micahlerner.com
Sundial: Fault-tolerant Clock Synchronization for Datacenters
Published July 03, 2022
Found something wrong? Submit a pull request!
After this paper, I’ll be switching gears a bit and reading/writing about papers from OSDI 2022. These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
Sundial: Fault-tolerant Clock Synchronization for Datacenters
What is the research?
The Sundial paper describes a system for clock synchronization, an approach to building a view of time across many machines in a data center environment. Time is critical to distributed systems, as many applications rely on an accurate time to make decisions - for example, some distributed databases use time to determine when it is safe to commit transactionsIn particular, this idea is used by Spanner. There is a great overview of Spanner from the MIT distributed system’s course, and useful summaries by Timilehin Adeniran here and Murat Demirbas. . Furthermore, fast and accurate time enables new applications in data center environments, like basing congestion control algorithms on one way delayThe paper cites Swift: Delay is Simple and Effective for Congestion Control in the Datacenter, which I hope to read in a future paper review. .
Unfortunately, building a view of time across many machines is a difficult problem. Clock synchronization, the approach described by the Sundial paper, involves reconciling many individual data points from disparate computersAccurate time at even a single computer / location is also a difficult problem! . Implementing systems not only need to build distributed-system-like logic for communication, but also have to handle the failure modes of clocks themselves (including measurement drift due to factors like temperature changes).
Other systems have tackled clock synchronization (in particular TrueTime), and the Sundial paper aims to build on them. In particular, one design choice that the paper reuses is not providing a single global measurement of time. Instead, the machines in the system maintain a time and an associated error bound, which grows and shrinks according to several factors (like how recently the node has synchronized its time with others). In other ways, Sundial differs from prior research - specifically, the system described by the paper prioritizes detection and recovery from failures. As a result, it provides more accurate and resilient time measurements, improving application performance and enabling applications that require timeWhile I mentioned that accurate time is useful for congestion control, applications like distributed tracing also benefit - being able to line up events across a system relies on a shared understanding of how they relate to one another. .
Background
Fast and accurate time measurements are an important problem to solve for datacenter environments, for which there are several existing solutionsExisting solutions include HUYGENS, Datacenter Time Protocol (DTP), and Precision Time Protocol (PTP). .

Each implementation makes tradeoffs around:
- Type of clocks used: do you use few expensive clocks or many commodity clocks?
- Overhead of clock synchronization: which networking layer does clock synchronization happen on? Hardware support allows lower overhead networking communication, but can require custom devices (which increases the difficulty of implementation).
- Frequency of clock synchronization: how often do nodes in the system synchronize their clocks? Clock synchronization consumes networking resources, but the frequency of synchronization determines how much clocks drift from one another.
- Which nodes communicate with one another: should nodes communicate in a tree or a mesh? Asynchronously or synchronously? This decision also balances networking overhead with clock error.
Deciding the type of clocks used comes down to choosing between cost and clock accuracy. On one end of the spectrum, a system can have expensive and accurate clocks in a network, then connect computers to those sources of truthThis post from Kevin Sookocheff is a handy overview for TrueTime. . Another approach is to have many commodity datacenter clocks that synchronize with each other to get a global view of timeGraham: Synchronizing Clocks by Leveraging Local Clock Properties is a paper along these lines that I hope to cover in a future paper review. - clocks in these types of systems often use crystal oscillatorsThis reference talks about the difference between crystal oscillators and more expensive/accurate clocks. which can drift for a variety of reasons, including “factors such as temperature changes, voltage changes, or aging”.
To limit error in time measurements, the clocks periodically sync with one another by transmitting messages on the network.
