micahlerner.com
TelaMalloc: Efficient On-Chip Memory Allocation for Production Machine Learning Accelerators
Published June 06, 2023
Found something wrong? Submit a pull request!
Discussion on Hacker News
This is one in a series of papers I’m reading from ASPLOS. These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
TelaMalloc: Efficient On-Chip Memory Allocation for Production Machine Learning Accelerators
A common pattern for integrating machine learning models with applications is deploying them to user devices, where the models run on local hardwareSee Apple’s guide to deploying transformers to the Apple Neural Engine. . Running models locally provides performance improvements (by eliminating communication with a cloud), while enabling private computing. Unfortunately, there are also challenges to running models locally because of diversity in hardware capabilities - a program that works well on the highest end modern phone may not perform optimally on previous generation devices.
To effectively run on a user’s device, the software must efficiently use local resources, including memory. The problem of allocating memory has been studied extensivelySee Dynamic Storage Allocation: A Survey and Critical Review. , but ML models pose novel challenges. Specifically, memory allocation for ML models is a 2D bin-packing problemThere is a large amount of research on solving this problem - see Survey on two-dimensional packing and the Wikipedia reference. - unlike programs which grow and shrink their memory usage over time, ML models have strict requirements for memory allocations because certain parts of the model depend on others.
Existing solutionsThe paper cites XLA, TFLite (optimized for mobile devices), and Apache TVM. for ML model memory allocation rely on heuristics or solvers (which can produce a closer to optimal output, but often take longer to run). The Telamalloc paper proposes a solution balancing a combination of heuristics and solvers. As a result, the research is able to tackle the challenge posed by wide variance in hardware capabilities, significantly reducing the time that it takes the model to allocate memory and run.
What are the paper’s contributions?
The paper makes three main contributions:
- Combining a heuristic-based approach to memory allocation with a solver aware of domain-specific knowledge.
- An evaluation of the approach combined approach
- A forward-looking proposal for improving on initial results by taking production data and feeding it back into the system.
How does the system work?
The system takes the problem and turns it into a 2D-optimization problem, where memory blocks are assigned to different ranges of address space over time, based on the flow of the program.
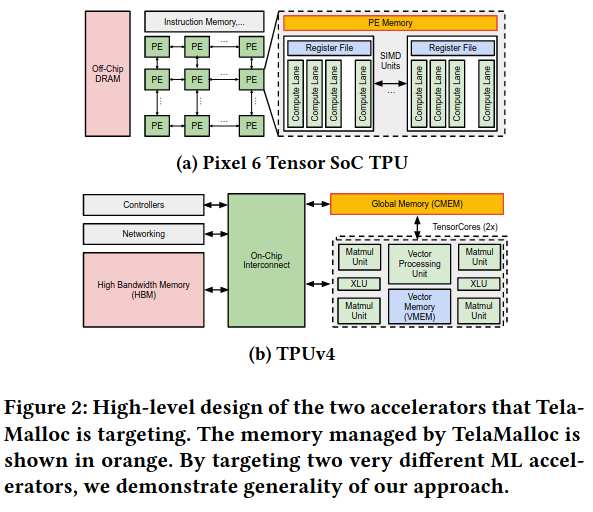
The authors aim the approach at tensor memory allocation both on mobile devices and in Tensor Processing UnitsSee An in-depth look at Google’s first Tensor Processing Unit (TPU). , a custom piece of hardware that is used for machine learning at scale.
It is worth noting how well studied resource allocation is - the paper reviews the standard approach compilers follow to:
1) take a graph representation of the model and perform various graph transformations, 2) divide the graph into smaller units of work (operators), and 3) map these operators to different units of hardware.
The authors call the third component the mapping problem, and note it is fundamentally different than the problem they’re focused on, which they call the memory allocation problem:
the mapping problem is concerned with determining which level of a memory hierarchy to map each buffer to, the memory allocation problem selects buffer locations within addressable scratchpad memories that are shared between multiple buffers with overlapping live ranges.
