micahlerner.com
Design and Evaluation of IPFS: A Storage Layer for the Decentralized Web
Published October 31, 2022
Found something wrong? Submit a pull request!
Discussion on Hacker News
Design and Evaluation of IPFS: A Storage Layer for the Decentralized Web
What is the research?
This paper discusses the open source IPFSIPFS is an acronym that stands for InterPlanetary File System. project, an implementation of a distributed file store. IPFS aims to support the “decentralized web”While many associate the idea of the decentralized web with cryptocurrencies, IPFS does not natively support (nor require) a cryptocurrency token. I haven’t covered cryptocurrency related technologies in this blog, but I know giving them even a slight acknowledgement can be a divisive topic :) That said, one of the main organizations involved in IPFS is also involved with FileCoin. , a growing ecosystem of distributed applications - for example, Elon Musk’s acquisition of Twitter has created a flock of new users to MastodonRelated tools discussed here for migrating. , a federated alternative. The authors argue that to reduce single points of failure and reliance on centralized cloud providers, applications need a distributed storage layerThe growth of these types of providers is covered in a previous paper review, Seven years in the life of Hypergiants’ off-nets! .
Originally released in 2015, IPFS is far from a research prototype - the system is deployed at scale, running on hundreds of thousands of machines around the world in order to serve a broad userbase. The project is technologically interesting because its implementation combines adaptations of core peer-to-peer network technologies with novel approaches to the unique challenges faced by the IPFS distributed storage system. For example, IPFS adapts the Kademlia distributed hash table (DHT)Distributed hash tables are a used for key value storage over a network of nodes. Kademlia is one specific design (notably used by Bittorrent. There is an excellent tutorial on distributed hash tables and Kademlia here. , implementing significant performance improvements and successfully deploying the approach to one of its widest known scales.
What are the paper’s contributions?
The paper makes three main contributions:
- Design and implementation of IPFS
- Creation and verification of measurement techniques to understand the network
- Evaluation of the distributed network structure and per-node performance
How does the system work?
The goal of IPFS is providing reliable data storage and retrieval across a distributed network of nodes.
To accomplish this goal, the network relies on three core functionalities:
- Content addressing: IPFS uniquely identifies immutable content stored on the networkThe idea of content-addressable storage is not necessarily new (the paper cites the Network Named Content paper from 2009), but has recently grown in popularity among distributed/decentralized applications (for example, the Secure Scuttlebutt Protocol also relies on it). Side note: the Secure Scuttlebutt docs do an amazing job of describing the protocol! . This approach simplifies storage and reference to the underlying data, as a node can use a unique key to unambiguously fetch content from its peers.
- Peer addressing: nodes in the network need to find and connect to one another.
- Content indexing: to simplify fast search and retrieval of data, nodes index the content stored by their peers. Peers advertise which content they store by sharing unique identifiers that address data).
Content Addressing
Content on the network is represented with two components: content identifiers and chunks.
To simplify storing and fetching data from the network, IPFS nodes create multi-part content identifiers for items. Each content identifier contains a version, encoding of the data (for example, JSON or protobuf), and a hash of the dataThe authors note that the IPFS protocol proactively integrated support for arbitrary hashing algorithms to defend against the possibility that any individual algorithm experiences a vulnerability (see Finding Collisions in the Full SHA-1). Many systems integrating hashing algorithms (including Bitcoin) do not have this level of support. . The hash of the data is particularly useful for checking the results of future fetches (as one can hash the resulting data, then compare it to the expected hash).
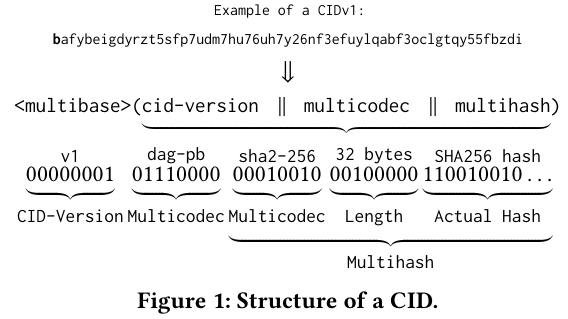
Each file in the network is divided into ~256kb chunks, and each chunk is referenced using one of the aforementioned content identifiers. Each file is made up of many chunks (most files are larger than 256kb), and IPFS represents the relationship between file chunks with a Merkle Directed Acyclic Graph (Merkle DAG)A Merkle-DAG is a data structure similar to a Merkle-tree but without balance requirements. Merkle tree-like datastructures show up in a number of places in computer science. . IPFS chose a DAG structure (instead of the more common Merkle Tree) to represent more complex relationships between chunks - for example, a chunk could show up several times within the same file. A tree-like structure would handle the duplicate chunk case by storing multiple copies of the chunk. In contrast, the DAG structure can add a new edge to the graph, making for a lighter weight approach (edges would be on the order of bytes, while chunks are ~256kb).