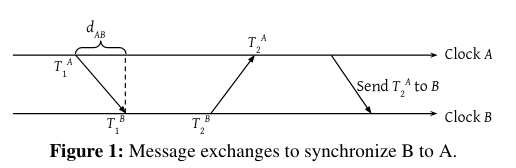
This communication contributes to the overhead of clock synchronization. Sending messages on different levels of the networkFrom the OSI model. incurs different overheads, and can also require specialized hardware. For example, one predecessor to Sundial (Datacenter Time Protocol), relies on hardware support (which could be a blocker to adoption). At the same time, Datacenter Time Protocol is able to send messages with zero overhead by making use of special hardware. In contrast, other clock synchronization implementations send messages at higher levels of the network stack, limiting reliance on custom hardware, but incurring higher overheads.
Another set of tradeoffs is deciding the frequency of clock synchronization - more frequent messaging places a bound on how much clocks can drift from one another, increasing accuracy at the cost of networking overhead. This decision also contributes to how fast a node is able to detect failure upstream - assuming that a node fails over to using a different upstream machine after not receiving n messages, longer intervals between each synchronization message will contribute to a longer time for the node to react.
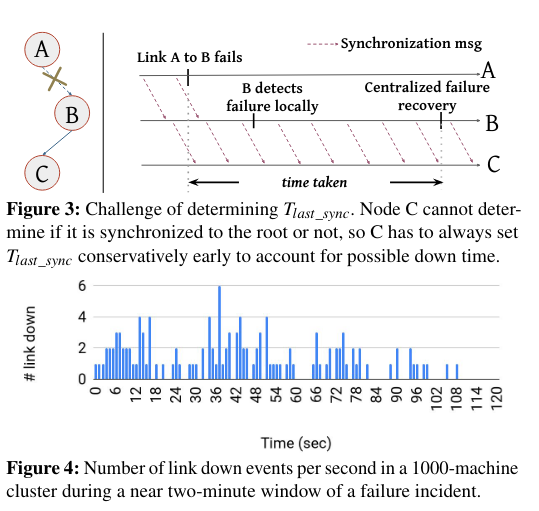
A clock synchronization implementation also needs to decide which nodes comunicate with each other, and whether there is a single “primary” time that must propagate through the system. Communication can happen through several different structures, including mesh or treeThe paper talks about using a spanning tree - it is always fun to see content from a datastructures course pop up in research. topologies. Furthermore, nodes in the network can communicately synchronously or asynchrously, potentially blocking on receiving updates from upstream nodes.
What are the paper’s contributions?
The paper makes three main contributions:
- The design of a system capable of quickly detecting and recovering from clock synchronization failures (leading to time measurement errors).
- Implementation of the design, including details of novel algorithms associated with failure recovery.
- Evaluation of the system relative to existing clock synchronization approaches.
How does the system work?
Based on a study of previous systems, Sundial establishes two design requirements: a small sync interval (to limit error in time measurements), and fast failure recovery (to ensure minimal interruption to clock synchronization when failure occurs).
The small sync interval ensures that a machine sends out synchronization messages periodically and is able to detect when it hasn’t received communication from upstream nodes. To keep track of the interval, the design relies on a periodically incrementing counter in custom hardware (discussed in more detail in the Sundial Hardware section). While implementing such a counter is possible in software, doing so was likely to consume significant CPU. Building a counter in hardware offloads this functionality to a component dedicated for the function.
Each node in a Sundial deployment contains a combination of this specialized hardware and software to handle several situations: sending synchronization messages, receiving synchronization messages, and responding to failures.
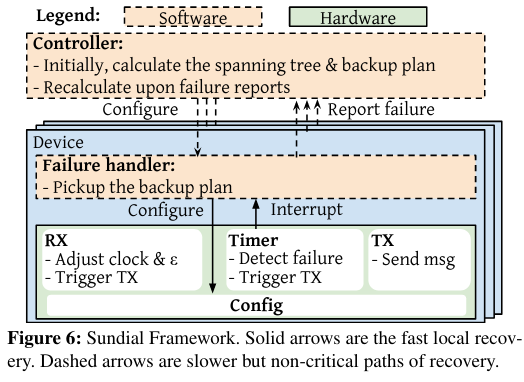
Nodes determine how to send and receive synchronization messages based on a netowrk represented via a spanning tree, and a node’s position in the tree (root or non-root) determines its behavior. Synchronization messages flow through the network from root nodes downwards, and when downstream nodes detect that upstream nodes are not sending these messages, the network reconfigures itself to exclude the failing machines.
