micahlerner.com
FoundationDB: A Distributed Unbundled Transactional Key Value Store
Published June 12, 2021
Found something wrong? Submit a pull request!
Discussion on Hacker News
FoundationDB: A Distributed Unbundled Transactional Key Value Store Zhou, et al., 2021
I heard good things about FoundationDBIn particular, I read that FoundationDB passed Jepsen testing “with flying colors on their first try” and saw that there were many happy users of the system on Hacker News. , so after seeing that their paper was accepted to SIGMOD’21 (and made available), I decided to read it this week. As always, feel free to reach out on Twitter with feedback or suggestions about papers to read! These paper reviews can be delivered weekly to your inbox, or you can subscribe to the new Atom feed.
What is FoundationDB?
The paper discusses a distributed key value store that Apple, Snowflake, and VMWare (among others) run core services on at immense scaleApple’s CloudKit is built on FoundationDB, in addition to other services (as described in their SIGMOD’21 announcement). Snowflake’s usage of FoundationDB is explained in this great talk. . Unlike other large-scale data stores that forego implementing transactions in order to simplify scaling, FoundationDB was designed with strictly serializableStrict serializability means that transactions can be given a definite order. Achieving strict serializability is easy on a single node database, but is difficult to scale to an enormous distributed database (part of why the paper is so interesting). For background on the topic, I would recommend Peter Bailis’s blog. transactions from the ground up.
In the process of building the system, the team also wrote a testing framework for simulating faults in the network, disk, and other dependencies. This framework became powerful enough that it actually found bugs in software that FoundationDB relied on (like Zookeeper)!
What are the paper’s contributions?
The paper boils down to two major contributions.
- The FoundationDB system itself (including its feature set and overall architecture)
- The framework used to model and test the system
On its own, the FoundationDB system is a significant contribution. Its design contrasts with other large-scale storage systems aiming to service billions of users, store petabytes/exabytes of data, and respond to millions of requests per second - FoundationDB supports transactions by default. NoSQL (a common architecture used in large scale storage systems), normally do not include transactions by defaultThe paper does note that many NoSQL systems (like Cassandra, MongoDB, and CouchDB) did not have transactions until recently. , instead accepting writes that eventually propagate to the entire system (a.k.a. eventual consistency). In the eyes of the authors, systems that rely on eventual consistency force developers to think deeply about how their applications handle concurrent writes (given that with eventual consistency, readers and writers may not see updates to the database immediately).
The framework used to test the FoundationDB system is also novel. Code related to running the system can be stubbed out (more on stubbing out components in the What is unique about FoundationDB’s testing framework section?), allowing for engineers to control predominantly all sources of non-deterministic behavior. Being able to artificially induce many different types of failures means that an enormous amount of edge cases can be simulated. More edge cases simulated means more possible issues with those edge cases are found before being released.
Architecture of FoundationDB
To understand how FoundationDB works, the author’s invoke the design principle of “divide-and-conquer” - different components of the FoundationDB architecture are responsible for specific functionality and each function can be scaled separately. The impact of this design choice is that capacity can be gradually added to the components of the system that serve reads or writes, depending on changing usage patterns.
The divide-and-conquer principle is put into practice by splitting FoundationDB into two planes: the Control Plane and the Data Plane.
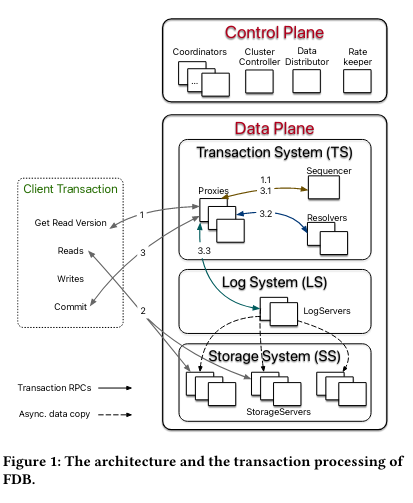
Control Plane
The Control Plane maintains critical metadata (like system configuration) and performs five independent functions: Coordinators, Cluster Controller, Data Distributor, and Rate Keeper.

The Coordinators store metadata about different components of the system so that a FoundationDB deployment can recover in the event of failures. As an example, one would run Coordinators across many different failure domains (for example, running in many regions or datacenters)The paper notes that “As long as a quorum (i.e., majority) of Coordinators are live, this metadata can be recovered.” . The Coordinators are part of an Active Disk PaxosActive Disk Paxos is an extension of Disk Paxos, and Disk Paxos is an extension of the basic Paxos algorithm. Disk Paxos is similar to the normal Paxos algorithm, except it can have multiple disks per processor, and a disk can be accessed by many processors. As an example, the Coordinators could use defined sections of a shared disk, rather than independent disks. Active Disk Paxos is different than Disk Paxos in that it can scale to infinite clients, while the original Disk Paxos implementation can not. The original paper on Disk Paxos is here and there is also an interesting description about it on Microsoft Research. Apparently a programmatic proof of the algorithm was developed and it found errors in the algorithm, but Lamport chose not to correct the original paper - with the note that “Anyone who writes a rigorous mechanically-checked proof will find them.” group, and elect a single Cluster Controller. If the Cluster Controller fails or becomes unresponsive, a new Cluster Controller will be elected.