Notably, the performance of solving the memory allocation problem impacts users. If the compilation of a model takes a long time, an application using a model won’t work. On the other hand, if the problem is solved quickly, but suboptimally, the model may not be able to successfully allocate memory (because it attempts to use too much memory).

Problem Formulation
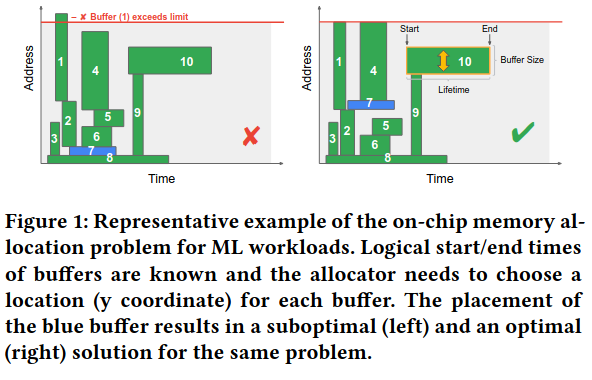
The authors represent the problem by providing a set of buffers with start, end, and size to the allocator, along with an upper limit to memory usage.
The allocator then attempts to produce a solution mapping each buffer to an address, where none of the buffers overlap, and memory usage doesn’t exceed the specified limit.
Memory Allocation Heuristics
The paper describes three main heuristics for assigning buffers to addresses: best-fit, greedy, the approach Telamalloc implements (which is a combination of both).
A best-fit allocator assigns buffers to address space in start time orderThe paper mentions that Tensorflow uses this strategy with its best-fit with coalescing (BFC) allocator. . The paper notes, “This approach works well if memory is abundant but fails if the memory budget is tight” because memory allocations of many blocks in a constrained space will be suboptimal.
The greedy approach (used by TFLite) takes, “the end time into account to pick locations one buffer at time, while ensuring that it does not overlap with any previously allocated buffers.” Again, this approach doesn’t do well when memory is tight because it also produces suboptimal solutions.
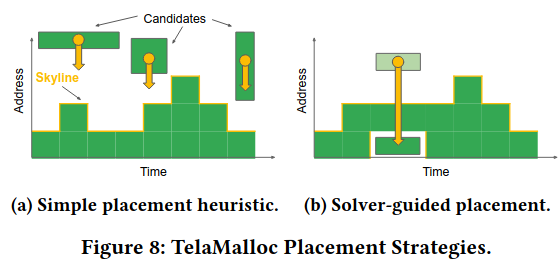
Lastly, there is the heuristic that Telamalloc implements, which takes into account the contention of a point of time (represented by the number of buffers that need to be assigned). Buffers with the highest contention are placed first at the lowest possible address (stored by keeping a “skyline” for each time period)This is reminiscent of the Skyline Problem! . If there are multiple buffers, the heuristic makes a decision based on other factors like the length of time a buffer exists.
Solver-based Approaches
Heuristics for memory allocation have several downsides, including that their performance depends on the specific workload and problem difficulty - “once a heuristic has made a wrong decision that prevents it from solving the problem, it has no way to recover.” To address the shortcomings of heuristic failure, Telamalloc integrates a solver-basedIn particular, the paper relies on integer liner programming (ILP), described in more detail here. approach that represents the problem with several constraints, including all of the buffers taking up space at a given time can not exceed memory and buffers can not overlap.
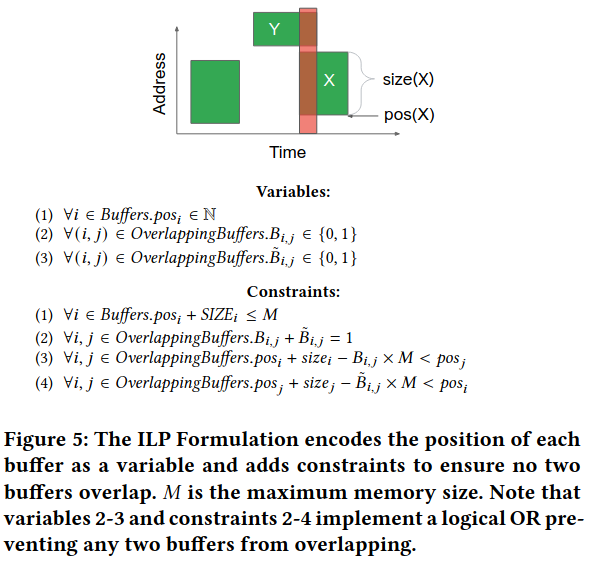
Telamalloc Overview
As mentioned earlier, Telamalloc doesn’t solely rely on heuristics, nor solvers - heuristics get stuck on certain cases, and solvers can take too long. Normally solversThe paper specifically refers to a solver framework from Google, capable of representing a wide variety of constraints and problems. return the whole solution given an input and a set of constraints - instead, the program that guides the solver integrates interactively, reading the state of the solver for a particular buffer and making choices, then responding to feedback.
