micahlerner.com
Efficient Memory Management for Large Language Model Serving with PagedAttention
Published January 11, 2024
Found something wrong? Submit a pull request!
Efficient Memory Management for Large Language Model Serving with PagedAttention
What is the research?
Large language models (like OpenAI’s ChatGPT, Google’s Bard, Meta’s Llama, and Mistral’s Mixtral) take in a user prompt and respond with generated text (note: for the purposes of this paper, the authors don’t include multi-modal response). Based on public reports, supporting this functionality is expensive, and given the relatively new nature of LLMs deployed at scale, there are opportunities for improving performance.
To that end, this paper focuses on increasing the queries per second (a.k.a throughput) large language models (LLMs) can serve through two innovations, PagedAttention, and vLLM, discussed in detail later in this paper review. Improving throughput can significantly decrease the cost of large language model serving by responding to more requests with the same number of GPU resources. The evaluations from the paper show that, “vLLM improves the LLM serving throughput by 2-4× compared to the state-of-the-art systems…without affecting the model accuracy at all.”
Based on the observation that large language model serving is memory bound, the authors identify several areas of improvement for GPU memory allocation, then design a system that addresses these shortcomings. One of the foremost problems they address is static allocation of memory. Existing LLM serving systems (or at least publically released ones) set aside fixed, contiguous memory to store the data needed to generate a response. If the response to the user is shorter than this fixed size, the resources are inaccessible to use for serving other requests until the original request is complete. Requiring contiguous memory blocks adds additional resource waste by “stranding” memory between the contiguously allocated areas of memory, causing it become unusable for serving other requests.
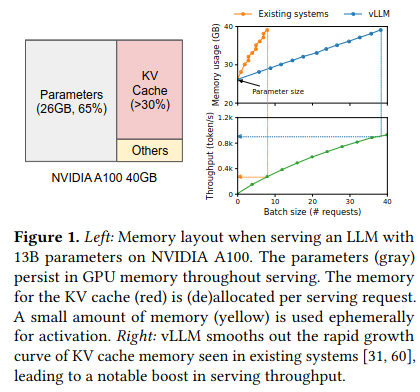
Borrowing ideas a page from virtual memory, the authors propose a solution, PagedAttention, that can dynamically grow the memory used in LLM serving (in addition to incorporating other optimizations). The paper also describes how PagedAttention is implemented in a new GPU serving library via the open source vLLM project.
How does the system work?
Large language models take in a prompt from a user, then generate a text response. The paper focuses specifically on improving the performance of serving for transformers, a technology used by predominantly all implementations of large language models to generate the next word in a sequence - for more background, I recommend The Illustrated Transformer and Understand how transformers work by demystifying all the math behind them.
Generating these sequences requires information on the users prompt, and about previous tokens in the response - this knowledge takes the form of vectors stored in memory in a data structure the authors call the Key Value Cache (aka KV cache). Because the limiting step in the execution of an LLM depends on reading and writing data to/from memory, an LLM process is “memory bound” - as a result, improving memory utilization (specifically, of the KV Cache) can increase performance of the system.
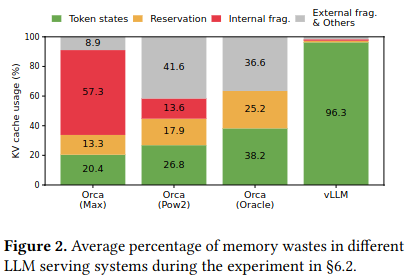
The authors identify three main types of waste in the KV Cache:
reserved slots for future tokens, internal fragmentation due to over-provisioning for potential maximum sequence lengths, and external fragmentation from the memory allocator.
PagedAttention
One of the paper’s key insights is that allowing a model to dynamically scale up its usage of non-contiguous memory can drastically improve memory utilization. The authors propose PagedAttention, which introduces the idea of logical and physical memory blocks for storing data in the KV Cache. This distinction is similar to virtual memory which provides the abstraction of contiguous RAM to a program, even though the data is physically stored in separate areas of RAM.
