micahlerner.com
Automatic Reliability Testing For Cluster Management Controllers
Published July 24, 2022
Found something wrong? Submit a pull request!
These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
Automatic Reliability Testing For Cluster Management Controllers
What is the research?
To run applications at scale, many companies deploy servers in the cloud. Managing these servers is a complex task, often handled by a cluster manager like KubernetesOne of the critical parts of Kubernetes, its scheduler, is based on learnings from building Omega and Borg at Google. . Kubernetes controls what is deployed on a cluster by relying on state-based operatorsGreat documentation on operators is here. that consume the state of the cluster through API calls. These operators then send configuration messages to ensure that the cluster converges to a desired state.
The operator pattern is powerful and usefulAs evidenced by hundreds of open source operators. , but it can be difficult to test how operators perform in a real-life distributed environment (where they must handle cases like executing actions based on stale state, missing updates, and operation in the face of crashes).
To address this difficulty, the paper aims to automate the testing by mutating the state that an operator depends on, and observing the effects. The authors implemented their design in an open source project, called Sieve. Since its release, the project found numerous bugs in open source Kubernetes components, demonstrating the approach’s utility and a promising future for the approach in the toolkit of developers working on Kubernetes operators.
Background
The paper focuses on an implementation of automated testing targeted at a primary open source cluster manager, Kubernetes. Following commands issued by a CLILike kubectl. or via automated processes, Kubernetes changes what is deployed on a cluster (and where), with the goal of making the cluster converge to a desired state. A critical component Kubernetes uses to control resources is the Operator pattern.
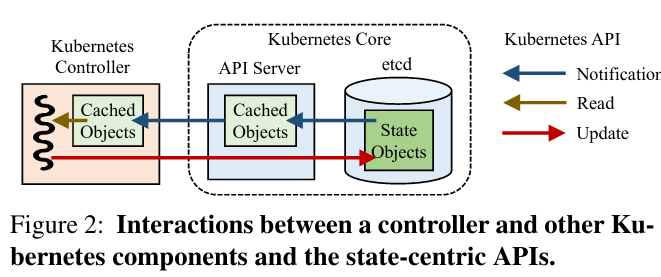
To change the cluster, a controller reads a view of cluster state (which may be cached to limit the number of read requests) from API servers. This state-based approach allows a testing framework to systematically manipulate cluster information, introducing common problems that occur in distributed systems (like components operating with stale state of the world incorrectly issuing commands).
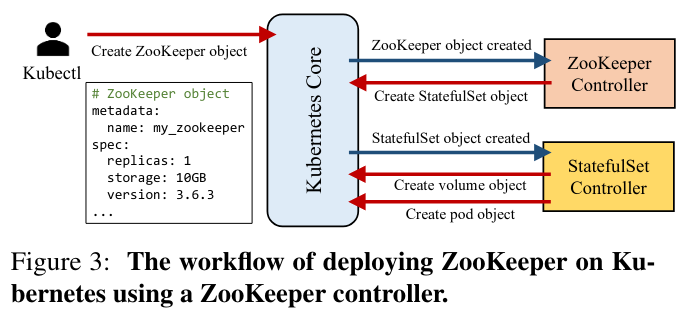
What are the paper’s contributions?
The paper makes three main contributions:
- A technique that allows automatic testing of cluster management systems
- An implementation of the design, published as the Sieve open source project
- An evaluation of the approach based on real-world bugs discovered with Sieve
How does the system work?
Kubernetes controllers rely on state to make decisions. Sieve relies on this fact in order to test the performance of controllers in the presence of various failure modes. After altering cluster state, Sieve records the actions an operator takes following this altered state, comparing them to the controller’s actions in baseline conditions (without injected failures). Any differences between the two sets of actions are flagged for the developer of the Kubernetes controller, allowing them to visualize how an operator behaves in complex conditions.