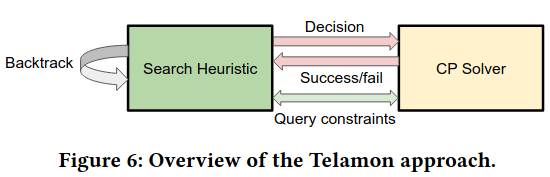
At each step, the Search Heuristic chooses from the remaining unplaced blocksIt chooses blocks based on the following heuristics in order, “(1) The block with the longest lifetime (end-start time). (2) The block with the largest size. (3) The block with the largest area (i.e., size × lifetime).” , and “backtracks” to undo choices if a state it ends up in is invalid. It splits backtracking into “minor” and “major” based on how many steps need to be undone - the former corresponds to a single buffer placement, whereas the latter corresponds to undoing a whole line of choices (because the final state is invalid).
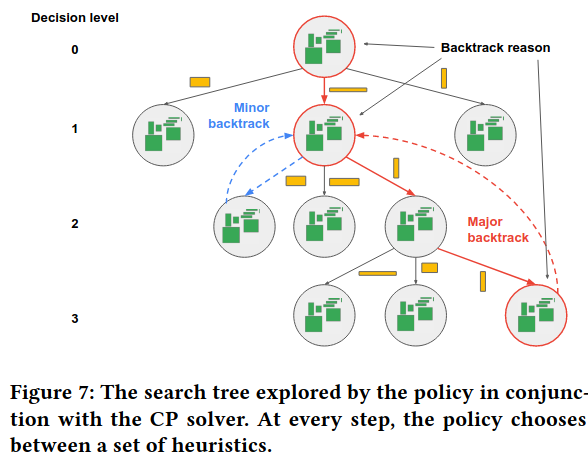
The authors describe a number of optimizations to implement smart backtracking. Several of these focus on avoiding a return to the conditions that caused the initial backtrack. For example, on failure to satisfy constraints, the solver reports which placements occurred, so the search algorithm can unwind them quickly. Another example optimization is explicitly prioritizing buffers whose placement (or inability to place) led to a major backtrack - “this avoids cases where the solver got stuck by ignoring blocks that were important but not among the largest or longest-lived blocks”.
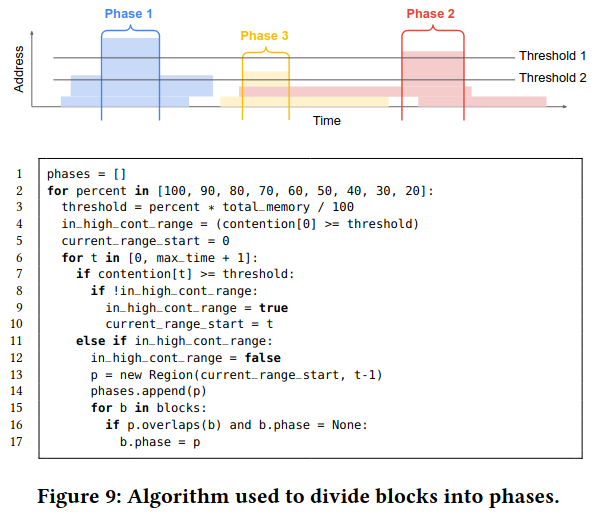
Lastly, Telamalloc groups together buffers that contend with one another into phases, then runs the algorithm over each phase. This approach reduces the complexity of the problem, and allows choosing from a smaller set of candidate buffers when making choices.
