micahlerner.com
Understanding Raft - Part 2 (Raft leaders, logs, and safety)
Published May 09, 2020
Found something wrong? Submit a pull request!
Discussion on Hacker News
This post is a continuation in the series I wrote about Raft, the first part of which is here. This post focuses on what underlies leader election, log replication, and Raft safety. Enjoy!
Leaders and leader election
The Raft protocol requires a single node (called the Leader) to direct other nodes on how they should change their respective states of the world. There can only be one leader at a time - Raft maintains a representation of time called a term. This term only changes in special situations, like when a node attempts to become a Leader.
When a Raft cluster starts, there are no leaders and one needs to be chosen through a process called Leader Election before the cluster can start responding to requests.
How does the leader election process work?
A node starts the leader election process by designating itself to be a Candidate, incrementing its term, voting for itself, and requesting the votes of other nodes in the Raft cluster using RequestVote.
There are a few ways that a node can exit Candidate state:
- If the
Candidatenode receives a majority of votes within some configurable time period of the election starting, it becomes the leader. - If the
Candidatenode doesn’t receive a majority of votes within some configurable time period of the election starting (and it hasn’t heard from another leader, as in the case below), the node restarts the election (including incrementing its term and and sending outRequestVotecommunications again). - If the
Candidate(Node A) hears from a different peer (Node B) who claims to beLeaderfor a term greater than or equal to the term that Node A is on, Node A stops its election, sets its term to Node B’s, enters theFollowerstate, and begins listening for updates from theLeader.
Once a node becomes a Leader, it begins sending communications in the form of AppendEntries (discussed more in the next section) messages to all other peers, and will continue trying to do so unless it hears about a different Leader with a higher term (you may be wondering how Raft ensures that a Leader with an out of date state of the world doesn’t somehow acquire a higher term, but that topic is covered in the Safety section).
To allow Raft to recover from a Leader failing (maybe because of an ethernet unplugging scenario), an up to date Follower can kick off an election.
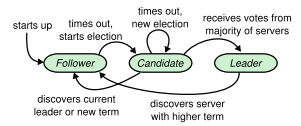
Raft States
I found the visualization in the margin (from the original Raft paper) to be helpful for thinking about the ways that a node can transition between the three possible states of Follower, Candidate, and Leader.
Raft logs and replication
What is an AppendEntries request and what information does it contain?
As mentioned above, Leader nodes periodically send AppendEntries messages to Follower nodes to let the Followers know that there is still an active Leader.
These AppendEntries calls also serve the purpose of helping to update out of date Followers with correct data to store in their logs.
The information that the leader supplies in the calls is as follows:
- The
Leader'scurrent term - as mentioned in the Leaders and leader election section, if a node is aCandidateor aLeader, hearing about a new or existing leader might require the node to take some action (like giving up on an election or stepping down as a Leader). -
Log entries (represented as an array) that the Leader wants to propagate to peers, along with data about the
Leader'slog that will help theFollowermake a decision about what to do with the new entries. In particular, theLeadersends data about the log entry that immediately preceded the entries it is sending. Because the data pertains to the previous log entry, the names of the variables are previousLogIndex and previousLogTerm.
Leader log For an example of how these variables are assigned, consider a Leader’s log as shown in the margin. If the leader wanted to update the follower with entries that are in positions 9 through 10, it would include those in the log entries section of theAppendEntriescall, setting previousLogIndex to 8 and previousLogTerm to 6. - The
Leader'scommitIndex: this is where the idea of committing from the earlier part of this guide comes into play.
What happens when a peer receives an AppendEntries request?
