micahlerner.com
Monarch: Google’s Planet-Scale In-Memory Time Series Database
Published April 24, 2022
Found something wrong? Submit a pull request!
Discussion on Hacker News
These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed. As always, feel free to reach out on Twitter with feedback or suggestions!
Monarch: Google’s Planet-Scale In-Memory Time Series Database
What is the research?
Monarch is Google’s system for storing time-series metricsTime-series data describes data points that occur over time. Storing and using this type of information is an active area of research and industry development. . Time series metricsMetrics are one of the main components in an observability stack (among tracing, events, and logging). The paper Towards Observability Data Management at Scale has more information on the other components of the stack. are used for alerting, graphing performance, and ad-hoc diagnosis of problems in production.
Monarch is not the first time series database, nor is it the first optimized for storing metricsInfluxDB, TimescaleDB, Prometheus, and Gorilla are just a few of the existing time series databases. , but the system is unique for several reasons.
First, Monarch optimizes for availability - you wouldn’t want a metrics system to be down before, during, or after a production incident, potentially lengthening the time to detection or resolution of an outage. One example of this tradeoff in practice is Monarch’s choice to store data in (relatively) more expensive memory, rather than on persistent storage. This design choice limits dependence on external databases (increasing availability by limiting dependencies), but increases cost.
Second, Monarch chooses a push-based approach to collecting metrics from external services. This is contrast to pull-based systems like Prometheus and Borgmon (Monarch’s predecessor)The paper notes that the pull-based approach, “Other existing metrics databases, like Facebook Scuba also use a push-based approach. . The paper notes several challenges with a pull-based approach to gathering metrics, including that the monitoring system itself needs to implement complex functionality to ensure that relevant data are being collected.
What are the paper’s contributions?
The Monarch paper makes four main contributions:
- An architecture for a time-series database capable of operating at global scale
- A data model and query language for accessing metrics
- A three-part implementation, covering a collection pipeline for ingesting metrics, a query interface, and a configuration system
- An analysis of the system running that scale
How does the system work?
Architecture
To implement these features at a worldwide scale, Monarch contains global and zone components.
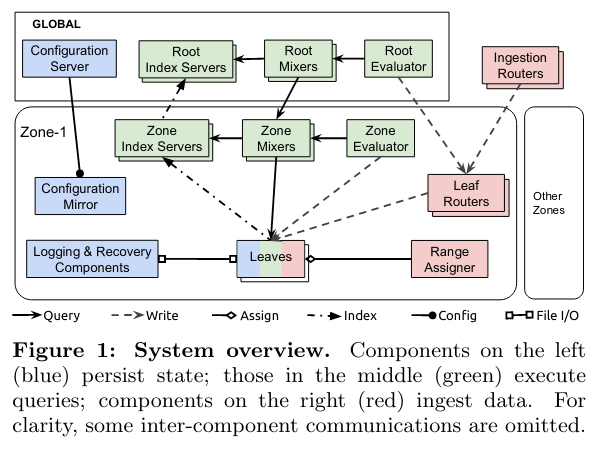
Global components handles optimal query execution, and store primary copies of global state (like configuration). In contrast, Zone components are responsible for providing functionality for a subset of metrics data stored in the given area, and maintaining replicas of global state.
Dividing Monarch into Global and Zone components enables scaling and availability of the system. In the presence of availability issues with global components, zones can still operate independently. Zones can also operate with stale data, highlighting the consistency tradeoff that Monarch makes in order to gain availability.
At the bottom level of the Monarch stack are Leaf nodes that store metrics data in-memory (formatted as described in the next section on the data model). Leaves respond to requests from other parts of the system in order to receive new data that needs to be stored, or return data in response to a query.
Data Model
Monarch stores data in tables. Tables are built from combinations of schemas, which describe data stored in the table (like column names and datatypes).

There are two types of schemas:
- Target schemas, which “associate each time series with its source entity (or monitored entity), which is, for example, the process or the VM that generates the time series.” Importantly, target schemas can be used to decide which zone to store data in (as storing data near where it is generated limits network usage).
- Metric schemas, which store metrics metadata and other typed data (int64, boolean, double, string) in a structured format.
Schemas have two types of columns: key columns and value columns. The former is used to query/filter data, while the latter is used for analysis.