How is the research evaluated?
The paper considers two main aspects of Telamalloc: microbenchmarks evaluating the algorithm in isolation, and measurements from compiling models / making memory allocations on a Pixel 6.
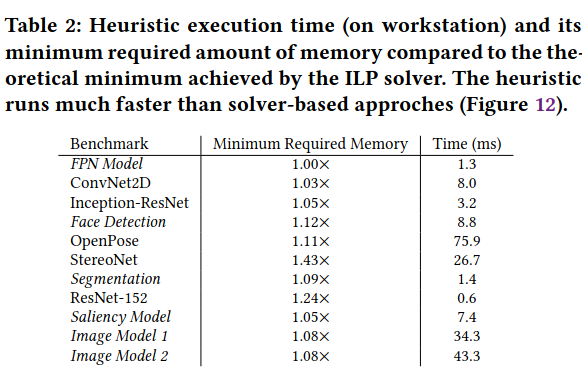
The microbenchmarks consider the time to compute memory placements in the best and worst cases. In normal conditions, Telamalloc completes incredibly quickly (“≈10-100us for common problem sizes”). The worst case is represented by a large number of blocks (one thousand) with full overlap - in this situation, Telamalloc takes around 100000 ms, and each step takes significantly longer due to the strain placed on the solver (which needs to consider how a candidates interacts with many different potential placements).

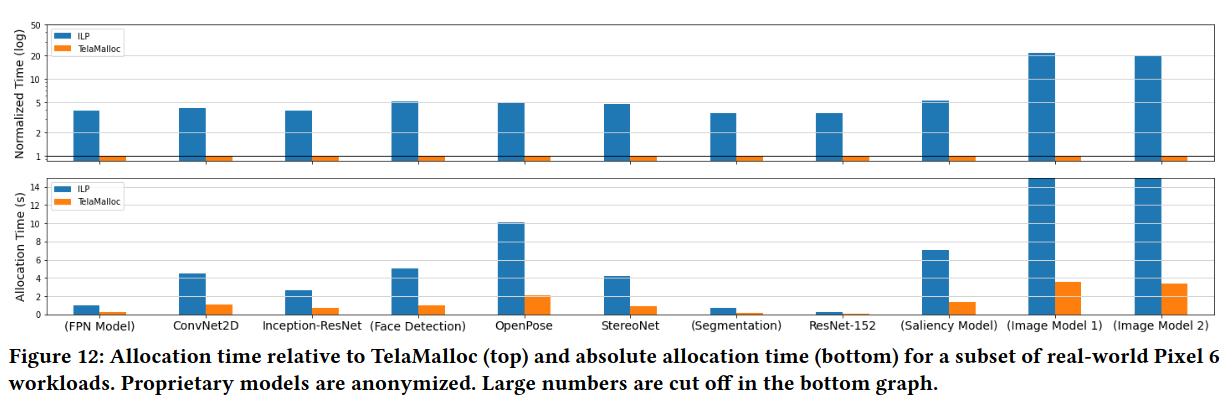
When comparing Telamalloc’s compilation of common models on the Pixel 6 running against a solver (which is capable of achieving near-optimal results given enough time), the memory allocations Telamalloc produces are nearly identical. Telamalloc is also able to achieve a, “median speedup of ≈ 4.7× across the benchmark”.
Conclusion
Telamalloc is an interesting paper because it discusses a combination of existing algorithms with optimizations tailored to improve user experiences relying on ML models. The paper also discusses using ML to make the performance of “smart” backtracking better - the idea of feeding in-the-wild data back into an algorithm to improve it over time is fascinating to me. This pattern also shows up in places like Java’s JIT compiler which takes data about a program’s performance and execution, then uses that to make the program better over time. Beyond the technical details of the paper, I also appreciated its focus on the impact to users - being able to compile models efficiently and successfully across a wide range of hardware is critical to making new AI-powered capabilities accessible to all.