micahlerner.com
Faster and Cheaper Serverless Computing on Harvested Resources
Published November 30, 2021
Found something wrong? Submit a pull request!
The papers over the next few weeks will be from SOSP. As always, feel free to reach out on Twitter with feedback or suggestions about papers to read! These paper reviews can be delivered weekly to your inbox, or you can subscribe to the Atom feed.
Faster and Cheaper Serverless Computing on Harvested Resources
This week’s paper review is “Faster and Cheaper Serverless Computing on Harvested Resources” and builds on the research group’s previous workIncluding Providing SLOs for Resource-Harvesting VMs in Cloud Platforms and Serverless in the Wild: Characterizing and Optimizing the Serverless Workload at a Large Cloud Provider. into Harvest Virtual Machines (aka Harvest VMs). The paper shows that this new way of structuring VMs is well suited for serverless workloads, significantly lowering cost and allowing 3x to 10x more resources for the same budget.
Harvest VMs are similar to relatively cheapSpot resources are generally cheaper than “reserved” resources as spot VMs can be interrupted, while reserved resources can not - in other words, users of cloud providers pay a premium for the predictability of their resources. The paper notes that on Azure, “Spot VMs are 48% to 88% cheaper than the same size regular VMs”. “spot” resources available from many cloud providers, with one key difference - Harvest VMs can grow and shrink dynamically (down to a set minimum and up to a maximum) according to the available resources in the host system, while spot resources can not.
While Harvest VMs pose great potential, using them poses its own challenges. For example, Harvest VMs are evicted from a machine if the Harvest VM’s minimum resources are needed by higher priority applications. Furthermore, dynamic resizing of Harvest VMs means that applications scheduled to run with the original resources may be constrained after a resize.
This paper in particular focuses on whether the Harvest VM paradigm can be used to efficiently and cheaply execute serverless workloads - an important contribution as the serverless paradigm is growing in popularity and more players (including Cloudflare) are entering the spaceSee Datadog’s State of Serverless, Vercel’s Series D, and What Serverless Computing Is and Should Become: The Next Phase of Cloud Computing. .
What are the paper’s contributions?
The paper makes four contributions: characterization of Harvest VMs and serverless workloads on Microsoft Azure using production traces, the design of a system for running serverless workloads on Harvest VMs, a concrete implementation of the design, and an evaluation of the system.
Characterization
The first part of the paper evaluates whether Harvest VMs and serverless workloads are compatible. Harvest VMs dynamically resize according to the available resources on the host machine. If resizing happens too frequently or the Harvest VM is evicted (because the minimum resources needed to maintain the VM are no longer available), that could impact the viability of using the technique for serverless workloads.
Characterizing Harvest VMs
First, the paper looks at two properties of the Harvest VMs:
- Eviction rate: evictions happen when the scheduling of higher priority VMs (like normal VMs) require that the Harvest VM shrink below its minimum resourcesHarvest VMs are configured with minimum and maximum resource bounds, where the maximum specifies the most cores/memory that the VM can consume. . If evictions occur often enough, it wouldn’t be possible for serverless functions to complete, meaning that the workload might be better suited for more expensive reserved resources where pre-emption is not possible.
- Resource variability: Harvest VMs grow and shrink according to the available resources on the host. If this variation happens too frequently, the Harvest VM may become resource constrained and unable to process work assigned to it in a timely manner - for example, if 32 cores worth of work is assigned, but the Harvest VM is shortly thereafter downsized to 16 cores, the machine may not be able to execute the assigned computation.
To understand eviction rate, the paper evaluates Harvest VM lifetime:
The average lifetime [of Harvest VMs] is 61.5 days, with more than 90% of Harvest VMs living longer than 1 day. More than 60% survive longer than 1 month.
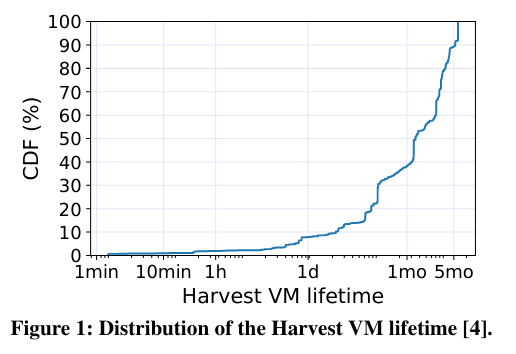
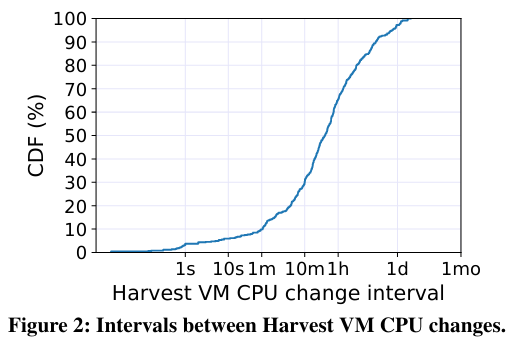
To understand resource variability, the paper determines the timing and magnitude of resizing events in Harvest VMs - in other words, how frequently and how large the resources swings are (specifically in CPU).
