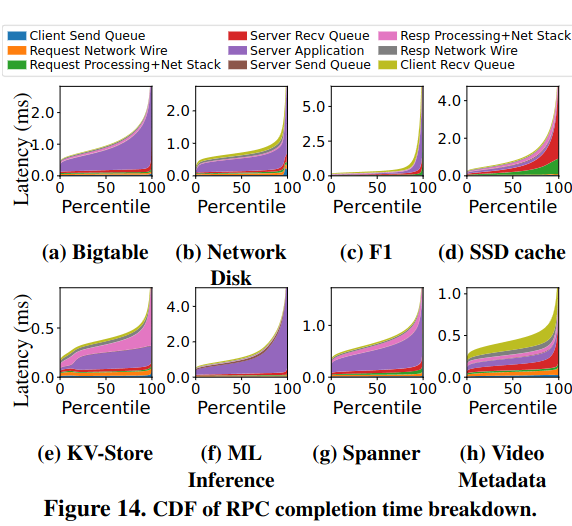
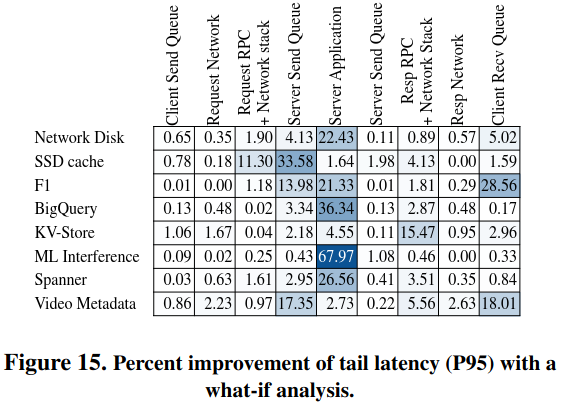
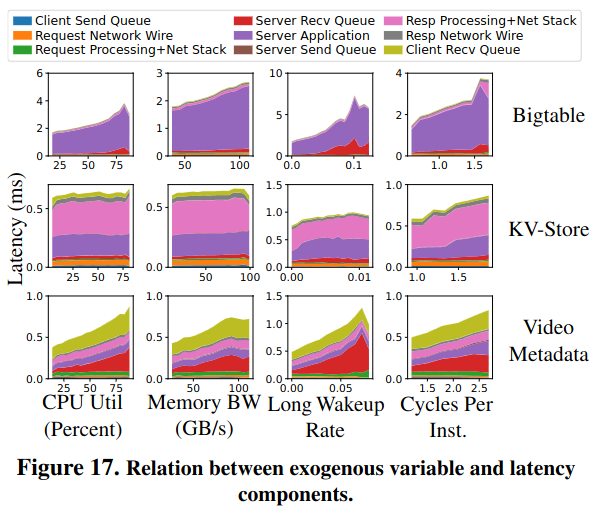
The RPC latency tax also varies across clusters - in other words, a service can respond faster to RPCs when it is deployed in cluster A instead of cluster B. This happens because of characteristics of the cluster, like CPU utilization and memory bandwidth - the paper calls these exogenous variables.
Each application category reacts differently towards these exogenous variables. Bigtable is a server-processing-heavy workload, and its performance is highly dependent on CPU utilization, memory bandwidth, wake-up time, and cycles per instruction. Video Metadata is queuing heavy, which follows a similar trend.
Resource Utilization of RPCs
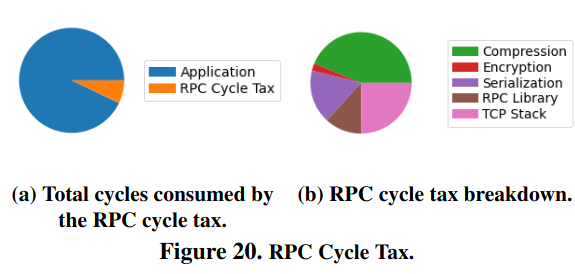
There is also another cost for RPCs, the CPU cost, which the paper calls the cycle tax. Multiple components of the RPC flow contribute, however compression dominates.
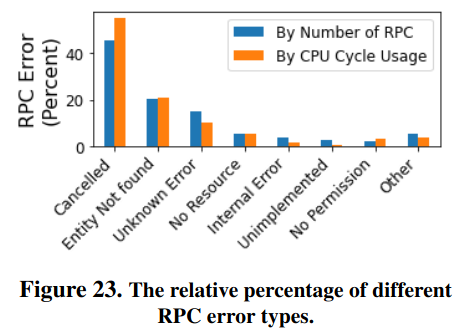
The paper also evalutes the CPU cycle usage from unsuccessful RPCs - the single largest contributor are cancelled requests (likely sent because of request hedging). Other types of potentially avoidable errors consume a suprising amount of CPU resources (e.g. “entity not found” response codes).
Conclusion
I enjoyed this paper because of its focus on providing data on the potential impact of several opens areas of academic research - without this thorough characterization, it would be difficult to understand their expected value.
While many proposals are focused on Attack of the killer microseconds, these improvements aren’t required for many RPCs. The research also highlights challenges with solutions to known problems like tail latency - approaches like request hedging have their own downsides in wasted CPU resources. Rather than trying to globally optimize RPCs, focusing on specific operations is likely to the highest impact - “the 10 most popular RPC methods account for 58% of all calls and the top-100 account for 91% of all calls.” On the hardware front, accelerators (some of which have already been discussed in research) could yield significant benefits - for example, previous papers evaluated a hardware accelerator for protocol buffers.
With the insights from this paper, I’m looking forward to seeing how the authors follow up with future improvements and to see how other groups respond in adjusting the direction of their research (or not).
Lastly, the research cited a number of other industry studies about microservices architectures and their costs that I’m hoping to dive into with future paper reviews - specifically ServiceRouter.