Once a peer receives an AppendEntries request from a leader, it evaluates whether it will need to update its state, then responds with its current term as well as whether it successfully processed the request:
- If the receiving node has a greater term than the sending node, the receiving node ignores the
AppendEntriesrequest and immediately communicates to the sending node that the request failed. This has the effect of causing the sending node to step down as a leader. A situation where this could arise is when aLeaderis disconnected from the network, a new election succeeds (with a new term and Leader), then the old Leader is reconnected. Because Raft only allows one leader at a time, the old one should step down. - If the receiving node has an equal term as the sending node, a few conditions need to be evaluated:
Firstly, if the receiving node is not a
Follower, it should immediately transition to being one. This behavior serves to notify candidates for the term that aLeaderhas been elected, as well as guarding against the existence of twoLeaders. Hitting this condition does not cause theAppendEntriesrequest to return.- Once it has been checked that the receiving and sending nodes have the same term, we need to make sure that their logs match. This check is performed by looking at the previousLogIndex and previousLogTerm of the sending node and comparing to the receiving node’s log.
As part of performing this check, a few scenarios arise.
- In the match case, the previousLogIndex and previousLogTerm of the sending node match the entry in the receiving node’s log, meaning that everything is up to date! If this is true, the receiving node can add the received entries to its log. The receiving node also checks whether the
Leaderhas a newer commit index (meaning that the receiving node is able to update its commit index and apply messages that will affect its state) - If the log for a
Followeris not up to date, the Leader will keep decrementing the previousLogIndex for theFollowerand keep retrying the request until the logs match (the match case above is true) or it has been determined that all entries in theFollowerneed to be replace
- In the match case, the previousLogIndex and previousLogTerm of the sending node match the entry in the receiving node’s log, meaning that everything is up to date! If this is true, the receiving node can add the received entries to its log. The receiving node also checks whether the
- Once it has been checked that the receiving and sending nodes have the same term, we need to make sure that their logs match. This check is performed by looking at the previousLogIndex and previousLogTerm of the sending node and comparing to the receiving node’s log.
As part of performing this check, a few scenarios arise.
Raft Safety
At the core of Raft are guarantees about safety that make sure that data in the log isn’t corrupted or lost. For example, imagine that a Leader starts coordinating changes to the log, does so successfully, then goes offline. While the existing Leader is offline, a new Leader is elected and the system continues updating the log. If the old Leader were to come back online, how can we make sure that it isn’t able to rewind the system’s log?
To account for this situation (and all of the edge cases that can occur in distributed systems), Raft aims to implement several ideas around Safety. A few of these we’ve already touched on (descriptions are from Figure 3 of the original Raft paper):
- Election Safety: “There can at most be one leader at a time.” Discussed in Leaders and leader election.
- Leader Append-Only: “a leader never overwrites or deletes entries in its log; it only appends new entries.” The leader never mutates it’s internal logs. Discussed in Raft logs and replication.
- Log Matching: “if two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index.” If the leader doesn’t have logs that match followers, the leader will rewind the follower’s log entries, then send over the correct data. Discussed in Raft logs and replication.
The other important ideas around Raft Safety are:
- Leader Completeness: “if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms”. The gist of this principle is to ensure that a leader has all log entries that should be stored permanently (committed) by the system. To make the idea of Leader Completeness concrete, imagine a situation where a key-value store performs a put and then a delete - if the put operation was replicated, but the delete happened in a higher term and is not in the log of the leader, the state of the world will be incorrect, as the delete will not be processed. To ensure that leaders aren’t elected with stale logs, a node that receives a
RequestVotemust check that the sender has a log where the last entry is of a greater term or of the same term and of a higher index. If the receiver determines that neither of those conditions is true, then it rejects the request. - State Machine Safety: “if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index.” The gist of this principle is to ensure that a leader applies entries from its log in the correct order. To make the idea of State Machine Safety concrete, imagine a situation where a key-value store performs a put and then a delete (both of which are stored in individual log entries). If the put operation was applied, then the delete operation was applied, every other node must perform the same sequence of applications. A more detailed explanation of the proof is available in the Raft paper.
Conclusion
If you’ve made it to the end, thanks for following along and until next time!