In the CDFCDF stands for Cumulative Distribution Function and is a handy way to visualize the distribution of data in a dataset - helpful reference video here. of intervals between Harvest VM CPU changes:
The expected interval is 17.8 hours, with around 70% of them being longer than 10 minutes, and around 35% longer than 1 hour. 62.2% of the studied Harvest VMs experienced at least one CPU shrinkage and 54.1% experienced at least one CPU expansion. 35.1% VMs never experienced any CPU changes.
When graphing the sizes of CPU change, the paper notes that:
The distribution tends to be symmetric with most of CPU changes falling within 20 CPUs. The average and maximum CPU change size are 12 and 30 for both shrinkage and expansion
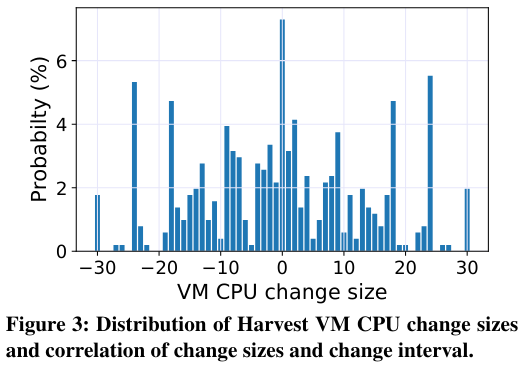
In summary, the Harvest VMs are actually relatively long-lived, and while resource variability does exist, there are not constant resizing events to Harvest VMs.
Characterizing Serverless Workloads
To evaluate whether serverless workloads are compatible with Harvest VMs, the authors reference the findings from the previous section’s characterization of eviction rates and resource variability. In particular, the paper focuses on the time required of serverless workloads. In each case, the paper focuses on a 30-second cut off, as Harvest VMs receive equivalent advance notice that they are about to be resized (and if a serverless finishes within that grace period, there are few repercussions).
First, the paper slices by application (of which there are many) in the production trace from Azure:
20.6% of the applications have at least one invocation (maximum) longer than 30 seconds. We refer to these applications as “long” applications. 16.7% and 12.3% of applications have 99.9𝑡ℎ and 99𝑡ℎ percentile durations longer than 30 seconds, respectively
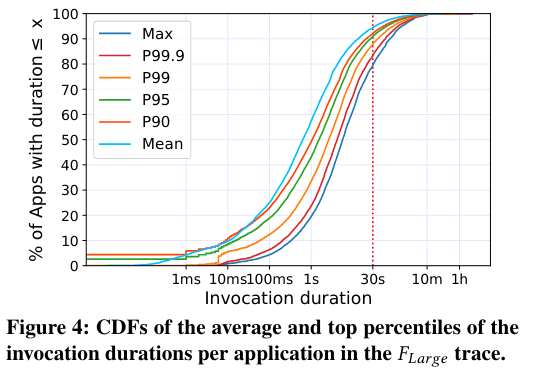
Another important point evaluated by the graphs is a distribution of the duration of all serverless invocationsInvocation is a fancy word for execution or call. , which indicates that there are few invocations that take over 30 seconds (around 4.1%), but these “long” invocations, “take over 82.0% of the total execution time of all invocations”. Furthermore, applications containing long invocations tend to be long themselves.
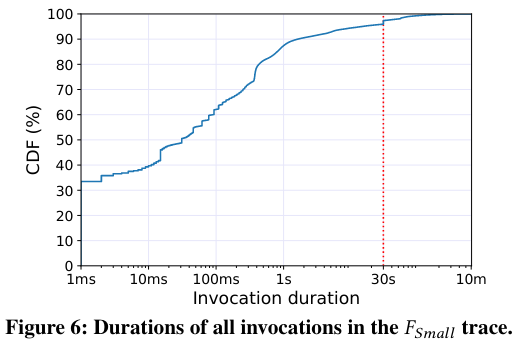
In summary, “Resource variation on Harvest VMs is much more common than evictions but compared to the short duration of most invocations, the number of CPUs of Harvest VMs can be considered relatively stable”.