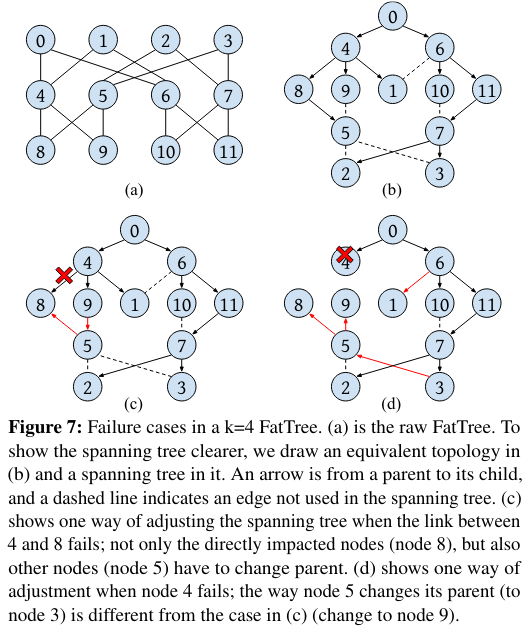
Sundial Hardware
The Sundial Hardware is active in sending synchronization messages, receiving synchronization messages, and responding to failures.
As mentioned above, synchronization messages flow through the tree from root nodes to non-root nodes. Root nodes send messages periodically, using a continuously incrementing interal counter. After the counter reaches a threshold, the root sends synchronization messages downstream.
When a nodeRoot nodes don’t receive from other nodes. receives a synchronization message, it processes the incoming message (updating its clock and error), resets the timeout used to detect failure in upstream nodes, then sends synchronization messages to its own downstream nodes.
If a node doesn’t receive a synchronization message before several sync intervalsEach sync interval is defined by a configurable time period associated with ticks of the hardware counter. passFrom the paper, “The timeout is set to span multiple sync-intervals, such that occasional message drop or corruption doesn’t trigger it.” (as measured by the hardware counter), the hardware will trigger an interrupt to prompt failure recovery by the software component of Sundial (handling this situation is discussed in more detail in the next section).
Sundial Software
The Sundial software has two primary responsibilities: handling failure recovery when it is detected by hardware, and pre-calculating a backup plan.
Sundial hardware triggers an interrupt to signal failure when an upstream node stops sending synchronization messages. To recover from failure, a machine follows a backup plan that is computed and distributed to nodes by a central component of Sundial, called the Centralized Controller. The backup plan includes information on which node(s) to treat as the upstream and/or downstream nodes.
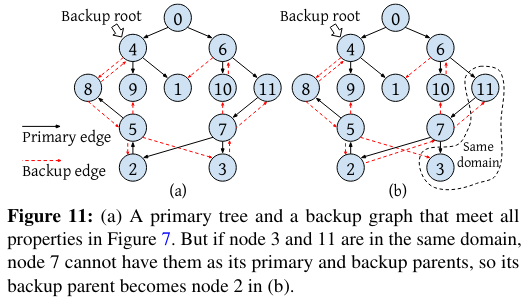
To ensure that failure recovery succeeds, the Centralized Controller constructs the backup planThe paper also describes the details of several subalgorithms involved in calculating the plan, and I highly encourage those interested to reference those very interesting details (which take advantage of several graph/tree algorithms). following several invariants:
- No-loop condition: nodes in a subtree must connect to nodes outside of the subtree, otherwise there is no guarantee that the backup plan will connect the subtree to the root node. If the subtree is not connected to the root node, then synchronization messages will not flow.