The Cluster Controller has several key roles - it monitors all servers in the cluster, in addition to “recruiting” (a.k.a. starting) three key external processes. These three processes are in turn responsible for monitoring specific systems in FoundationDB. Two of the processes run in the Control Plane - the Data Distributor ensures optimal functioning of processes in the Data Plane’s Storage System, and the Rate Keeper ensures that the cluster as a whole isn’t overloadedAlthough how it ensures this is opaque and not covered in the paper . The third process run by the Cluster Controller is called the Sequencer, and it runs in the Data Plane. To understand the function of the Data Distributor and the Sequencer, let’s move onto the Data Plane.
Data Plane
In contrast to the Control Plane’s single subsystem, the Data Plane contains three: the Transaction System, the Log System, and the Storage System. We will first talk about the systems at a high level, then dive into how they work individually.
The Transaction System communicates with clients and is responsible for in-memory transaction processing in the event of a write transaction - in the event of a transaction commit, components in the Transaction System call into the Log System to persist mutations associated with the transaction.
The Log System stores persistent record of a transaction (through a Write Ahead Log), and communicates with the Storage System in order to replicate the Write Ahead Log.
The Storage System receives mutations from the Log System and applies the mutations to its storage. Clients also communicate directly with the Storage System when performing a read request.
Now that we understand the different systems in the Data Plane at a high level, let’s dive into the specifics of how each works.
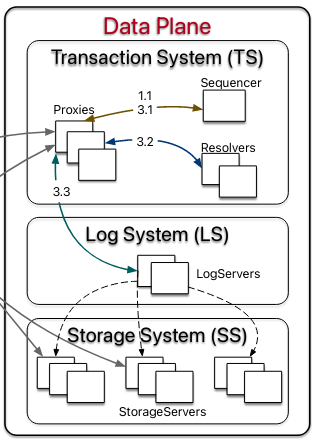
Transaction System
The primary functions of the Transaction System are to act as a router for read requests and decide whether to commit write transactions. It accomplishes these goals by using three stateless components: a Sequencer, Proxies, and Resolvers.
As mentioned in the Control Plane section, the Sequencer is recruited and monitored by the Cluster Controller. Once the process is running, it starts the other processes in the Transaction System. The Sequencer hands out information to the Proxies when the latter receive client requestsWe will delve into what state the Sequencer controls in the How does FoundationDB respond to requests? section. .
Proxies respond to client read and write requests. In the event of a read request for a set of keys from a client, the Proxies will respond with locations of the servers storing the requested information and a version that the client can use to request the data. In the event of a write request, the Proxies coordinate with the Sequencer and the third component in the Transaction System, the Resolvers.
Resolvers check whether a client transaction involving writes conflicts with other writes. Each Resolver is only responsible for preventing transaction conflicts on a subset of the keys in the key-value store.
Log System
The primary goal of the Log System is to ensure data about committed transactions is replicated once the Transaction System decides to commit. To perform this function, the Log System uses many instances of a single server type: the Log Server.
A Log Server can be configured to replicate mutations from a single transaction to many copies of the same shard (where a shard is a specific subset of the key-value store’s data and is stored in the Storage System). To replicate a mutation, Log Servers communicate with servers in the Storage System.
Storage System
Like the Log System, the Storage System also has a single server type: the Storage Server.
Each Storage Server can store many different shards of the key-value store’s data (normally multiple copies of the same exact shard are not stored on a single server), and each shard corresponds to a contiguous key rangeThe paper mentions that this results in functionality that is “like a distributed B-tree”. . The data on each StorageServer is stored in a souped-up version of SQLite, but there is an in-progress migration to RocksDB.
How does FoundationDB respond to requests?
Now that we understand the architecture of FoundationDB, we will dig into how client transactions work. There are three primary types of transactions in FoundationDB: read-write transactions (reads and writes associated with a single transaction), read-only transactions, and snapshot reads. Read-write transactions are by far the most complicated and are where we will devote most of our discussion.
Read-write transactions
If a client executes logic that writes data based on what it reads, it should likely use a read-write transaction. Reasons for using this style of transaction could be: ensuring that writes fail if the previously-read data is no longer correct, or to require an all-or-nothing approach to applying multiple writes (all writes need to commit or none of them commit).
In order to perform a read-write transaction, a client first requests a read version from a Proxy. The Proxy then turns around and requests two pieces of information from the Sequencer: a read version and a commit version (remember that both the Proxy and Sequencer are in the Transaction System) Before moving on, it is important to note an important property of the commit version: the commit version must be “greater than any existing read versions or commit versions”. We will come back to this property when we consider the write-path. . The Proxy internally associates a transaction’s read version with the commit version before returning the read version to the client. The client can then use the read version to fetch data at a specific version directly from the Storage Server.