Importantly, the paper notes the importance of a load balancer capable of accomodating resource changes to Harvest VMs - without the knowledge of a Harvest VM’s current resources, a scheduler might overload the given VM with too much work (for example, by assuming the VM has 32 cores when it really has 16).
Design
Based on characterization of Harvest VMs and serverless workloads, the authors note that any system for running serverless workloads on Harvest VMs must account for both “short” (faster than 30 second) and “long” applications, while handling evictions and resource variation. Furthermore, both short and long running serverless applications face the “cold start” problem of fetching dependencies before a serverless function can execute.
Handling evictions
To solve this set of problems, the paper proposes a load balancer that assigns serverless invocations to VMs using three strategies:
- No failures: assign invocations from long running applications to more costly reserved resources and those from short running applications to Harvest VMs.
- Bounded failures: assign invocations from both short and long running applications to Harvest VMs, targeting that no more than a given percentage of long-running applications are pre-emptedThis idea relies on Service Level Objectives (SLOs), a common way of evaluating the amount of accepted failures in large scale systems - see the SRE book for more information. .
- Live and let die: run all serverless applications on Harvest VMs, accepting that some number of them will fail due to eviction.
Each strategy trades off using Harvest VMs (and ultimately cost savings) for reliability. For example, the No failures strategy ensures high reliability, but at high cost (as reserved resources are more expensive than harvested ones).
Ultimately, the authors select Live and Let Die as it allows a serverless workload to be run entirely on Harvest VMs while achieving high reliability (99.99% invocation success rate). While it may be surprising that the decision to allow pre-emption operates with a low failure rate, the paper notes:
Intuitively, failures caused by VM evictions are rare because they require two low-probability events to happen simultaneously: a Harvest VM gets evicted while it is running a long invocation.
Handling Resource Variability
Resource variability causes unique problems for applications running on Harvest VMs. Serverless workloads in particular run into the “cold start” problem - when a serverless function runs on a machine for the first time, it needs to download associated dependencies and perform setup, which takes valuable time.
To minimize the impact of cold-starts on execution and to ensure serverless workloads are resilient to changing underlying resources, the paper proposes a load balancer that allocates work among Harvest VMs in the cluster.
The authors evaluate two load balancing algorithms to allocate work: Join-the-Shortest-Queue (JSQ) and Min-Worker-Set (MSQ).
Join-the-shortest-queue (JSQ) assign work to the least loaded Harvest VM in the cluster using an approximation of each machine’s current load.
Min-Worker-Set (MSQ) first tries to assign work to a Harvest VM where the given serverless function has run previously (to limit the impact of cold starts). If no worker has the resources to process the work, the algorithm expands the set of Harvest VMs that the serverless function can run on. The iterative growing process (keeping the total number of workers small) limits the number of Harvest VMs used by a function, as running work across many Harvest VMs increases the chances that one of them is evicted.
Implementation
To run serverless workloads on Harvest VMs, the paper outlines infrastructure that takes eviction and resource variability into account. The implementation is based on Apache OpenWhisk (which is compatible with a number of deployment strategies, including Kubernetes).
There are fourThere are also other, more generic parts of the architecture common to OpenWhisk, including the load balancer that receives requests to run serverless functions. main components of the implementation: Controllers, Invokers, Harvest Monitors, and a Resource Monitor.
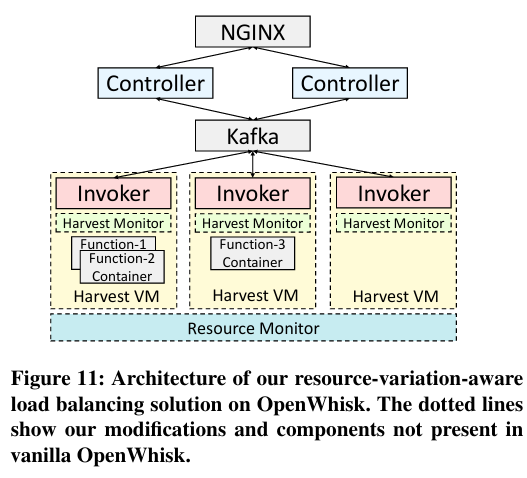
Controllers are provided by OpenWhiskHere is an overview of OpenWhisk building blocks. , and make scheduling decisions that assign serverless invocations to Harvest VMs - these scheduling decisions are written to a log that consumers can read from. The paper modifies the provided Controllers to implement the Min-Worker-Set (MSQ) algorithm. Additionally, Controllers receive feedback about function invocations, allowing the component to base their scheduling decisions off of perceived load on a Harvest VM.