Query Language
The Monarch query language allows a user to fetch, filter, and process metrics data in a SQL-like language.

The example query above uses fetch to get the data, filter to include matching metrics, join to combine two streams of metrics, and group_by to perform an aggregation on the metrics:
[These] operations … are a subset of the available operations, which also include the ability to choose the top n time series according to a value expression, aggregate values across time as well as across different time series, remap schemas and modify key and value columns, union input tables, and compute time series values with arbitrary expressions such as extracting percentiles from distribution values.
Metric Collection
External services push metrics to leaf nodes by using “routers”, of which there are two types:
- Ingestion Routers receive requests at the global level, and determine which zone or zones the incoming data needs to be stored in. Metrics are routed for storage in a zone based on several factors, like the origin of the dataStoring the data close to its origin limits network traffic. .
- Leaf Routers receive requests from Ingestion Routers and handle communication with the leaves in a zone.
Metrics are assigned to a destination set of leafs within a zone using a component called the Range Assigner. The Range Assigner handles load balancing metrics data across leaves in order to ensure balanced usage of storage and other resources.
Query Execution
To respond to queries, Monarch implements two main components: Mixers and Index Servers. Copies of these components run at both the Global and Zone level.
Mixers receive queries, and issue requests to the different components of the Monarch stack, and return the results. Root Mixers run in the global component of Monarch, while Zone Mixers run in each zone. When Root Mixers receive a query, they attempt to break it down into subqueries that can be issued independently to each zone. When a Zone Mixer receives a request, it performs a similar function, fanning out to leaves.
In order to determine which zones or leaves to send queries to, the Mixer communicates with an Index Server. Like Mixers, Index Servers run at the global and zone level - Root Index Servers store which zone data can be found in, while Zone Index Servers store which leaves data can be found on.
Monarch implements several strategies to improve the reliability of query execution. One example is Zone Pruning, where the global Monarch query executor will stop sending requests to a zone if it is unhealthy (detected by network latency to the given zone). Another example strategy for improving reliability is hedged reads. For redundancy, Monarch stores multiple copies of a metric in a zone. As a result, the Zone Mixer can issue multiple reads to different copies, returning when it has an acceptable result from one replica.
Configuration
To configure Monarch, users interact with a global component that stores data in SpannerSpanner will have to be the subject of a future paper review! . This configuration is then replicated to each zone.
Configuration controls the schemas discussed above, as well as standing queries that run periodically in the background. Standing queries are often used for implementing alerting based on executions at regular intervals. The paper notes that predominantly all queries in the system are of this type.
How is the research evaluated?
The paper evalutes several parts of the system, including its scale and query performance.
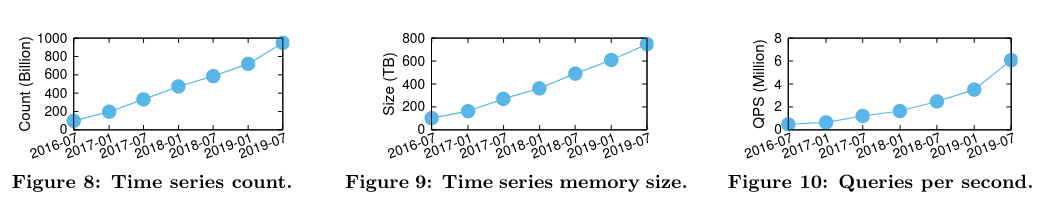
Monarch’s scale is measured by the number of time series it stores, the memory they consume, and the queries per second:
[Monarch] has sustained fast growth since its inception and is still growing rapidly…As of July 2019, Monarch stored nearly 950 billion time series, consuming around 750TB memory with a highly-optimized data structure.
Notably, “Monarch’s internal deployment ingested around 2.2 terabytes of data per second in July 2019.”
When evaluating query performance, the paper notes that 95% of queries are standing queries, configured in advance by users. Standing queries are evaluated in parallel at the zone level, enabling significant amounts of data to be filtered out of the query before being returned in a response.
Conclusion
The Monarch paper is a unique example of a metrics database running at global scale. Along the way, the paper includes an interesting discussion of the tradeoffs it makes to increase availability at the cost of consistency.
Time-series databases, including those designed explicitly for metrics, are an active area of research, and I’m looking forward to seeing the development of open-source approaches targeted for similar scale, like Thanos and M3!