micahlerner.com
Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network
Published December 13, 2022
Found something wrong? Submit a pull request!
Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network
What is the research?
The paper, Jupiter Rising: A Decade of Clos Topologies and Centralized Control in Google’s Datacenter Network, discusses the design and evolution of Google’s datacenter network. In particular, the paper focuses on how the network scaled to provide high-speed connectivity and efficient resource allocation under increasing demand.
At the time that the authors initially started their work, the network structure of many data centers relied on large, expensive switches with limited routes between machines. Many machines sharing few routes constrained network bandwidth, and communication between machines could quickly overload the networking equipment. As a result, resource intensive applications were often co-located inside of a datacenter, leading to pockets of underutilized resources.
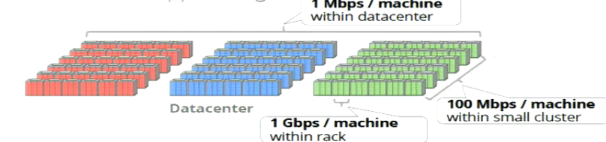
Scaling the network came down to two factors: reshaping the structure of the network using Clos topologiesThere is a great deep dive on the inner workings of Clos topologies here. and configuring switches using centralized control. While both of these techniques were previously described in research, this paper covered their implementation and use at scale.
The paper also discusses the challenges and limitations of the design and how Google has addressed them over the past decade. Beyond the scale of their deploymentThe authors note that the, “datacenter networks described in this paper represent some of the largest in the world, are in deployment at dozens of sites across the planet, and support thousands of internal and external services, including external use through Google Cloud Platform.” , the networks described by the paper continue to influence the design of many modern data center networksSee Meta, LinkedIn, and Dropbox descriptions of their fabrics. .
What are the paper’s contributions?
The paper makes three main contributions to the field of datacenter network design and management:
- A detailed description of the design and evolution of Google’s datacenter network, including the use of Clos topologies and centralized control.
- An analysis of the challenges and limitations of this network design, and how Google has addressed them over the past decade.
- An evaluation of the approach based on production outages and other experiences.
Design Principles
Spurred on by growing cost and operational challenges of running large data center networks, the authors of the paper explored alternative designs.
In creating these designs, they drew on three main principles: basing their design on Clos topologies, relying on merchant siliconThe paper describes merchant silicon as, “general purpose commodity priced, off the shelf switching components”. See article on Why Merchant Silicon Is Taking Over the Data Center Network Market. , and using centralized control protocols.
Clos topologies are a network designLaid out in A Scalable, Commodity Data Center Network Architecture. that consists of multiple layers of switches, with each layer connected to the other layers. This approach increased network scalability and reliability by introducing more routes to a given machine, increasing bandwidth while reducing the impact of any individual link’s failure on reachability.
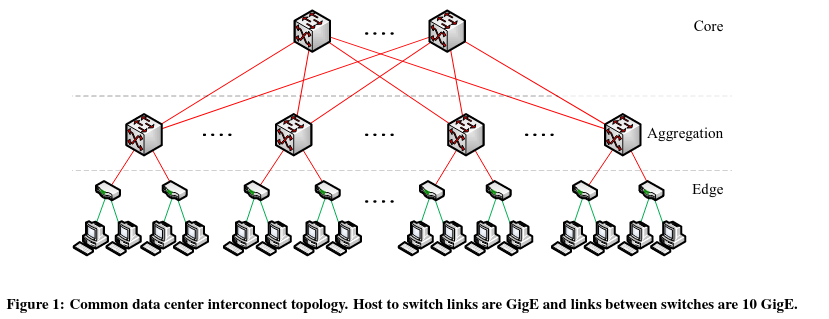
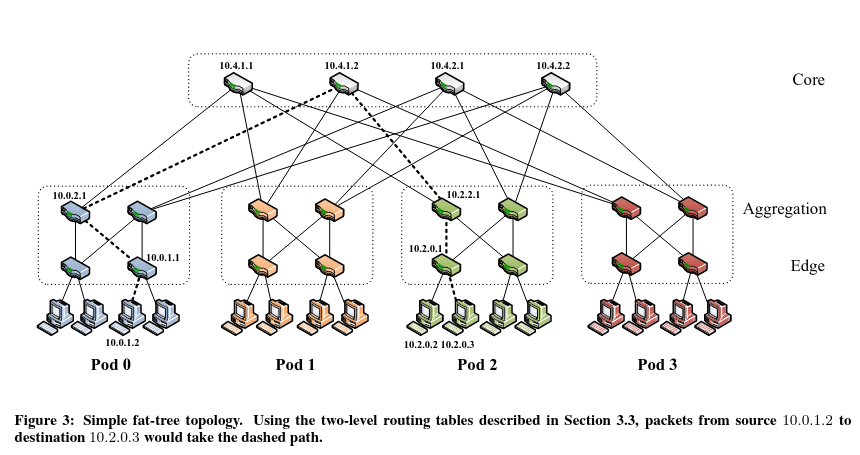
A design based on Clos topologies threatened to dramatically increase cost, as they contained more hardware than previous designs - at the time, many networks relied on a small number of expensive, high-powered, and central switches. To tackle this issue, the system chose to rely on merchant silicon tailored in-house to address the unique needs of Google infrastructure. Investing in custom in-house designs paid offThis investment was also offset by not spending resources on expensive switches. in the long term via a higher pace of network hardware upgrades.