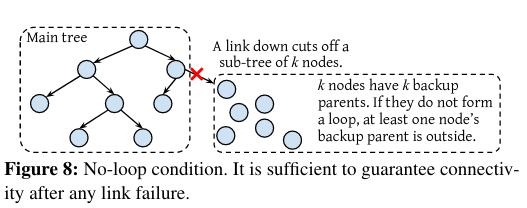
- No-ancestor condition: a node can’t use its ancestor as a backup because the downstream node won’t be connected to the tree if the ancestor fails.
- Reachability condition: the backup plan contains a backup root in case the root fails, and the backup root must have a path to all nodes (otherwise synchronization messages won’t fully propagate).
- Disjoint-failure-domain condition: a node’s backup can’t be impacted by the same failures as the given node, unless the given node also goes down (this stops a node from being isolated).
- Root failure detection: when the root fails, a backup root should be able to be elected (so that recovery is possible).
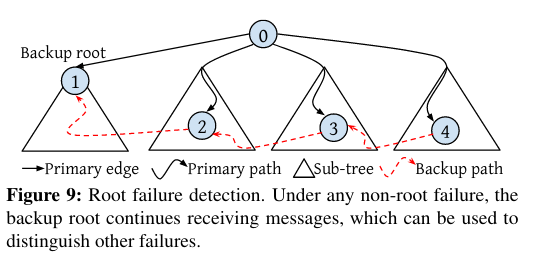
The paper points at several potential issues with a precomputed backup plan - one of which is the idea of concurrent failures that the backup plan hasn’t anticipated. In this situation, error grows large but the controller can still recover due to the Disjoint-failure-domain condition.
How is the research evaluated?
The Sundial paper contains an evaluation on several metrics. First, the paper compares Sundial to other existing implementations of clock synchronization in both non-failure conditions and failure conditions.
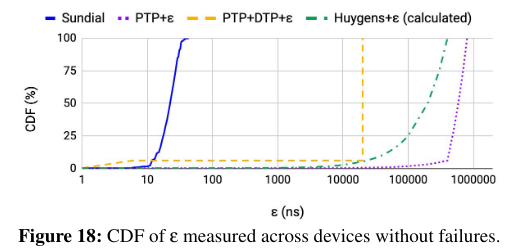
In non-failure conditions, Sundial has the lowest error because it is able to maintain a small sync interval and synchronize clocks in the network quickly.
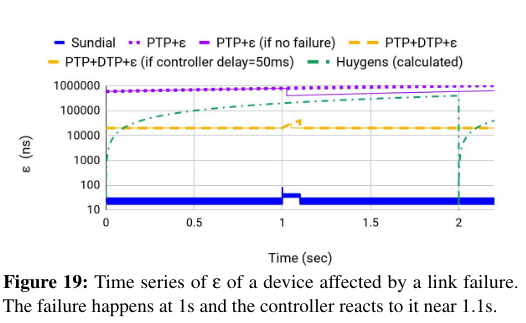
In failure conditions, Sundial has fast failure recovery, resulting in the lowest error increases in abnormal conditions (as visible from the lower overall error and small sawtooth pattern in the graph below).
The paper also evaluates the implementation’s impact on applications. As mentioned at the beginning of the paper, more accurate clock synchronization confers several advantages. The paper evaluates this claim by including commit-waitTimilehin Adeniran’s article on Spanner covers the idea of commit wait. latency for Spanner - when the database decides to commit a transaction, it waits until a time after the error bound. Thus, reducing the error bound allows Spanner to commit earlier, an affect visible in the latency of a load test that relies on the database.

Conclusion
The Sundial paper is one of several papers I’ve been reading about time and clock synchronization. In particular, one of the components of the research I enjoyed was its deep dive on the constraints and algorithm internals associated with building a backup plan - it is always intriguing to see how simple data structures represent the core of solutions to complex problems. I also enjoyed the paper’s description of where Sundial is in the design space of the problems it is trying to address. This type of in-depth discussion is often left to the reader, and it is refreshing to see it spelled out explicitly.