Peer Addressing
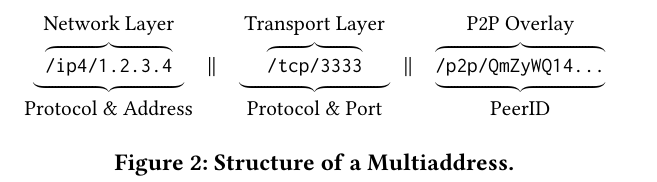
Connecting with and communication between nodes in the network allows the distributed nature of IPFS. To that end, nodes in IPFS identify themselves using a multiaddress containing multiple layers of information required to reach each node. The top layer includes IPFS-specific peer-to-peer data - in particular, a Peer ID corresponding to a node’s hashed public keyLike many decentralized systems, IPFS relies on public-key cryptography to establish identity/ownership. The implementation that the project is based on is described here. . The other layers represent more familiar networking information (protocol, address, and IP).
Content Indexing
Nodes in the network store a datastructure containing mappings between content identifiers and peers storing the object. Each node stores and updates a partition of a decentralized global structure called a distributed hash table (DHT) (so called because it represents a mapping of which nodes have which data, spread throughout the network). Other peer-to-peer networks (most notably BitTorrent) rely on the DHT datastructureThe Bittorrent implementation is called the Mainline DHT. There are several interesting characterizations of the system, including Measuring Large-Scale Distributed Systems: Case of BitTorrent Mainline DHT. , but IPFS adapts its implementation to improve performance.
The main differentiated aspect of IPFS’ DHT implementation is representing two types of peering to the DHT: clients and servers.
Clients have limited capabilites, while servers do not - clients can “only request records or content from the network but do not store or provide any of them”. The purpose of clients is allowing nodes to access data in the network without other nodes coming to rely on them.
One of IPFS’ main insights is that the, “DHT client/server distinction prevents unreachable peers from becoming part of other peers’ routing tables, thus speeding up the publication and retrieval processes.” In contrast, Bittorrent neither differentiates between different types of clients, nor effectively prunes dead nodes - leading to median lookup latency of over a minute.
IPFS in Action
There is a multistep process for a node to publish data, for that data to be reachable by other nodes, and for other nodes to retrieve it.
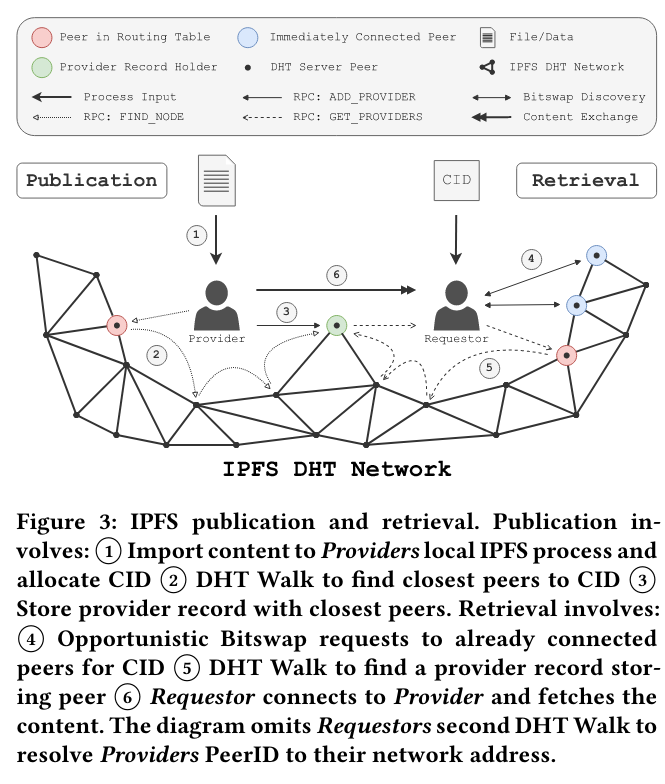
First, a node imports data locally and gets a content identifier that uniquely identifies the data. Then, the node publishes a provider recordSource for the provider functionality is here. to nearby neighbors in the DHT, effectively announcing that the new data is available on the network.
Freshness is an important property of these records, as out-of-date state increases client latency (as the client must go through multiple roundtrips to find a valid record, if any node has the data at all). To limit staleness of these records, IPFS nodes implement two parameters: a republish interval (which ensures that there is a minimum number of nodes aware of the content), and an expiry interval (which requires a provider of the data to continously refresh the record).