Invokers handle the execution of the workload and consume the log of scheduling decisions written by the Controllers to receive information about the functions they should run - the Harvest VM implementation customizes the OpenWhisk Invoker to account for resource variability.
Harvest Monitors (a novel feature not provided by OpenWhisk) run on every Harvest VM and gather (then report to the Controllers) metadata about the associated VM - this metadata includes CPU allocations, CPU usage, and whether the Harvest VM is about to be evicted.
Lastly, the Resource Monitor tracks “the resource variation in the system. It periodically queries for the total available resources (e.g. CPUs) and spins up new VMs to maintain a minimum pool of available resources, if they fall below a pre-configured threshold”.
Evaluation
To evaluate the implementation, the paper considers whether the use of Harvest VMs results in faster and cheaper serverless computingBenchmarks rely on FunctionBench, which aims, “to measure performance of resources exclusively”. .
First, the paper runs workloads on Harvest VMs, load-balancing using the Join-the-shortest-queue (JSQ), Min-Worker-Set (MSQ) or “vanilla” OpenWhisk scheduling algorithm (which is unaware of the unique properties of Harvest VMs). The paper demonstrates that MSQ achieves high throughput and minimizes the cold start problem.
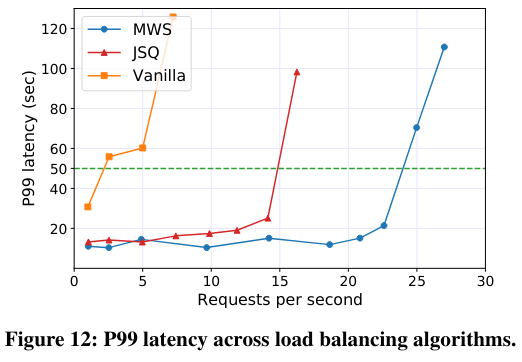
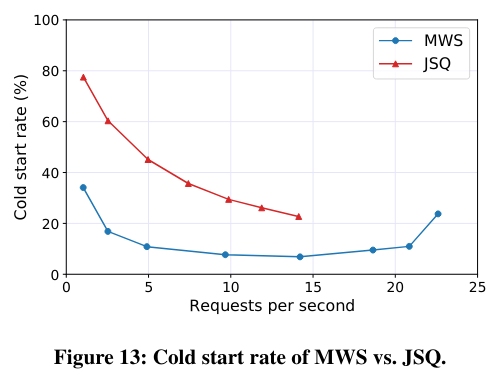
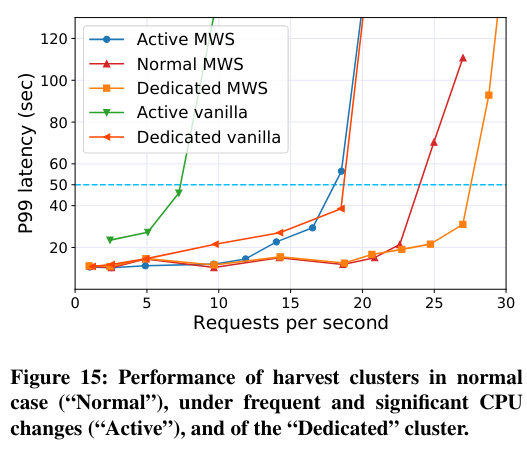
Next, the paper runs serverless workloads in clusters with three different resource churn patterns - active clusters representing the worst case Harvest VM resource variability, normal clusters with typical Harvest VM resource variability, and dedicated clusters using only regular VMs (and not Harvest VMs). Predictably, dedicated clusters are capable of executing the most requests per second. For active and normal clusters, the results show the continued impact of the load-balancing algorithm.
To address whether using harvested resources to execute serverless workloads is in fact cheaper, the paper presents a cost model that shows, for the same budget, the resources available under different eviction and Harvest VM percentages. The amount of additional resources affordable to a fixed budget varies from 3x to 10x.

Conclusion
This paper builds on several pieces of previous work that rely on making the tradeoff between cost and accepted failures - this idea also shows up in Site Reliability Engineering practice as Service Level Objectives. I also enjoyed how the authors relied on production traces and results to guide the design and verify the implementation.
As always, feel free to reach out on Twitter with feedback! Until next time.