Before a developer can take advantage of Sieve functionality, they first must add support for the project to their operatorAs of 2022-08-13, there is a setup script available. . These setup steps not only define the interaction between Sieve and the operator, but also include definitions for workloads representing the critical flows that an operator executes and their desired end states - one example configuration for the MongoDB operator is here.
Once configured, Sieve’s testing process roughly divides into three high level steps:
- Observing normal system operations: Sieve aims to understand the actions an operator takes in the absence of failure modes.
- Generating and executing test plans: using traces of normal operating behavior, Sieve systematically determines which failures to insert and when. Then, it observes whether failure modes impact operator behavior.
- Checking and outputting results: after inserting failures during test runs, Sieve compares the operator’s behavior to what it does under normal operating conditions.
Observing system operations
Following the initial configuration described above, Sieve collects reference traces representing the interactions that a Kubernetes controller has with other components in the system. The implementation records interactions by intercepting calls in the client library, and at Kubernetes API serversInterstingly, the paper mentions that it uses a library called dst to insert these calls - from spelunking in the code, it looks that an example usage is here. . This instrumentation allows Sieve to observe commands like Create, Update, and Delete that the operator under test sends.

Generating, pruning, and executing test plans
After collecting data on workloads in the normal operation of the system, Sieve generates test plans that it could use to evaluate the impact of different failure modes on an operator’s ability to function correctly.

When generating test plans, Sieve aims to detect three main types of bugs related to intermediate states, stale states, and unobserved states.
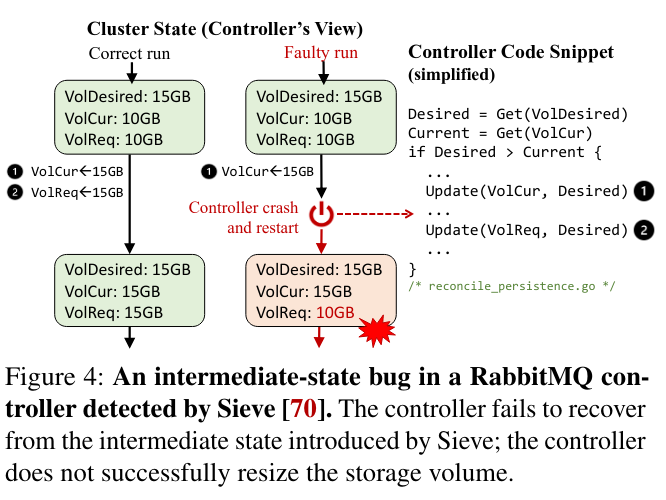
Intermediate state bugs often happen when a controller implements a multi-step update process, but incompletely handles crash recovery - Kubernetes controllers are deployed in cloud environments, and must be resilient to crashes that could occur at any time. If a controller crashes while mid-update, the data it uses following recovery may not accurately represent the state of the system before the crash (meaning that the controller may or may not the execute the code path it would have in the absence of the failure).
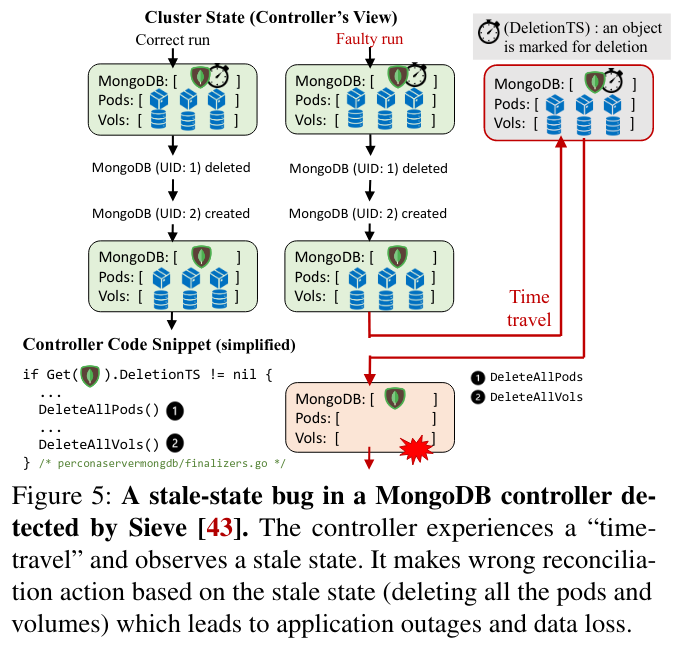
Stale state bugs occur when an operator doesn’t completely handle out-of-date views of the cluster. A controller could read stale states because of the multiple levels of caching in a Kubernetes cluster, or because of the distributed nature of the servers that the controller reads state fromThere is an open bug on the impact of stale reads in Kubernetes where the Sieve have a proposed mitigation. . If a controller reads a stale state of the cluster, it could time-travel backwards, reissuing now out-of-date commands. One case where this could result in unintended behavior is if a controller repeatedly shuts down resources while trying to perform a restart operation Example stale-state bug from MongoDB’s controller. .