Once the Proxy returns the read version to the client, the client will read keys from the Storage Servers and buffer writes until it wants to commit. When the client finally sends a commit request to the Proxy, it includes the set of all of the key ranges that the client read (while the client may have only read a specific key, that key is stored in a key range on a shard, and that shard could have been impacted by a different transaction) and the set of all key ranges that the client intends to write to.
Once the Proxy receives these two sets of impacted key ranges, it then needs to determine whether the transaction can be committed or not. This is accomplished by using Resolvers, which maintain state about when the key ranges they are responsible for were last impacted by a committed transaction. Because the Resolvers are each responsible for a subset of key ranges (remembering the description above), the Proxy forwards the sets to the appropriate Resolver, which evaluates whether the transaction can be committed.
When a Resolver receives these requests from the Proxy it uses a relatively straightforward algorithm to determine whether the transaction can be committed - for every key range that was read by the transaction, was the key range committed to by a transaction with a greater commit version. If the last commit for a key range is greater than the current read version, committing would break strict serializability, which mandates that “transactions must observe the results of all previous committed transactions”. In this situation, the client should retry their transaction. On the other hand, if it is safe to commit, the Resolver does so, meanwhile updating its “last committed to” field for all ranges that the transaction wrote to.
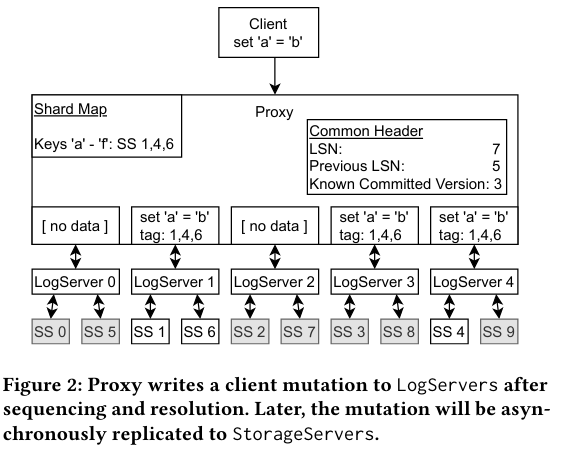
Once a commit has been accepted, the Proxy broadcasts a message to all LogServers - the message contains the key ranges that were impacted by the commit. When a LogServer receives this message, it stores it on disk (to ensure recovery in case of system failure) and determines whether it manages replicas of any of the impacted key ranges. Meanwhile, Storage Servers are continuously polling Log Servers for updates, and will pull (then persist) the update themselves.
Read-only transactions and snapshot reads
Read-only transactions and snapshot reads are relatively straightforward in FoundationDB - when a client initiates a read request, the Proxy returns a read version (through the same process of interacting with the Sequencer, as mentioned above). The client the communicates directly with the Storage Servers associated with the key ranges that the client wants to read. The simplicity of this approach is great because the load on the database is dominated by reads.
What is unique about FoundationDB’s testing framework?
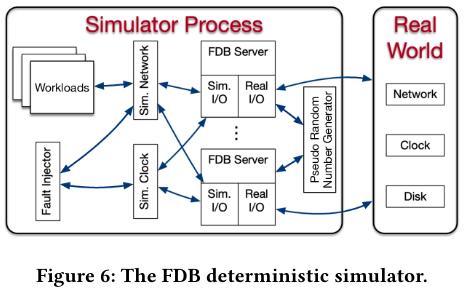
Now that we have walked through the many components involved in FoundationDB transactions, it may be easier to see how many places in the system that a failure could happen. To root out potential issues caused by failures, the team developed a simulation testing framework where “all sources of nondeterminism and communication are abstracted, including network, disk, time, and pseudo random number generator.” In production, these stubs are just sent to the backing system calls - pretty neat! The testing framework also reminded me of fuzzing software to trigger rarely-hit edge cases and see what happens.
When running test workloads, failures at the “machine, rack, and data-center” are simulated. Modeled hardware will be “broken”, then returned to a state where the system should be able to recover (and if a recovery doesn’t happen, the developers investigate why). The simulation code can also arbitrarily break operations by returning error codes, adding delay, or modifying configuration variables beyond a range of what would normally be set.
Part of what I found most interesting about the testing framework was the idea that the simulations can be “bursted” around releases - because many simulations can be run in parallel, the developers will just run more of them and try to find bugs.
Conclusion
Given that this paper review is already fairly long, I decided not to cover other interesting aspects of the system (for example FoundationDB’s approach to system recovery, replication, or failovers).
The takeways from what this review does cover are:
- FoundationDB separates different parts of the system so that they can be scaled independently
- Creating separate subsystems that can scale independently is difficult, but facilitated by a novel simulation testing framework that allows the developer team to confidently rework the system (not to mention making users of the system confident that bugs will be caught before they reach production).
Until next week!