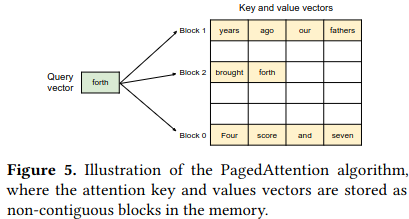
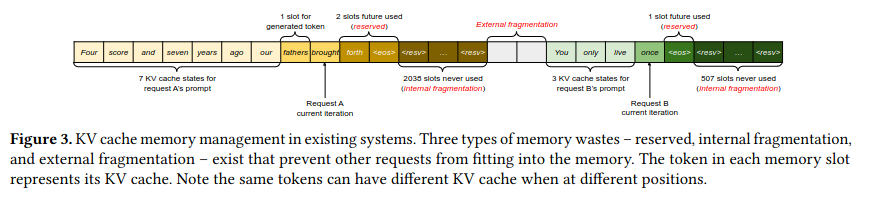
Blocks contain entries for more than one token, and blocks are allocated on demand based on how the LLM responds to a user query - for example, the prompt “Four score and seven years ago our fathers brought forth” contains ten tokens, causing the allocation of three blocks each with the space for four entries (the last block allocated because of the prompt is partially filled). Gradually allocating blocks primarily addresses internal fragmentation and reserved memory.
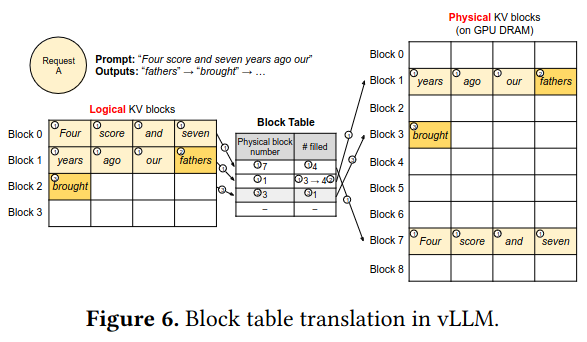
As the large language model generates tokens, it references data on previous tokens using a block table storing the mapping between logical blocks for a query and physical GPU DRAM. Critically, this approach allows for the GPU to serve multiple requests at the same time while using non-contiguous memory, addressing concerns like external fragmentation.
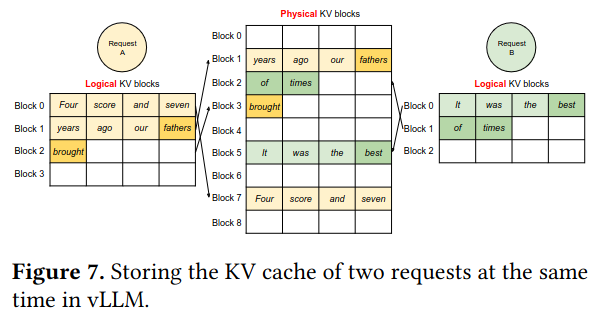
The paper also describes how PagedAttention approach is able to reduce memory usage in three other large language model serving request patterns - parallel sampling, beam search, and shared prefix prompting.
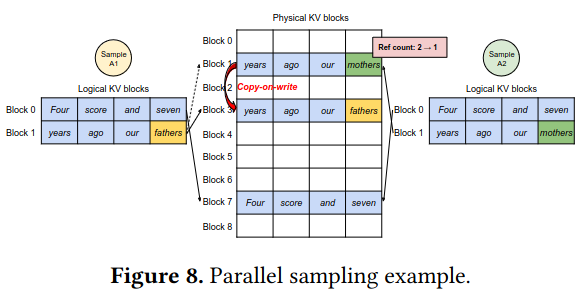
Parallel sampling involves generating multiple results for a single prompt - this can occur by having the LLM choose a different token, leading to a different branch of response. The implementation follows a “copy-on-write” pattern that reuse the same data in GPU memory until the branch in output occurs (at which point, the block with the difference is copied to a new location in memory, and execution completes independently for the different branches).
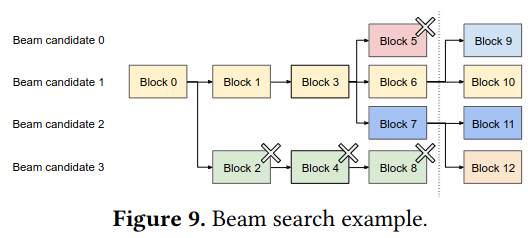
The paper also describes PagedAttention in the context of beam search, an algorithm for generating possible next states and choosing a “top-K” subset to continue with - the paper cites Sequence to Sequence Learning with Neural Networks when referencing beam search, but I think this explanation gets the gist across better. A beam search implemented with PagedAttention can reuse blocks across multiple search paths, meaning that the process has less memory overhead.