Lastly, the network design pivoted towards centralized control over switches, as growing numbers of paths through the network increased the complexity and difficulty of effective traffic routing. This approach is now commonly known as Software Defined Networking, and is covered by further papers on Google networkingFor example, Orion: Google’s Software-Defined Networking Control Plane. .
Network Evolution
The paper describes five main iterations of networks developed using the principles above: Firehose 1.0, Firehose 1.1, Watchtower, Saturn, and Jupiter.
Firehose 1.0 was the first iteration of the project and introduced a multi-tiered network aimed at delivering 1G speeds between hosts. The tiers were made up of:
- Spine blocks: groups of switches used to connect the different layers of the network, typically making up the core.
- Edge aggregation blocks: groups of switches used to connect a group of servers or other devices to the network, typically located near servers.
- Top-of-rack switches: switches directly connected to a group of machines physically in the same rack (hence the name).
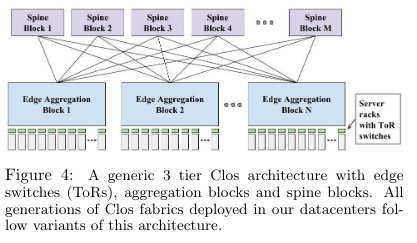
Firehose 1.0 never reached production for several reasons, one of which being that the design placed the networking cards alongside servers. As a result, server crashes disrupted connectivity.
Firehose 1.1 improved on the original design by moving the networking cards originally installed alongside servers into separate enclosures. The racks were then connected using copper cables.


Firehose 1.1 was the first production Clos topology deployed at Google. To limit the risk of deployment, it was configured as a “bag on the side” alongside the existing network. This configuration allowed servers and batch jobs to take advantage of relatively fast intra-network speeds for internal communicationFor example, in running MapReduce, a seminal paper that laid the path for modern ‘big data’ frameworks. , while using the relatively slower existing network for communication with the outside world. The system also successfully delivered 1G intranetwork speeds between hosts, a significant improvement on the pre-Clos network.
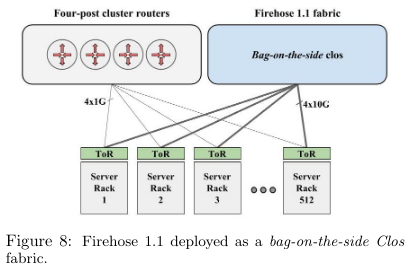
The paper describes two versions (Watchtower and Saturn) of the network between Firehose and Jupiter (the incarnation of the system at the paper’s publication). Watchtower (2008) was capable of 82Tbp bisection bandwidthBisection bandwidth represents the bandwidth between a network between two partitions in a network, and represents what the bottlenecks would be for networking performance. See description of bisection bandwidth here. due to faster networking chips and reduced cabling complexity (and cost) between and among switches. Saturn arrived in 2009 with newer merchant silicon and was capable of 207 Tbps bisection bandwidth.

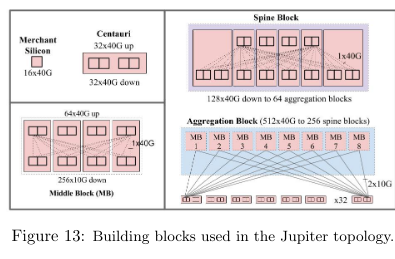
Jupiter aimed to support significantly more underlying machines with a larger network fabric. Unlike previous iterations running on a smaller scale, the networking components of the fabric would be too costly (and potentially impossible) to upgrade all-at-once. As such, the newest generation of the fabric was explictly designed to support networking hardware with varying capabilities - upgrades to the infrastructure would introduce newer, faster hardware. The building block of the network was the Centauri chassis, combined in bigger and bigger groups to build aggregation blocks and spine blocks.