Lastly, unobserved state bugs happen when a controller doesn’t receive feedback (potentially due to lost messages on the network). As a result of this type of bug, a controller could leave dangling resources, wasting cluster resources.
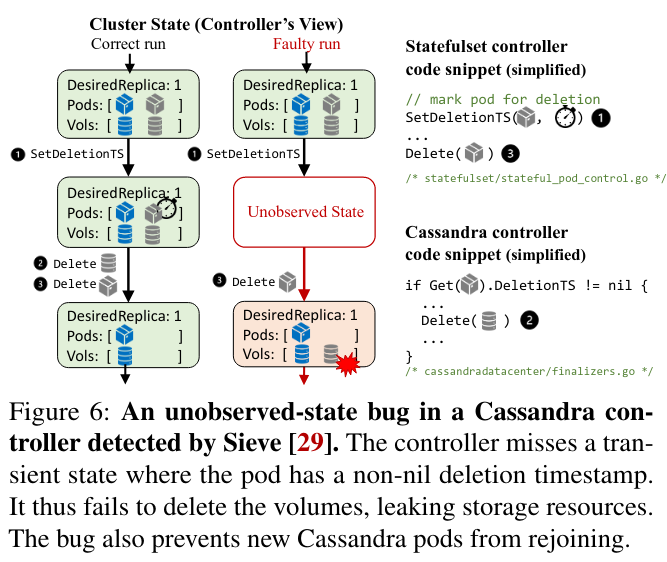
To test for these three types of bugs:
Sieve currently supports several primitives that test plans can compose to introduce complex faults: 1) crash/restart a controller, 2) disconnect/reconnect a controller to an API server, 3) block/unblock a controller from processing events, and 4) block/unblock an API server from processing events.
Running all potential test plans would dramatically increase the execution time of Sieve tests. To limit this issue, Sieve prunes ineffective plans using several techniques. One of these ideas is called “pruning by causality”, which relies on relationships between the notifications that a controller receives and the updates that it outputs to other parts of the system - if a notification under normal operating conditions doesn’t result in an output update, Sieve skips manipulating that notification.

Another technique that Sieve uses to prune test plans is skipping controller commands that do not impact the cluster (which could happen if a controller repeatedly reissues the same RPC). While this case theoretically shouldn’t happen (as redundant updates from a controller to the cluster are wasteful of networking/computing resources), the paper notes that hidden bugs could send many versions of the same update unnecessarily.
After pruning ineffective plans, the system executes the test plans according to the configured faults and triggers specified - example test plans are available in the Sieve repository.
Checking results
Following the completion of executing test plans, the system compares normal executions to those with injected failure modes.
Specifically, Sieve checks:
- End states: controllers running under injected failures and normal operating conditions should reach the same expected values for deployed components (like successful container turndown/turnup)
- State-Update Summaries: controllers running under injected failures and normal operating conditions should issue the same update commands to the clusterThe paper notes that ordering of commands doesn’t necessarily matter as much as the content of those commands. . This check is important to catch situations where a cluster ends up the same state through buggy behavior.