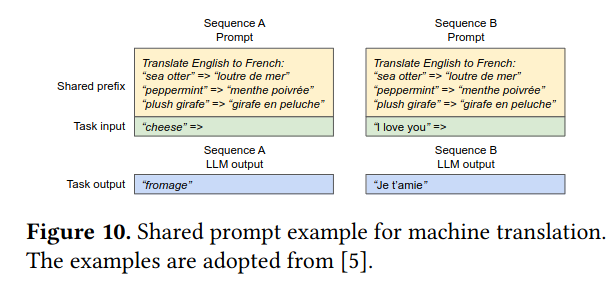
Lastly, the paper discusses PagedAttention’s impact on prompts with a shared prefix - in many situations, a user of an LLM will provide a separate “system” prompt that applies, no matter the details of the task (this is also discussed in OpenAI’s documentation on prompt engineering). One example system prompt is, “you are a helpful agent that only speaks JSON”. PagedAttention allows the blocks allocated for this part of the prompt to be reused across multiple tasks, reducing memory usage.
vLLM
To deploy PagedAttention in a distributed environment, the paper proposes the vLLM system, containing a scheduler (which chooses which work to run where), the KV Cache Manager, Workers (computers containing GPU hardware), and Block Allocators. I elide the details of this section given that vLLM is an open source project, and the details of the infrastructure are likely to change.
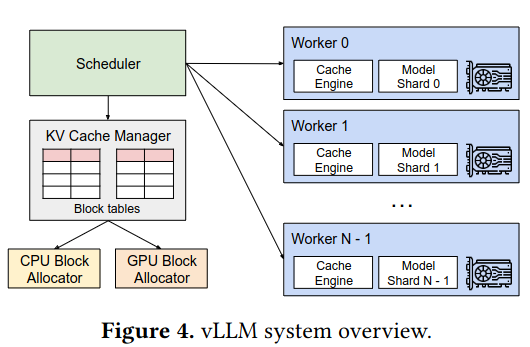
That said, there were a few interesting design choices that stuck out to me:
- vLLM adopts patterns from Megatron-LM, which details how to run transformers at scale across many GPUs while minimizing communication.
- vLLM implements the OpenAI API interface, simplifying developer adoption.
- vLLM supports higher-level abstractions (via
fork,append, andfreecommands) used to implement approaches like beam search, parallel sampling, and shared prefix - luckily the code is open source which allows for a deeper dive!
How is the research evaluated?
The paper compares performance of models served with vLLM against other serving systems (e.g. a custom implementation of Orca, an LLM-serving system described in research from OSDI 2022) emulating workloads sourced based on open source datasets (ShareGPT and Stanford Alpaca).
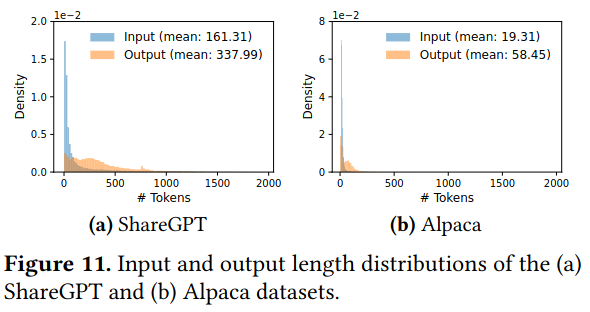
The paper compares three different types of tasks - basic sampling (e.g. normal LLM usage), search-based techniques like parallel sampling and beam search, and chatbot-like uses of LLMs (which have longer prompts, along with back and forth between the user and the LLM).
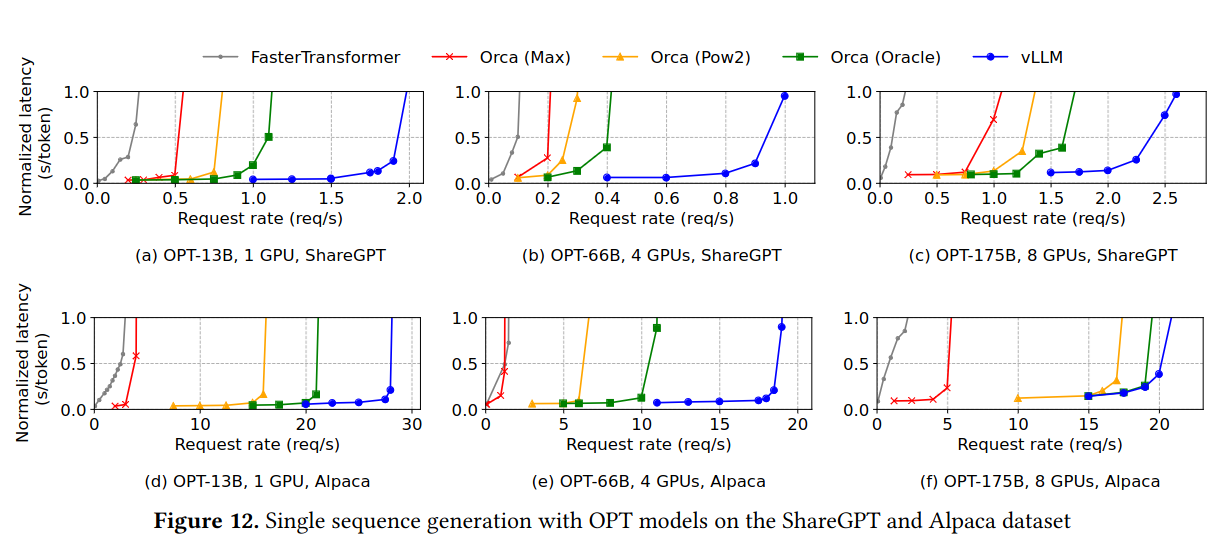
For basic sampling, parallel sampling, beam search, and chatbot-like workloads, vLLM is able to achieve significantly higher request rates.