Once another node wants to retrieve a specific piece of content from the network, it connects to peers and performs the BitSwap protocolThe protocol is a novel component of IPFS, and both specification and implementation are fully open source. The authors also published a separate paper on the protocol, Accelerating content routing with Bitswap: A multi-path file transfer protocol in IPFS and Filecoin. , a process for propagating and receiving information on the data that a node hosts. If all chunks are not found at this stage, the requester walks the DHTFor a great overview of more DHT internals, I highly recommend this guide. in order to find peers that have it stored. If the requester contacts a node that doesn’t have the data stored (and only has the provider record, indicating that the data exists somewhere in the network), the node redirects to the actual location of the data.
The paper also touches on the idea of IPFS Gateways, which serve as user-friendly entrypoints based on HTTP (which limits the need for someone to run an IPFS node to access the network). Gateways also host data for long periods of time (an operation called “pinning”) to speed up retrieval and increase availability. The paper references a list of publically available gateways here.
How is the research evaluated?
To understand user distribution and usage patterns, the paper first characterizes the structure of the IPFS network using data gathered via a custom scraper node extended to record metadata about the network, including peers and their uptimeThe authors also store the data for the study on IPFS itself! .
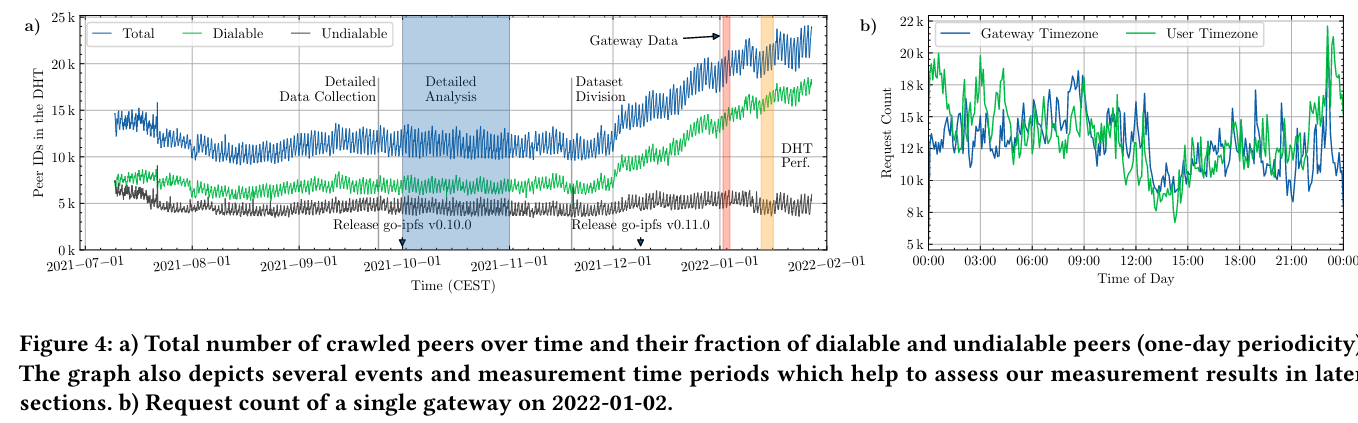
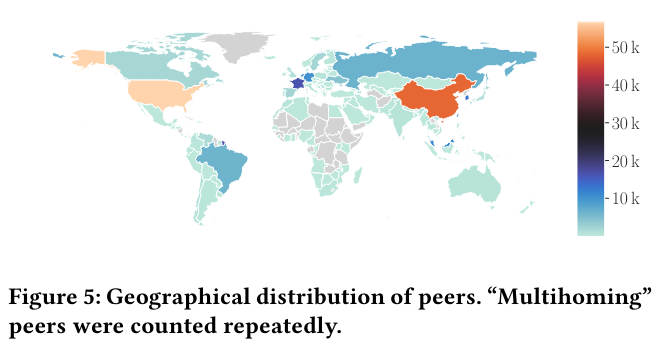
The paper then uses this dataset to quantify the distribution of nodes around the world and their presence in Autonomous SystemsA previous paper review, Seven years in the life of Hypergiants’ off-nets discusses similar topics. . Grouping by peer count per country - “The US (28.5%) and China (24.2%) dominate the share of peers, followed by France (8.3%), Taiwan (7.2%), and South Korea (6.7%).” After mapping peer IDs to Autonomous zones, a surprisingly low share of nodes are hosted on cloud providers.