Following the execution of a test plan, Sieve outputs detected differences (either in end states or in the path to achieve them), and the combination of triggers that caused it
How is the research evaluated?
The paper evaluates Sieve on three dimensions: “1) Can Sieve find new bugs in real-world controllers? 2) Does Sieve do so efficiently? 3) Are Sieve’s testing results trustworthy?”.
To evaluate the first question, the paper considers several example controllers that the framework is applied to. Sieve was able to find 46 controller bugs in open source controllers that would have been difficult to find otherwise. These bugs have consequences like application outages, data loss, security vulnerabilities, and resource leakage. Notably, Sieve finds issues in official operators with significant developer backing, like the cass-operator from DataStax and the elastic-operator from MongoDB. These bugs would be very difficult to find without automated testing that Sieve provides - one example bug from the DataStax cass-operator happens if the controller crashes in a specific step of a multi-step process related to setting up a key store.

To evaluate whether Sieve efficiently finds bugs, the paper considers the system’s total testing time, and the effectiveness of how it trims the search space of tests to perform. This analysis finds that tests run in tens of hours after reducing the number of test plans.
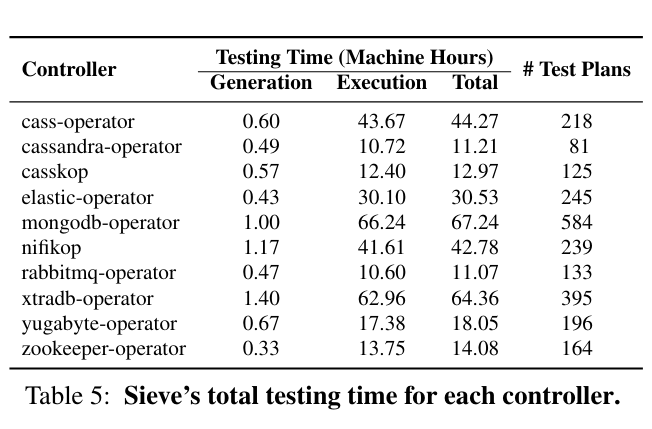
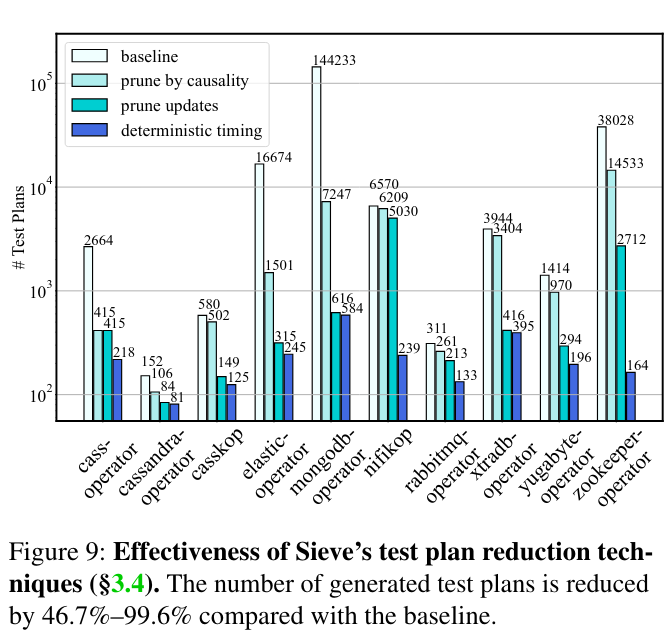
Lastly, Sieve “has a low false positive rate of 3.5%”, meaning that developers are able to trust the system, rather than treating it like a flaky test frameworkIt would be interesting to hear more about why the false positives happened. .
Conclusion
Controllers are a critical part of deploying applications on Kubernetes, but have historically been difficult to test. By employing a state-based approach, Sieve is able to find bugs in even mature projects! Given that there will be continued development of these important components in the futureAnd Kubernetes seems here to stay… , automated testing of their behavior is an exciting and extremely useful area of research.