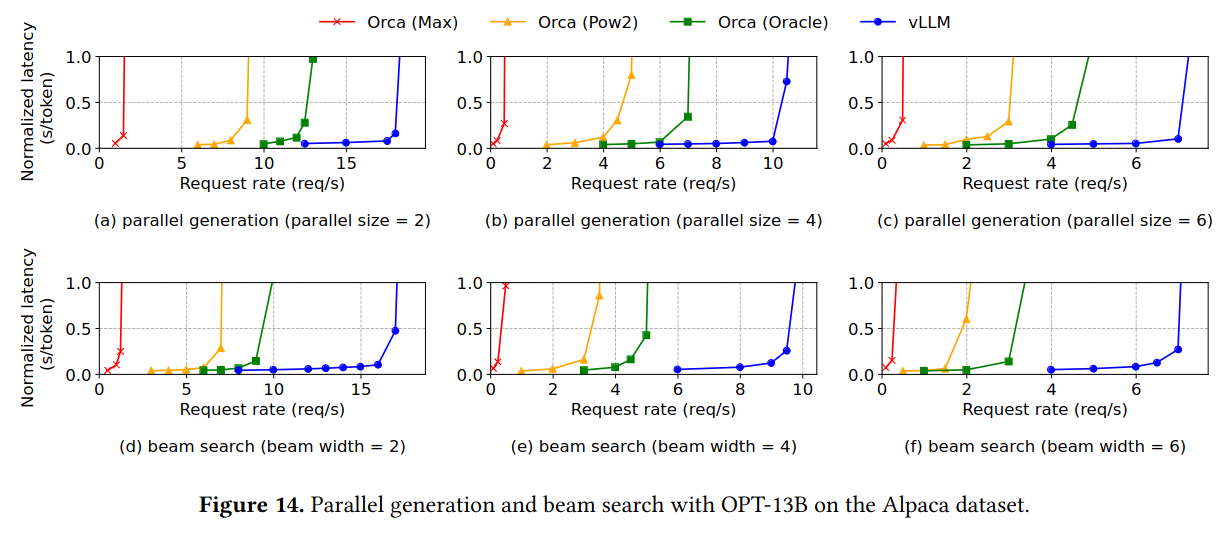
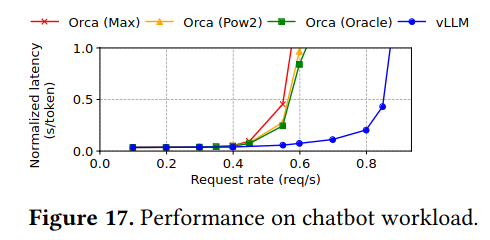
Additionally, vLLM and PagedAttention are able to save significant amounts of memory on tasks where it is possible to re-use blocks (e.g. parallel sampling and beam search) - these graphs show average amount of memory saving as a percent, but it would be interesting to know in absolute terms.

Conclusion
PagedAttention and vLLM are at the cutting edge of systems research and its application to AI - something that is becoming more of a topic in research and in practice (e.g. Charles Frye’s post) now that LLMs are beginning to operate at scale. I’m looking forward to following along on the progress of the vLLM open source project, and from digging into the project, I discovered it is compatible with SkyPilot (an open source project for deploying infrastructure cross-cloud, discussed in research from NSDI 2023). As I tinker on LLM-based side-projects, I’m looking forward to experimenting with and learning from these promising new tools.