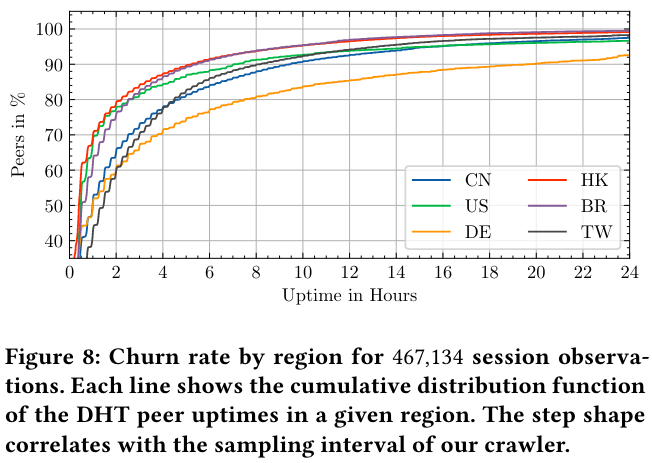
The paper also measures the churn of nodes in order to track the health of the network. Over time, many nodes go offline or become unavailable.
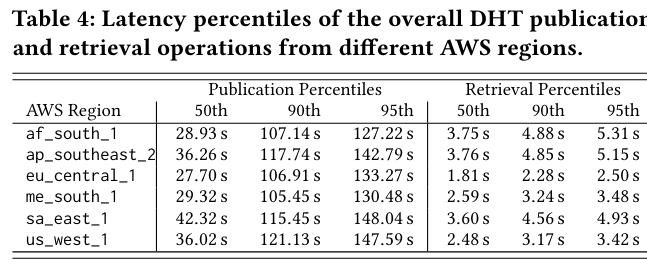
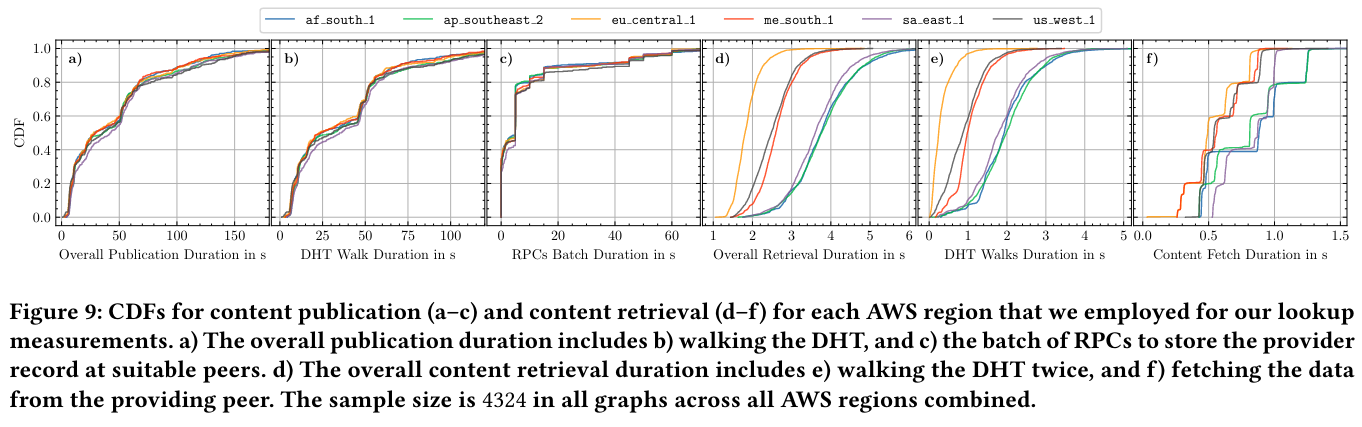
The paper also considers single node performance of the core tasks that a node performs: publication, and retrieval of data. Timely execution of these functionalities are critical for ensuring that the IPFS network remains healthy. There are several key takeaways from this section - first, the paper notes that publication of data to the network (via inserting entries into the DHT) does not depend on the size of the data associated with the content identifier. Second, retrieval is generally faster than publication, and walking the DHT (to find nearby peers) is the most time consuming components of this operation.
Conclusion
The IPFS paper represents a new infrastructure component capable of supporting the burgeoning ecosystem of decentralized applications. The implementation builds on several ideas from other distributed networks (including BitTorrent), and I enjoyed reading about the production-informed optimizations to core technologies, like the Kademlia DHT. Going forward, it will be interesting to see if IPFS is capable of providing high-quality p2p storage while maintaining its goal of decentralization - throughout the paper, the authors note the growth of gateways aimed at improving the user experience. Furthermore, IPFS is primarily developed by members or alumni of one organization, Protocol Labs. For the IPFS ecosystem to thrive, extending beyond this structure will be critical.