Centralized Control
The paper also discusses the decision of implementing traffic routing in the Clos topology via centralized control. Traditionally, networks had used decentralized routing protocols to route trafficIn particular, the paper cites IS-IS and OSPF. The protocols are fairly similar, but I found this podcast on the differences between the two to be useful. . In these protocols, switches independently learn about state and make their own decision about how to route trafficSee this site on link-state routing for more information. .
For several reasons, the authors chose not to use these protocols:
- Insufficient support for equal-cost multipath (ECMP) forwarding, a technology that allows individual packets to take several paths through the network, and was critical for taking advantage of Clos topologies.
- No high-quality, open source projects to build on (which now exist via projects from the OpenNetworkingFoundation)
- Existing approachesIn particular, the paper talks about OSPF Areas, a design for splitting up a network into different areas, running OSPF in each, and routing traffic between the areas. The paper also references a rebuttal to the idea, called OSPF Areas Considered Harmful, that demonstrates several situations in which the routing protocol would result in worse routes. were difficult to scale and configure.
Instead, the paper describes Jupiter’s implementation of configuring switch routing, called Firepath. Firepath controls routing in the network by implementing two main components: clients and masters. Clients run on individual switches in the network. On startup, each switch loads a hardcoded configuration of the connections in the network, and begins recording its view based on traffic it sends and receives.
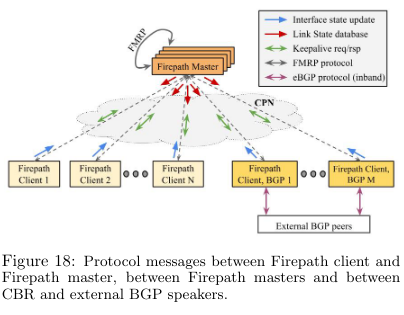
The clients periodically sync their local state of the network to the masters, which build a link state database representing the global view. Masters then periodically sync this view down to clients, who update their networking configuration in response.
Experiences
The paper also describes real world experiences and describes outages from building Jupiter and its predecessors.
The experiences described by the paper mainly focus on network congestion, which occurred because of:
- Bursty traffic
- Limited buffersAPNIC has a great description of buffers here. in the switches, meaning that they couldn’t store significant data.
- The network being “oversubscribed”, meaning that all machines that could use capacity wouldn’t actually be using it at the same time.
- Imperfect routing during network failures and traffic bursts
To solve these problems, the team implemented network Quality of Service, allowing it to drop low-priority traffic in congestion situations. The paper also discusses using Explicit Congestion Notification, a technique for switches to signal that they are getting close to a point at which they will not be able to accept additional packets. The authors also cite Data Center TCP, an approach to providing feedback built on top of ECN. By combining the two approaches, the fabric was able to achieve a 100x improvement in network congestionThis is mentioned in the author’s talk. From the talk, it isn’t clear if they also used other techniques alongside these two. .
The paper describes several outages grouped into themes.
The first is related to control software problems at scale, where a power event restarted the switches in the network at the same time, forcing the control software into a previously untested state from which it was incapable of functioning properly (without direct interaction).
A second category is aging hardware exposing previously unhandled failure modes, where the software was vulnerable to failures in the core network linksThis reminds me of the paper Fail-Slow at Scale: Evidence of Hardware Performance Faults in Large Production Systems! . Failed hardware impacted the ability of components to interact with the Firepath masters, causing switches to route traffic based on out of date network state (potentially forwarding it on a route that no longer existed).
Conclusion
The original Jupiter paper discusses several evolutions of Google’s networking infrastructure, documenting the false starts, failures, and successes of one of the biggest production networks in the world. The paper also provides an interesting historical persective on adapting ideas from research in order to scale a real production systemFor example, A scalable, commodity data center network architecture. . I particularly enjoyedAs always! the papers descriptions of outages and the efforts to reduce congestion using (at the time) novel technologies like DCTCPWhich is somewhat similar to a previous paper review on Homa. .
More recentely (at SIGCOMM 2022) the team published research expanding on the original design. This new paper covers further evolutions beyond Clos topologiesSee the blog here and the paper here. - I hope to read this in a future paper review!